[NLP_KLUE] 4. BERT / Huggingface Tokenizer
BERT


왼쪽의 그림은 AutoEncoder이다. 이 모델은 encoder와 decoder로 구성되어있다.
Encoder는 입력된 이미지를 압축된 형태로 표현하는 역할로, RNN의 context vector를 만들어낸다고 볼 수 있다.
Decoder는 압축된 형태를 원본으로 다시 복원하는 역할이다.
즉, AutoEncoder는 원본 이미지를 잘 표현할 수 있게 학습된 모델이다.
오른쪽 그림은 BERT이다.
BERT는 Transformer의 Encoder로 이루어진 모델로, 입력된 정보를 다시 입력된 정보로 representation 하는 것을 목적으로 학습된다.
AutoEncoder와의 차이점은 학습을 할 때 중간 중간의 단어를 Masking 함으로써 복원하기 더 어렵게 만들어서 언어를 좀 더 확실하게 학습하도록 만들어졌다.

- input으로 sentence 2개를 입력받는다.
sent1 + [SEP] + sent2 - 12개의 Transformer layer로 구성되어 있다.
- [CLS] 토큰은 sent1과 sent2가 Next Sentence 관계인지 혹은 전혀 상관없는 Sentence인지를 분류하기 위해 학습된다.
- BERT 내부의 Transformer는 All-to-all network로 연결되어있기 때문에 [CLS] 토큰의 출력벡터가 sent1과 sent2의 정보들이 모두 담긴 embedding 벡터라고 가정한다.
실제로 [CLS] 토큰이 sent1과 sent2를 잘 표현하기 위해 [CLS] 토큰 위에 Classification layer를 부착해서 pre-training을 진행하게 된다.
학습 코퍼스 데이터
- BooksCorpus (800M words)
- English Wikipedia (2,500M words without lists, tables and headers)
- 30,000 token vocabulary
데이터의 tokenizing
- WordPiece tokenizing
- 빈도수 기반으로 tokenizing
- 2개의 token sequence가 학습에 사용
- Next sentence나 Random Chosen sentence

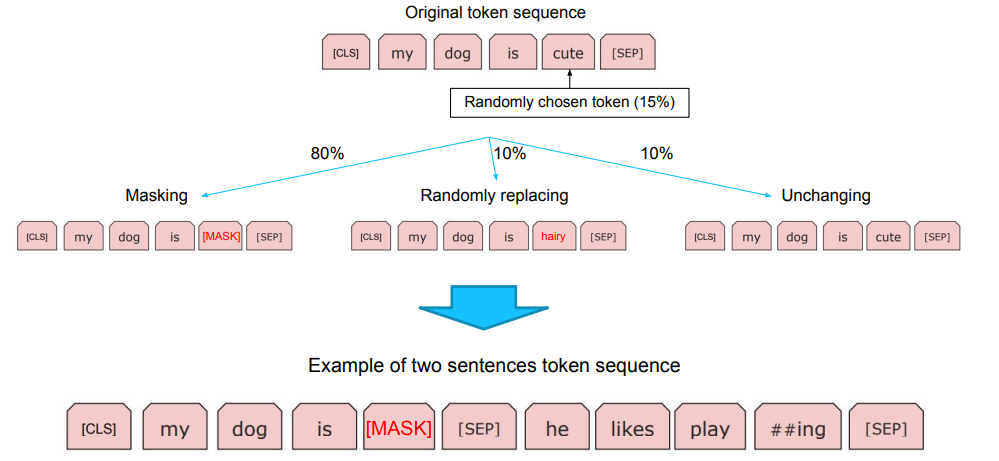
Maksed Language Model
토큰들 중 15%의 확률로 랜덤 토큰을 선택하고
80%의 확률로 Masking, 10% 확률로 Random replacing, 10%의 확률로 Unchanging 해준다.
Huggingface Tokenizer
from transformers import AutoModel, AutoTokenizer
MODEL_NAME = "bert-base-multilingual-cased"
model = AutoModel.from_pretrained(MODEL_NAME)
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)
토크나이저 vocab size 확인 : 119547개
print(tokenizer.vocab_size)
# 119547
tokenizer(text) 처럼 사용할 경우에는 input_ids, token_type_ids, attention_mask 를 바탕으로 값이 출력된다.
text = "이순신은 조선 중기의 무신이다."
tokenized_input_text = tokenizer(text, return_tensors="pt")
print(tokenized_input_text['input_ids']) # input text를 tokenizing한 후 vocab의 id
# tensor([[ 101, 9638, 119064, 25387, 10892, 59906, 9694, 46874, 9294,
# 25387, 11925, 119, 102]])
print(tokenized_input_text['token_type_ids']) # segment id (sentA or sentB)
# tensor([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]])
print(tokenized_input_text['attention_mask']) # special token (pad, cls, sep) or not
# tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]])
- tokenizer.tokenize() : 입력된 문장을 tokenizing
- tokenizer.encode() : 토큰화된 문장의 인코딩된 결과
- tokenizer.decode() : [CLS], [SEP] 토큰이 들어간 형태로 디코딩
tokenized_text = tokenizer.tokenize(
text,
add_special_tokens=True,
max_length=20,
padding="max_length"
)
print(tokenized_text)
# ['[CLS]', '이', '##순', '##신', '##은', '[MASK]', '중', '##기의', '무', '##신', '##이다', '.', '[SEP]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]']
input_ids = tokenizer.encode(
text,
add_special_tokens=True,
max_length=20,
padding="max_length"
)
print(input_ids)
# [101, 9638, 119064, 25387, 10892, 103, 9694, 46874, 9294, 25387, 11925, 119, 102, 0, 0, 0, 0, 0, 0, 0]
decoded_ids = tokenizer.decode(input_ids)
print(decoded_ids)
# [CLS] 이순신은 [MASK] 중기의 무신이다. [SEP] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD]
새로운 토큰 추가
아래와 같이 토크나이징을 할 수 없는 단어는 [UNK]으로 표기된다.
[UNK] 토큰이 많으면 많을수록 원본 데이터의 의미가 사라져버리게 된다.
text = "깟뻬뜨랑 리뿔이 뜨럽거 므리커럭이 케쇽 냐왜쇼 우뤼갸 쳥쇼섀료다혀뚜여"
tokenized_text = tokenizer.tokenize(text, add_special_tokens=False)
print(tokenized_text)
# ['[UNK]', '리', '##뿔', '##이', '뜨', '##럽', '##거', '므', '##리', '##커', '##럭', '##이', '[UNK]', '냐', '##왜', '##쇼', '[UNK]', '[UNK]']
따라서 add_tokens()로 vocab을 추가해줄 수 있다.
added_token_num = tokenizer.add_tokens(["깟뻬뜨랑", "케쇽", "우뤼갸", "쳥쇼", "섀료"])
print(added_token_num)
# 5tokenized_text = tokenizer.tokenize(text, add_special_tokens=False)
print(tokenized_text)
# ['깟뻬뜨랑', '리', '##뿔', '##이', '뜨', '##럽', '##거', '므', '##리', '##커', '##럭', '##이', '케쇽', '냐', '##왜', '##쇼', '우뤼갸', '쳥쇼', '섀료', '다', '##혀', '##뚜', '##여']
add_special_tokens()로 특정 역할을 위한 Special Token도 추가해줄 수 있다.
ENTITY TAG 를 [ENTITY] 이순신 [/ENTITY] 처럼 넣어서 BERT 모델에게 명시적으로 이순신은 ENTITY 입니다를 알려주고 싶다면 special token 을 추가해줘야 한다.
text = "[SHKIM]이순신은 조선 중기의 무신이다.[/SHKIM]"
tokenized_text = tokenizer.tokenize(text, add_special_tokens=False)
print(tokenized_text)
# ['[', 'SH', '##KI', '##M', ']', '이', '##순', '##신', '##은', '조선', '중', '##기의', '무', '##신', '##이다', '.', '[', '/', 'SH', '##KI', '##M', ']']added_token_num += tokenizer.add_special_tokens({"additional_special_tokens":["[SHKIM]", "[/SHKIM]"]})tokenized_text = tokenizer.tokenize(text, add_special_tokens=False)
print(tokenized_text)
# ['[SHKIM]', '이', '##순', '##신', '##은', '조선', '중', '##기의', '무', '##신', '##이다', '.', '[/SHKIM]']print(added_token_num)
# 7
vocab을 새롭게 추가했다면, 반드시 model의 embedding layer 사이즈를 늘려주어야 한다!
print(model.get_input_embeddings())
# Embedding(119547, 768, padding_idx=0)
model.resize_token_embeddings(tokenizer.vocab_size + added_token_num)
print(model.get_input_embeddings())
# Embedding(119554, 768)
부스트캠프 AI Tech 교육 자료를 참고하였습니다.