[WEEK08] 회고
[Day01]
Rules of Maching Learning
▮ Before Machine Learning
# Rule 1. 머신러닝 없이 제품을 출시하는 것을 두려워하지 말라
많은 사람들이 ML system이 마법처럼 결과를 도출해낸다고 생각하지만 이 결과는 historical data를 기반으로 학습해서 도출된 것이다.
# Rule 2. Metric 항목을 먼저 설계한 다음 구현하라
# Rule 3. 휴리스틱이 복잡하면 머신러닝을 선택하라
휴리스틱 : 경험에 기반하여 문제를 해결하거나 학습하거나 발견해 내는 방법

▮ First Pipeline
# Rule 4. 최초 모델은 단순하게 만든다음에 인프라를 덧붙여 나가라
첫 모델은 제품 개선에 가장 크게 기여하기 때문에 처음부터 화려한 기능을 갖출 필요가 없다.
▮ Monitoring
# Rule 9. 모델을 exporting하기 전에 문제를 발견해라
문제있는 모델을 사용자에게 제공하는 것보다 서비스를 늦게 제공하더라도 제대로 된 모델을 제공해야한다.
모델을 서빙환경으로 내보내기 전에 서버가 충돌하지 않도록 모델의 크기와 모델의 성능을 확인하는 것이 중요하다.
▮ First Objective
# Rule 12. 어떤 Objective를 직접 최적화할지 너무 많이 생각하지 말라
모든 metric이 쉽게 증가할 수 있으므로 다양한 metric 간 균형을 맞추려고 너무 고민하지말고 단순하게 생각해라
ex) 클릭 수 및 사용 시간이 중요하다고 가정한 경우, 클릭 수를 최적화하면 사용 시간도 증가할 가능성이 높다.

# Rule 13. Simple하고 Observable하며 Attributable한 metric을 첫 Objective로 선택하라
단순하고 관찰가능하고 종속적인 사용자 행동을 대상으로 모델링을 시작한다.
Ranked list가 클릭되었는지, Ranked object가 다운되었는지, 평가되었는지 등
간접효과는 AB Test 및 출시 결정에 활용할 수 있는 metric이다.
사용자가 제품을 만족하고 있는가? 를 측정하기는 매우 어렵다.단순하고 관찰가능하고 종속적인 metric을 우선 생각해보자.사용자가 만족감을 느낀다면 사이트에 머무르는 시간이 많을 것이고, 다음 날에도 다시 방문할 것이다.
▮ Training-Serving Skew
Training-Serving Skew : Train 성능과 Serving 성능 간의 차이차이가 나타나는 이유
- Train 파이프라인과 Serving 파이프라인에서 데이터를 처리하는 방법의 차이
- 학습 데이터와 Serving 시 입력받는 데이터 간의 차이
- 모델과 알고리즘 간의 피드백 루프
→ 가장 좋은 해법은 시스템과 데이터의 변화로 인한 차이가 생기지 않도록 모니터링 하는 것
# Rule 29. 서비스하는 것처럼 훈련하는 가장 좋은 방법은 서비스에 사용된 feature들을 저장한 다음 해당 기능을 로그에 연결하여 훈련 시간에 사용하는 것이다.

▮ Slowed Growth, Optimization Refinement, and Complex Models
# Rule 38. 조정되지 않은 objective가 문제가 된 경우 새로운 feature에 시간을 낭비하지 마라
기존의 알고리즘 목표로는 제품의 목표를 해결할 수 없다면 알고리즘 목표와 제품 목표 중 하나를 변경해야 한다.
# Rule 39. 출시 결정은 제품의 장기적인 목표를 반영해야 한다.
앞으로의 머신러닝은 클릭률을 예측하도록 복잡하게 모델링을 하는 것이 아닌 사람과 기계가 우리의 long-term goal에 최적으로 도달할 수 있는지 함께 결정하는 것이다.

[Day03]
모델 불러오기 & 저장하기
1. 모델 전체 Save/Load (권장하지 않음)
- 학습에 사용된 모델 클래스의 구조와 학습 상태 등을 모두 저장
- 모델 파일로도 동일한 구조를 구현할 수 있음
- 이러한 방식은 python의 pickle 모듈을 사용하여 전체 모듈을 저장하는데,
pickle은 모델 그 자체를 저장하지 않기 때문에 직렬화된 데이터가 모델을 저장할 때 사용한 특정 클래스 및 디렉토리 구조에 얽매인다는 단점이 있다.
모델 저장하기
import torch
from model import CustomModel
model = CustomModel()
torch.save(model, f'./model.pt')모델 불러오기
import torch
device = "cuda" if torch.cuda.is_available() else "cpu"
loaded_model = torch.load("model.pt", map_location=device)
print(loaded_model)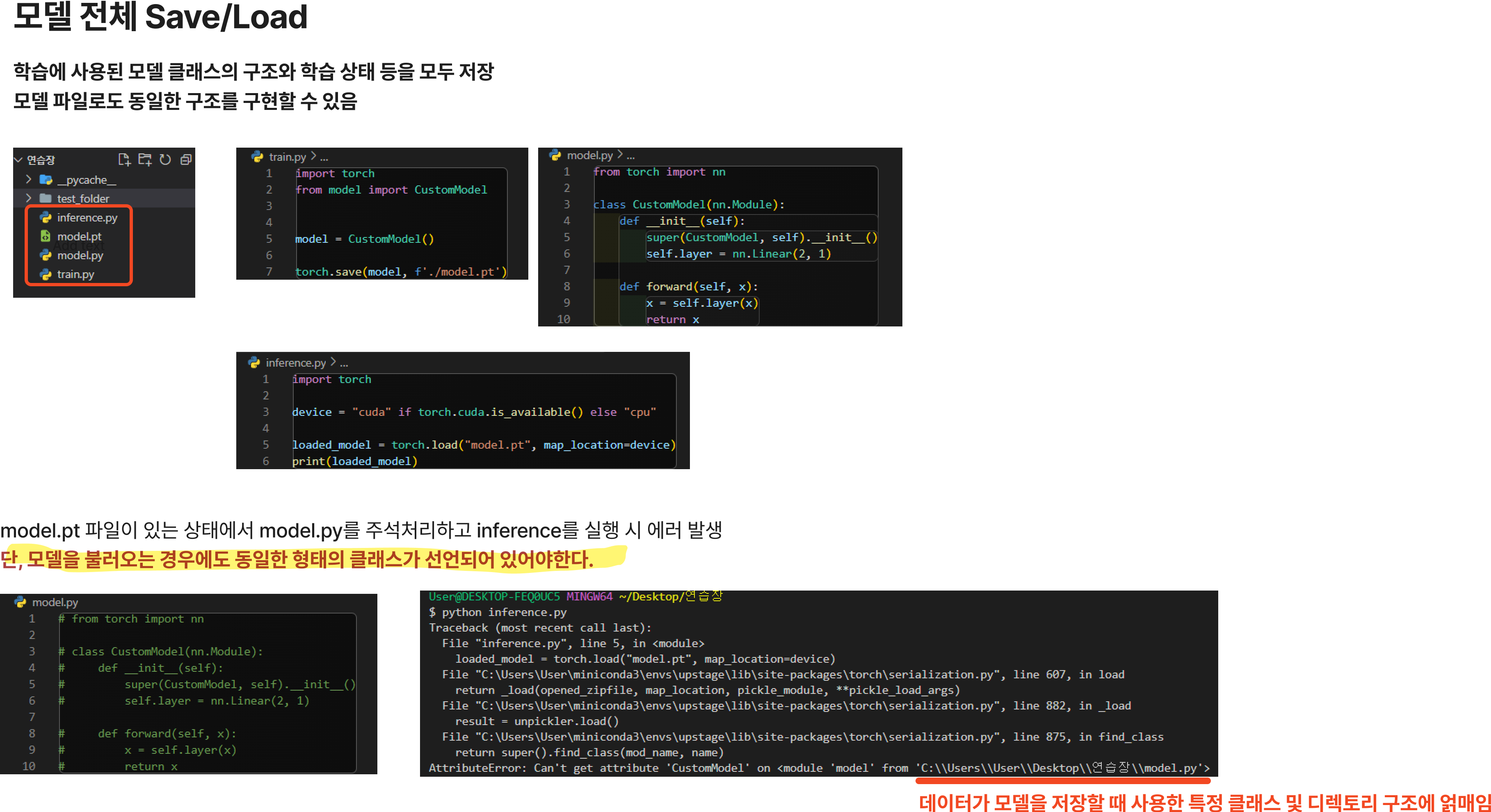

같은 선상의 디렉토리가 아닌 경우에는?

같은 선상인 경우는 import를 안해줘도 되는 것인가?
단 모델은 정의되어있어야하는가?
2. 모델 state_dict Save/Load (권장!)
- 학습된 모델의 학습된 매개변수만 저장하는 방식
- 이 경우에는 모델 상태만 불러오고, 모델 구조를 알 수 없으므로 모델 클래스를 불러와야 있어야 한다.
모델 저장하기
torch.save(model.state_dict(), "./model_state_dict.pt")모델 불러오기
model = CustomModel().to(device)
# load_state_dict에 경로를 전달하는 것이 아닌, 객체를 전달해야한다!
## 따라서 torch.load로 model_state_dict를 객체화한 뒤 load_state_dict에 전달해야한다.
model_state_dict = torch.load("./model_state_dict.pt", map_location=device)
model.load_state_dict(model_state_dict)
print(model)
3. checkpoint 저장/불러오기
- 체크포인트를 저장할 때는 반드시 모델의 state_dict 보다 많은 것들을 저장해야 한다.
모델이 학습을 하며 갱신되는 버퍼와 매개변수가 포함된 옵티마이저의 state_dict 도 함께 저장하는 것이 중요하다. 그 외에도 마지막 에폭(epoch), 최근에 기록된 학습 손실, 외부 torch.nn.Embedding 계층 등도 함께 저장한다.
결과적으로, 체크포인트는 모델만 저장하는 것보다 2~3배 정도 사이즈가 커지게 된다.
체크포인트 저장하기
다양한 정보를 저장하기 위해 사전(Dictionary) 형식으로 값을 저장한다.
학습을 이어서 진행할 수도 있게, 에폭(Epoch), 모델 상태(model.state_dict), 최적화 상태(optimizer.state_dict) 등을 저장한다.
torch.save(
{
"model": "CustomModel",
"epoch": epoch,
"model_state_dict": model.state_dict(),
"optimizer_state_dict": optimizer.state_dict(),
"cost": cost,
"description": f"CustomModel 체크포인트-{checkpoint}",
},
f"./checkpoint-{checkpoint}.pt")체크포인트 불러오기
model = CustomModel().to(device)
criterion = nn.MSELoss().to(device)
optimizer = optim.SGD(model.parameters(), lr=0.0001)
checkpoint = torch.load('./checkpoint-216.pt')
model.load_state_dict(checkpoint["model_state_dict"])
optimizer.load_state_dict(checkpoint["optimizer_state_dict"])
checkpoint_epoch = checkpoint["epoch"]
checkpoint_description = checkpoint["description"]
model.eval()
# - 또는 -
model.train()