[WEEK02] 회고
DAY01 피어세션
import torch
a = torch.tensor([2., 3.], requires_grad=True)
b = torch.tensor([6., 4.], requires_grad=True)
Q = 3*a**3 - b**2
external_grad = torch.tensor([1., 1.])
Q.backward(gradient=external_grad)
gradient 인자는 편미분 결과값을 제어하는 역할이다.
위와 같이 미분할 변수가 2개인 경우에 gradient 인자값도 2개를 넣어주어야 한다.
DAY02 피어세션
- 입력 데이터를 Tensor 자료형으로 만들어주는 function

- 입력 데이터를 새로운 메모리 공간으로 copy하여 사용
- int 값 입력 시 int로 사용
- tensor형 데이터를 담고 있는 자료구조 Class를 의미
- 입력데이터 뿐만 아니라 shape을 입력하면 tensor을 만들 수 있다.

- int 값 입력 시 float으로 변환하여 사용
def __init__(self) -> None:
"""
Initializes internal Module state, shared by both nn.Module and ScriptModule.
"""
torch._C._log_api_usage_once("python.nn_module")
self.training = True
self._parameters: Dict[str, Optional[Parameter]] = OrderedDict()
self._buffers: Dict[str, Optional[Tensor]] = OrderedDict()
self._non_persistent_buffers_set: Set[str] = set()
self._backward_hooks: Dict[int, Callable] = OrderedDict()
self._is_full_backward_hook = None
self._forward_hooks: Dict[int, Callable] = OrderedDict()
self._forward_pre_hooks: Dict[int, Callable] = OrderedDict()
self._state_dict_hooks: Dict[int, Callable] = OrderedDict()
self._load_state_dict_pre_hooks: Dict[int, Callable] = OrderedDict()
self._load_state_dict_post_hooks: Dict[int, Callable] = OrderedDict()
self._modules: Dict[str, Optional['Module']] = OrderedDict()nn.Module을 extend함으로써 custom model 이나 custom layer는 위와 같은 여러 속성들 또한 상속받게 된다.
위와 같은 속성들은 parameter, modules 등의 네트워크 학습에 있어서 중요한 특성을 포함한다.
따라서 파이토치에서 제공하는 layer를 사용하여 모델 빌드를 간편하게 하기 위해서는 위와 같이 nn.Module을 상속받고, 이를 initialize 함으로써 nn.Module에서 상속받는 특성들을 initialize해주는 것이 필요하다.
Q. 상속받을 때, super().__init__()을 선언 해주는 이유는?
import torch
from torch import nn
class Add(nn.Module):
def __init__(self):
super().__init__()
def forward(self, x1, x2):
output = torch.add(x1, x2)
return output
x1 = torch.tensor([1])
x2 = torch.tensor([2])
add = Add()
output = add(x1, x2)nn.Module을 상속받은 클래스는 forward()함수를 호출하지 않아도 add 객체에 파라미터로 전달하면 바로 forward method가 실행된다.
아래와 같이 실행을 해주어야 하기 때문에 nn.Module을 상속받아야 하고
super()로 부모 클래스를 초기화해줌으로써 부모클래스의 속성을 subclass가 받아오도록 하는 것이다.
초기화를 하지 않으면 부모 클래스 속성을 사용할 수 없다.
DAY03 피어세션
- backward 함수는 autograd 를 사용하여 자동으로 정의되기 때문이다.
- nn.Parameter 라는 객체를 통해 __init__ 안에서 backward할 파라미터를 정의해주기만 하면 된다.
'PyTorch에서는 모델을 저장할 때 .pt 또는 .pth 확장자를 사용하는 것이 일반적인 규칙입니다.'
→ 근데 파이토치에서도 h5로 저장하고 불러오는게 되긴 함
DAY04 피어세션
- 가중치 초기화는 딥러닝 학습의 어려움을 극복하기 위한 방법 중 하나
- 어떤 initial값에서 출발하느냐에 따라 local minumum에 수렴하게 될지 global minmum에 수렴하게 될지 결정되기 때문에 아무리 좋은 optimizer를 사용해도 초기값을 잘못 설정하면 global minimum에 수렴하기 어렵다.
- gradient vanishing/exploding을 방지할 수 있다.
- model을 재현할 때 동일한 성능을 내기 위해서(seed를 설정한다고 볼 수 있다.)
Q. 왜 Weight를 0으로 initalization 하지 않을까?
가중치가 0으로 초기화되어있다면 learning rate는 가중치 벡터의 방향이 아니라 크기에만 영향을 미치므로 학습이 제대로 일어나지 않는다.
또한 신경망 노드의 파라미터 값이 0이 아니더라도 모두 같아도 안된다.
신경망 노드의 파라미터가 모두 동일하다면 여러 개의 노드로 신경망을 구성하는 의미가 사라진다.
결과적으로 층마다 한 개의 노드만을 배치하는 것과 같기 때문이다. 따라서 Weight의 초기값을 0으로 설정해서는 안된다.
- 정규분포$N(0,1)$를 이루는 값을 각 가중치에 Random Initialization하고 Activation function은 Sigmoid를 사용
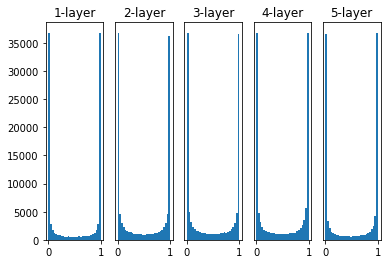
위 그래프는 Sigmoid까지 거친 결과값을 나타낸 것이다. 0과 1에 치우쳐 분포되어 있음을 확인할 수 있다.
활성화 값이 0과 1에 가까울 때 미분값은 거의 0에 가깝기 때문에 backpropagation 시 gradient vanishing 문제가 발생한다.
▮ Xavier Initalization
Xavier Initialization은 고정된 표준편차 대신 표준편차를 이전 은닉층의 노드 수에 맞추어 변화시킨다.
층마다 노드 개수를 다르게 설정하더라도 이에 맞게 가중치가 초기화되기 때문에 고정된 표준편차를 사용하는 것보다 훨씬 더 강건(Robust)하다고 한다.
- Xavier normal Initialization

이전 은닉층의 노드의 개수가 n개이고 현재 은닉층의 노드의 개수가 m개 일 때 $\frac{2}{ \sqrt{n+m} }$를 표준편차로 하는 정규분포로 가중치를 초기화한다.

- Xavier uniform Initalization

▮ He Initalization
Xavier Initalization은 활성화 함수가 Sigmoid나 tanh일 때는 괜찮지만 ReLU 함수를 사용할 때는 출력 값이 0으로 수렴하게 되는 현상이 발생한다.

ReLU함수를 activation function으로 사용할 때는 He Initalization으로 가중치를 초기화해주면 위 문제를 해결할 수 있다.
- He normal Initialization

- He uniform Initalization

Xavier 식에서 현재 은닉칭의 node의 개수를 제거한 형태이다.
DAY05 피어세션
팀적으로 의논한 사항
- 앞으로 9시 반에 코딩테스트(프로그래머스 lv2) 코드 리뷰하는날 (당일 모더레이터 담당)
오후 7시 전까지 다음날 풀 코테문제 선정해서 올리기(당일 모더레이터가 선정) - 모두의 말뭉치 대회 꾸준히 하면서 매일 작업한 것 이야기하기
- 아무때나 공부할 때 Zoom으로 참여하기(자율)
이전까지는 그냥 단순히 잘 학습된 모델을 가져다 쓰기만 했는데 내 실력이 많이 부족하다는 것도 다시 한번 깨닫고 좀 더 세부적으로 배울 수 있어서 좋았다.
WandB도 처음 알았는데 진짜 좋아보인다.
알약 프로젝트도 처음에는 노트북환경이 아니라 모듈로 만들어서 학습을 해보려고했는데 어떻게 파일 구조를 잡아야하는지 모르겠고 어려워서 그냥 노트북환경으로 회귀했었는데 템플릿을 만들고서 적용해봐야겠다.
WandB도!