부스트캠프 AI Tech 4기
[WEEK04] 회고
StoneSeller
2022. 10. 13. 03:15
[Day03]
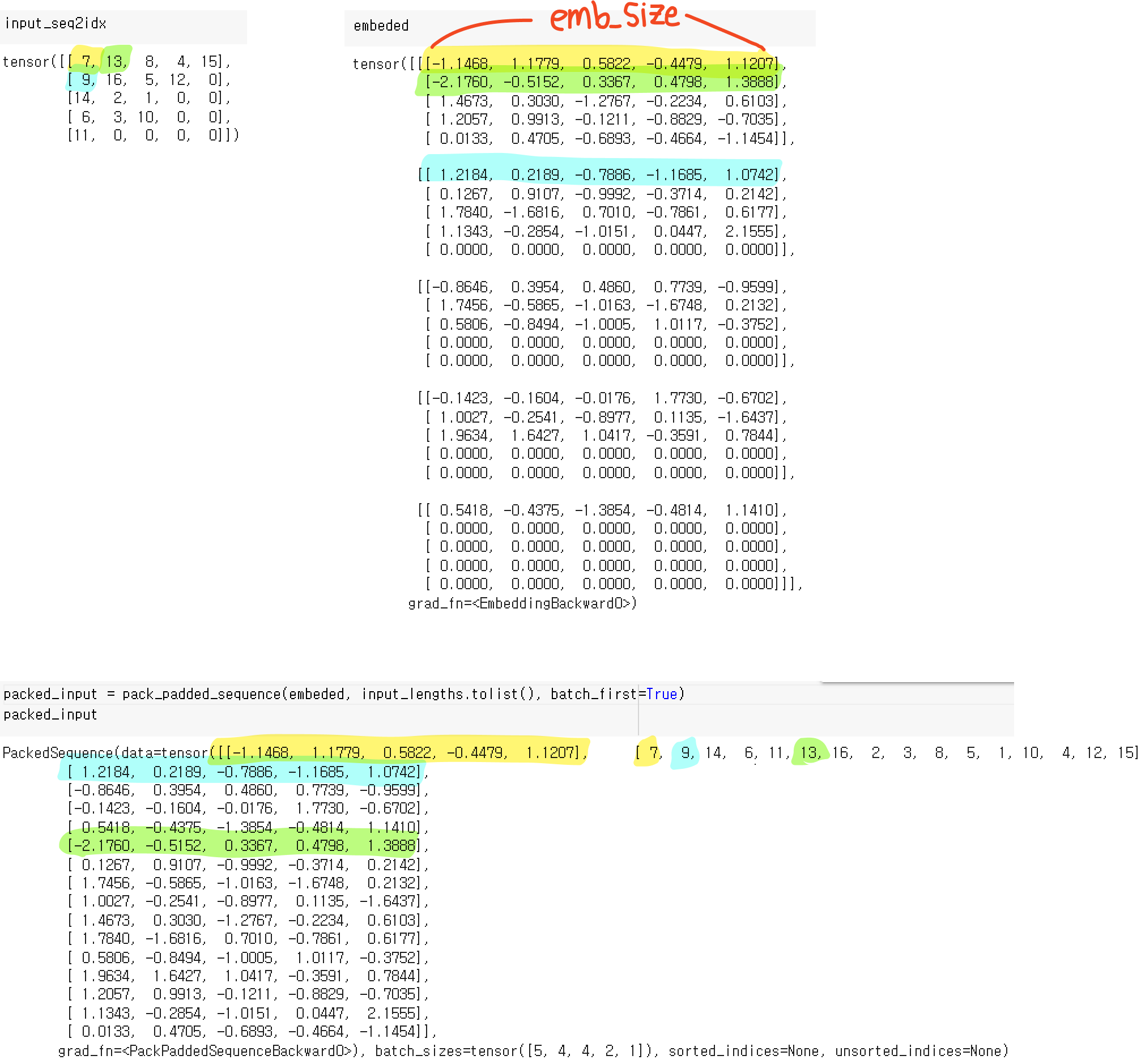
PackedSequence

위와 같은 값을 input이 있다면 중간에 <pad>이 끼어 있어서 불필요한 연산을 어쩔 수 없이 하게 된다.
이를 방지하기 위해서, 아래의 그림같이 각 배치내에 문장의 길이를 기준으로 정렬(sorting) 후, 하나의 통합된 배치로 만들어주는 것이 pack_padded_sequence이다.

위와 같이 정렬을 진행한 후, pack_padded_sequence를 이용해 하나의 통합된 배치로 만든다.

RNN에 적용해보자

embedding한 값을 pack_padded_sequence 시켜준다.
RNN에 batch data를 넣으면 아래와 같이 2가지 output을 얻는다.
hidden_states: 각 time step에 해당하는 hidden state들의 묶음
h_n: 모든 sequence를 거치고 나온 마지막 hidden state

이를 다시 원래 형태의 (batch_size, max_len, hidden_size) 로 바꾸려면 pad_packed_sequence 를 사용하면 된다.

멘토님 설명
계산의 효율성을 위한 테크닉이라고 생각.
어떤 데이터셋에서는 긴 문장은 토큰 많아 정보를 얻기 쉽고 짧은 문장은 토큰이 적어 정보를 많이 얻기 어렵기 때문에 커리큘럼러닝 효과가 날 수도 있다.(쉬운것부터 점점 어려운 순으로 학습하는 방법)
[Day04]
RNN 파라미터 개수 계산

LSTM은 W가 forget/input/gate/output gate마다 있으므로 X4하면 된다.
728x90