[PyTorch] 17. Custom Model
인덱싱
▮ torch.index_select
torch.index_select(input, dim, index, out=None) → Tensor
- input (Tensor) – the input tensor.
- dim (int) – the dimension in which we index
- index (IntTensor or LongTensor) – the 1-D tensor containing the indices to index
>>> x = torch.randn(3, 4)
>>> x
tensor([[ 0.1427, 0.0231, -0.5414, -1.0009],
[-0.4664, 0.2647, -0.1228, -1.1068],
[-1.1734, -0.6571, 0.7230, -0.6004]])
>>> indices = torch.tensor([0, 2])
>>> torch.index_select(x, 0, indices)
tensor([[ 0.1427, 0.0231, -0.5414, -1.0009],
[-1.1734, -0.6571, 0.7230, -0.6004]])
>>> torch.index_select(x, 1, indices)
tensor([[ 0.1427, -0.5414],
[-0.4664, -0.1228],
[-1.1734, 0.7230]])
▮ torch.gather
주어진 차원과 인덱스에 맞는 input의 원소들을 모아 리턴
torch.gather(input, dim, index) → Tensor- input (Tensor) – the source tensor
- dim (int) – the axis along which to index
- index (LongTensor) – the indices of elements to gather
🔥 input and index 는 같은 수의 dimensions을 가져야 한다. 🔥
🔥 출력값은 index 와 같은 shape을 갖는다.🔥
>>> A = torch.Tensor([[1,2,3],[4,5,6],[7,8,9]])
>>> index = torch.tensor([[0,0],[1,0]])
>>> B = torch.gather(A, 0, index)
tensor([[1., 2.],
[4., 2.]])
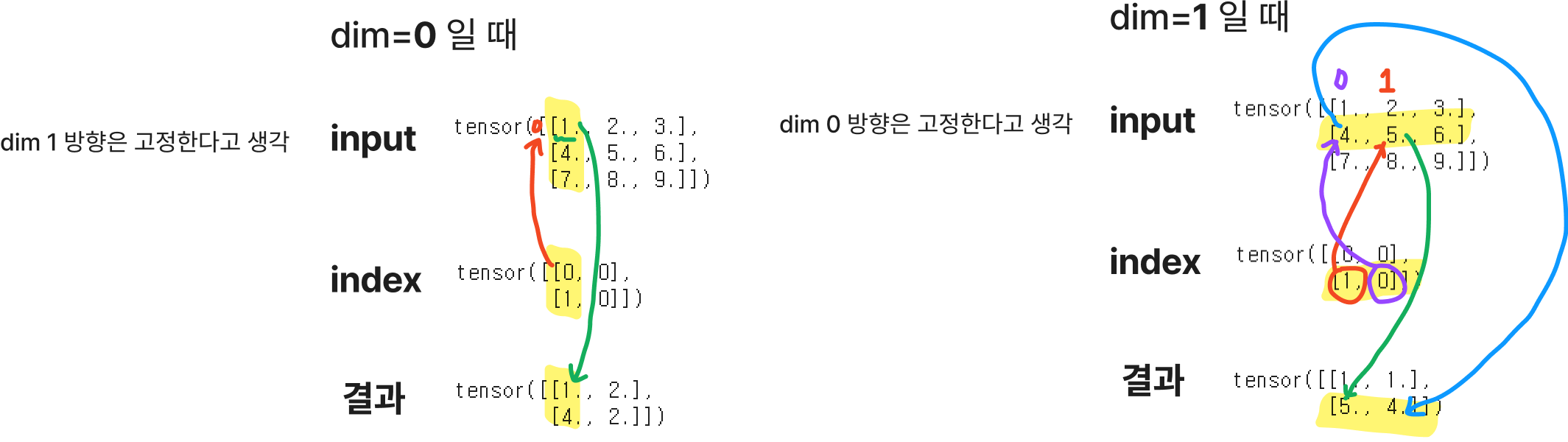
# 3-D tensor일 경우
out[i][j][k] = input[index[i][j][k]][j][k] # if dim == 0
out[i][j][k] = input[i][index[i][j][k]][k] # if dim == 1
out[i][j][k] = input[i][j][index[i][j][k]] # if dim == 2
▮ nn.Module
- torch.nn.Module 은 PyTorch의 모든 Neural Network의 Base Class이다.
nn.Module을 상속받으면 파이토치 프레임워크에 있는 각종 도구를 쉽게 적용할 수 있다.
모듈은 다른 모듈을 포함할 수 있고, 트리 구조로 형성할 수 있다.
forward() 함수를 호출하지 않았는데 add 객체에 파라미터로 전달하면 바로 forward method가 실행된다.
이는 nn.Module을 상속받은 클래스의 특징이다.
▮ nn.Parameter
- Tensor 객체의 상속 객체로, nn.Module 내에 attribute가 될 때는 required_grad=True로 지정되어 AutoGrad의 대상이 된다.(학습대상 Tensor)
class CustomLinearModel(nn.Module):
def __init__(self, in_features, out_features, bias=True):
super().__init__()
self.in_features = in_features
self.out_features = out_features
self.weights = nn.Parameter(torch.randn(in_features, out_features))
self.bias = nn.Parameter(torch.randn(out_features))
def forward(self, x: Tensor):
return x @ self.weights + self.bias그러나 Custom 모델을 만들때 대부분 torch.nn에 구현된 layer들을가져가다 사용하기 때문에 Parameter를 직접 다뤄볼 일은 매우 드물다.
▮ register_buffer(name, tensor, persistent=True)
하지만 Parameter로 지정하지 않아서 값이 업데이트 되지 않는다 해도 저장하고싶은 tensor가 있을 경우에는
→ buffer에 tensor를 등록해주면 된다.
import torch
from torch import nn
from torch.nn.parameter import Parameter
class Model(nn.Module):
def __init__(self):
super().__init__()
self.parameter = Parameter(torch.Tensor([7]))
self.tensor = torch.Tensor([7])
# torch.Tensor([7])를 buffer이라는 이름으로 buffer에 등록
self.register_buffer('buffer', self.tensor)
model = Model()
buffer = model.get_buffer('buffer') # 7
▮ hook
custom 코드를 중간에 실행시킬 수 있도록 만들어놓은 인터페이스이다.
Pytorch에는 forward와 backward시에 호출하는 hook들이 있다.
Tensor에는 backward hook만 사용이 가능하고 Module에는 둘 다 가능하다.
nn.Module 상속 하는 모델을 만들고 model.__dict__를 하면 module의 정보를 볼 수 있는데 hook에 관한 정보도 있다.
{'training': True,
'_parameters': OrderedDict(),
'_buffers': OrderedDict(),
'_non_persistent_buffers_set': set(),
'_backward_hooks': OrderedDict([(3, <function __main__.module_hook(grad)>)]),
'_is_full_backward_hook': True,
'_forward_hooks': OrderedDict([(2, <function __main__.module_hook(grad)>)]),
'_forward_pre_hooks': OrderedDict([(1,
<function __main__.module_hook(grad)>)]),
'_state_dict_hooks': OrderedDict(),
'_load_state_dict_pre_hooks': OrderedDict(),
'_load_state_dict_post_hooks': OrderedDict(),
'_modules': OrderedDict()}
PyTorch에서 지원하는 hook
- model.register_forward_pre_hook(module_hook)
- model.register_forward_hook(module_hook)
- model.register_full_backward_hook(module_hook)
return이 있다면 해당 return을 본래 객체에 적용한다.
return이 없다면 기존 객체의 동작대로 동작한다.
▮ Module
Module(의 forward 연산)을 기준으로, input, output gradient를 가져올 때 사용한다.
실행시점에 따라 hook이 3가지가 있다.
- register_forward_pre_hook
def pre_hook(module, input): pass
- register_forward_hook
def hook(module, input, output): pass
- register_full_backward_hook
def module_hook(module, grad_input, grad_output):
pass
Module - forward hook ex)
import torch
from torch import nn
class Add(nn.Module):
def __init__(self):
super().__init__()
def forward(self, x1, x2):
output = torch.add(x1, x2)
return output
# 모델 생성
add = Add()
answer = []
# pre_hook를 이용해서 x1, x2 값을 answer에 저장
def pre_hook(module, input):
answer.append(input[0])
answer.append(input[1])
# hook를 이용해서 output 값을 answer에 저장
def hook(module, input, output):
answer.append(output)
add.register_forward_pre_hook(pre_hook)
add.register_forward_hook(hook)
x1 = torch.rand(1)
x2 = torch.rand(1)
output = add(x1, x2)
# answer : [tensor([0.8748]), tensor([0.1993]), tensor([1.0741])]
Module - backward hook ex)
import torch
from torch import nn
from torch.nn.parameter import Parameter
class Model(nn.Module):
def __init__(self):
super().__init__()
self.W = Parameter(torch.Tensor([5]))
def forward(self, x1, x2):
output = x1 * x2
output = output * self.W
return output
model = Model()
# x1.grad, x2.grad, output.grad를 순서대로 list에 넣고자함
answer = []
# hook를 이용해서 x1.grad, x2.grad, output.grad 값을 알아내 answer에 저장
def module_hook(module, grad_input, grad_output):
# grad_input = W값과 x1*x2값
answer.append(grad_input[0]*x2)
answer.append(grad_input[0]*x1)
answer.append(grad_output[0])
model.register_backward_hook(module_hook)
x1 = torch.rand(1, requires_grad=True) # requires_grad: True로 설정 시 모든 연산들을 기억(track all operation)
x2 = torch.rand(1, requires_grad=True)
output = model(x1, x2)
output.retain_grad() # retain_grad(): 해당 변수에 대한 gradient 연산을 기억 -> 이것을 하지 않으면 중간 변수에 대한 gradient는 저장 안됨
output.backward() # backward(): 기억한 연산들에 대해서 gradient 계산 -> grad attribute(속성)에 gradient 정보 축적
▮ Tensor - backward hook
Module 단위의 backward hook은 module을 기준으로 input, output gradient 값만 가져와서 module 내부의 tensor의 gradient값은 알아낼 수 없다.
따라서 모델 파라미터의 gradient에 직접 접근할 때 모델의 parameter의 gradient에 접근하려고 할 때 사용한다.
model.[layer].[nn.Parameter].register_hook()
import torch
from torch import nn
from torch.nn.parameter import Parameter
class Model(nn.Module):
def __init__(self):
super().__init__()
self.W = Parameter(torch.Tensor([5]))
def forward(self, x1, x2):
output = x1 * x2
output = output * self.W
return output
# 모델 생성
model = Model()
# Model의 Parameter W의 gradient 값을 저장
answer = []
# hook를 이용해서 W의 gradient 값을 answer에 저장하세요
def tensor_hook(grad):
answer.append(grad)
model.W.register_hook(tensor_hook)
x1 = torch.rand(1, requires_grad=True)
x2 = torch.rand(1, requires_grad=True)
output = model(x1, x2)
output.backward()
hook을 사용하는 예시
- 디버깅(레이어의 shape, output등을 출력할 때)
- feature extraction
- gradient clipping
- visualization
부스트캠프 AI Tech 교육 자료를 참고하였습니다.