Huggingface BERT 분석
1. Tokenizer
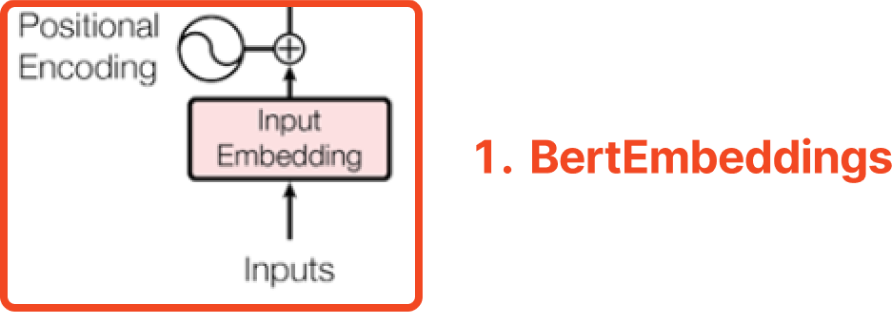
모델에 입력하는 텍스트를 그대로 입력하는 것이 아니라
Tokenizer를 이용하여 텍스트를 tokenize한 후 각 token들을 고유의 id값으로 반환하여 BertEmbeddings에 입력해야한다.
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("klue/bert-base")
tokenizer가 반환하는 출력값은 `input_ids`, 'token_type_ids`, `attention_mask`의 정보가 들어있는 객체이고 각 정보들의 값은 list이다.
- input_ids : token들의 id 리스트
- token_type_ids : BERT는 입력으로 두 문장을 받을 수 있는데(Sentence A, Sentence B), Sentence A에 속하는 token은 0, Sentence B에 속하는 토큰은 1이라는 type_id값으로 반환한 리스트
- attention_mask : attention 연산이 수행되어야 할 token에는 1을, 무시해야할 token은 0으로 반환된 값이 담긴 리스트
tokenizer("Bert 모델을 뜯어보겠습니다.")[출력값]
{ 'input_ids': [2, 23185, 2013, 4347, 2069, 30716, 2918, 2219, 3606, 18, 3],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1] }
원하는 정보들을 각각 가져올 수도 있다.
tokens = tokenizer("Bert 모델을 뜯어보겠습니다.")
print(f"input ids : {tokens['input_ids']}")
print(f"token type ids : {tokens['token_type_ids']}")
print(f"attention mask : {tokens['attention_mask']}")[출력값]
input ids : [2, 23185, 2013, 4347, 2069, 30716, 2918, 2219, 3606, 18, 3]
token type ids : [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
attention mask : [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
만약 token_type_ids나 attention_mask가 필요없다면 아래와 같은 인자에 False를 주면 된다.
tokenizer("Bert 모델을 뜯어보겠습니다.",
return_token_type_ids = False,
return_attention_mask = False)[출력값]
{'input_ids': [2, 23185, 2013, 4347, 2069, 30716, 2918, 2219, 3606, 18, 3]}
token id → token으로 변환해주는 convert_ids_to_tokens() 메소드
tokenizer.convert_ids_to_tokens([2, 23185, 2013, 4347, 2069, 30716, 2918, 2219, 3606, 18, 3])[출력값]
[ '[CLS]', 'Ber', '##t', '모델', '##을', '뜯어보', '##겠', '##습', '##니다', '.', '[SEP]' ]
BERT Tokenizer는 WordPiece 알고리즘을 이용한 Tokenizer이기 때문에 subword로 분리된 단어에는 '##'가 있음을 확인할 수 있다.
token → token id 으로 변환해주는 convert_tokens_to_ids() 메소드
tokenizer.convert_tokens_to_ids([ '[CLS]', 'Ber', '##t', '모델', '##을', '뜯어보', '##겠', '##습', '##니다', '.', '[SEP]' ])[출력값]
[2, 23185, 2013, 4347, 2069, 30716, 2918, 2219, 3606, 18, 3]
또한 tokenizer에 입력하면 문장에 [CLS], [SEP]와 같은 special token이 자동으로 포함된 것을 확인할 수 있다.
BERT가 사용하는 모든 special token들의 정보는 아래처럼 확인이 가능하다.
print(f"special token ids : {tokenizer.all_special_ids}")
print(f"special tokens : {tokenizer.all_special_tokens}")[출력값]
special token ids : [1, 3, 0, 2, 4]
special tokens : ['[UNK]', '[SEP]', '[PAD]', '[CLS]', '[MASK]']
만약 tokenizer의 출력값에 special token이 자동으로 추가되지 않도록 하고 싶다면 add_special_tokens 인자에 False값을 입력하면 된다. (default = True)
tokens = tokenizer("Bert 모델을 뜯어보겠습니다.",
add_special_tokens = False)
print(f"input ids : {tokens['input_ids']}")
print(f"tokens : {tokenizer.convert_ids_to_tokens(tokens['input_ids'])}")[출력값]
input ids : [23185, 2013, 4347, 2069, 30716, 2918, 2219, 3606, 18]
tokens : ['Ber', '##t', '모델', '##을', '뜯어보', '##겠', '##습', '##니다', '.']
tokenizer에 return_tensors 인자에 "pt" 값을 주면 pytorch tensor로 출력된다.
tokenizer("Bert 모델을 뜯어보겠습니다.",
return_tensors = "pt")[출력값]
{'input_ids': tensor([[ 2, 23185, 2013, 4347, 2069, 30716, 2918, 2219, 3606, 18, 3]]), 'token_type_ids': tensor([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]), 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]])}
batch 형태로 입력할 때 batch 안의 각각의 텍스트의 token 갯수가 다르다면 pytorch tensor 값으로 출력받을 수 없다.
max_length와 padding 그리고 truncation 인자를 이용해 이 문제를 해결할 수 있다.
- padding
- "max_length" : 입력의 최대 길이값인 max_length 인자가 주어진 경우 이 길이에 미치지 못한 남은 부분에 padding 값을 추가한다.
(만약 max_length 인자를 입력하지 않았을 경우는 BERT가 입력받을 수 있는 최대 길이 512에 맞춰 padding) - True 또는 "longest" : batch 내의 가장 긴 텍스트에 맞춰서 padding
(만약 batch size가 1이라면 padding하지 않음) - False 또는 "do_not_pad" : default 값으로 padding하지 않음
- "max_length" : 입력의 최대 길이값인 max_length 인자가 주어진 경우 이 길이에 미치지 못한 남은 부분에 padding 값을 추가한다.
- truncation
- True 또는 "longest_first" : max_length 인자가 주어진 경우 그 길이에 맞춰 자른다.
(만약 max_length 인자를 입력하지 않았을 경우는 BERT가 입력받을 수 있는 최대 길이 512에 맞춰 자른다)
(만약 List[List[str]] 형태로 입력이 들어온 경우 하위 list(List[str])가 sentence A, sentence B로 인식하고 두 sentence 중 긴 sentence를 먼저 자른다) - "only_first" : True와 동일한데 단 하나의 차이점이 있다면 만약 List[List[str]] 형태로 입력이 들어온 경우 하위 list(List[str])가 sentence A, sentence B로 인식하고 두 sentence 중에 A sentence만 자른다.
- "only_second" : True와 동일한데 단 하나의 차이점이 있다면 만약 List[List[str]] 형태로 입력이 들어온 경우 하위 list(List[str])가 sentence A, sentence B로 인식하고 두 sentence 중에 B sentence만 자른다.
- False 또는 "do_not_truncate" : default 값으로 자르지 않음
- True 또는 "longest_first" : max_length 인자가 주어진 경우 그 길이에 맞춰 자른다.
tokenizer(["Bert 모델을 뜯어보겠습니다.", "Tokenizer의 사용 방법에 대해 먼저 알아보았습니다.", "다음에는 Bert Model에 대해 알아보겠습니다."],
padding = "longest",
truncation = True,
return_tensors = "pt")[출력값]
{ 'input_ids': tensor([[ 2, 23185, 2013, 4347, 2069, 30716, 2918, 2219, 3606, 18, 3, 0, 0, 0, 0, 0, 0, 0], [ 2, 27878, 8010, 2012, 30900, 2008, 2079, 3704, 3826, 2170, 3643, 4019, 6761, 2886, 2219, 3606, 18, 3], [ 2, 3729, 2170, 2259, 23185, 2013, 22325, 4497, 2170, 3643, 6761, 2918, 2219, 3606, 18, 3, 0, 0]]),
'token_type_ids': tensor([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]),
'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0]])}
2. BertModel
아래와 같이 AutoModel.from_pretrained( ) 메소드를 사용해 BERT의 구조와 "klue/bert-base"의 사전학습한 가중치를 불러올 수 있다.
from transformers import AutoModel
model = AutoModel.from_pretrained("klue/bert-base",
add_pooling_layer=True/False, # default=True
output_hidden_states=True/False, # default=False
output_attentions=True/False) # default=False
- add_pooling_layer : BertModel 위에 추가적으로 pooling layer를 쌓을지 여부 (default = True)
pooling layer는 [CLS] token의 embedding 값만 뽑아 linear연산과 activation 연산을 수행하는 layer로 BERT를 이용해 classification task를 수행할 때 사용한다. - output_hidden_states : BERT의 각 layer들의 hidden state를 담고 있는 배열 hidden_states를 출력할지 여부 (default = False)
- output_attentions : BERT의 각 layer들의 attention weight를 담고 있는 배열 attentions를 출력할지 여부 (default = False)
아래와 같이 model을 통해 구조를 확인할 수 있다. (add_pooling_layer = False로 한 경우 (pooler): BertPooler가 없음을 확인)
print(model)BertModel(
(embeddings): BertEmbeddings(
(word_embeddings): Embedding(32000, 768, padding_idx=0)
(position_embeddings): Embedding(512, 768)
(token_type_embeddings): Embedding(2, 768)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(encoder): BertEncoder(
(layer): ModuleList(
(0): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
(intermediate_act_fn): GELUActivation()
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(1): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
(intermediate_act_fn): GELUActivation()
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
...
(11): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
(intermediate_act_fn): GELUActivation()
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
)
)
model_input = tokenizer("Bert model을 뜯어보자", return_tensors="pt")
output = model(**model_input)
print(output.keys())[출력값]
odict_keys(['last_hidden_state', 'hidden_states', 'attentions'])
output_hidden_states=False, output_attentions=False 일 경우 출력값은 'last_hidden_state' 만 출력된다.
- last_hidden_state : 마지막 layer의 hidden_state로 BERT 모델의 최종 embedding 값이다.
output.last_hidden_state.shape → torch.Size( [ batch_size, sequence_length, 768] ) - hidden_states : 각 layer의 hidden_state를 모아놓은 list이다.
len(output.hidden_states) → 13
output.hidden_states[0].shape → torch.Size( [ batch_size, sequence_length, 768] ) - attentions : 각 layer의 attention weight를 모아놓은 list
len(output.attentions) → 12
output.attentions[0].shape → torch.Size( [ batch_size, 12, sequence_length, sequence_length] )
BertModel을 구성하는 각 모듈이 하는 일은 다음과 같다.
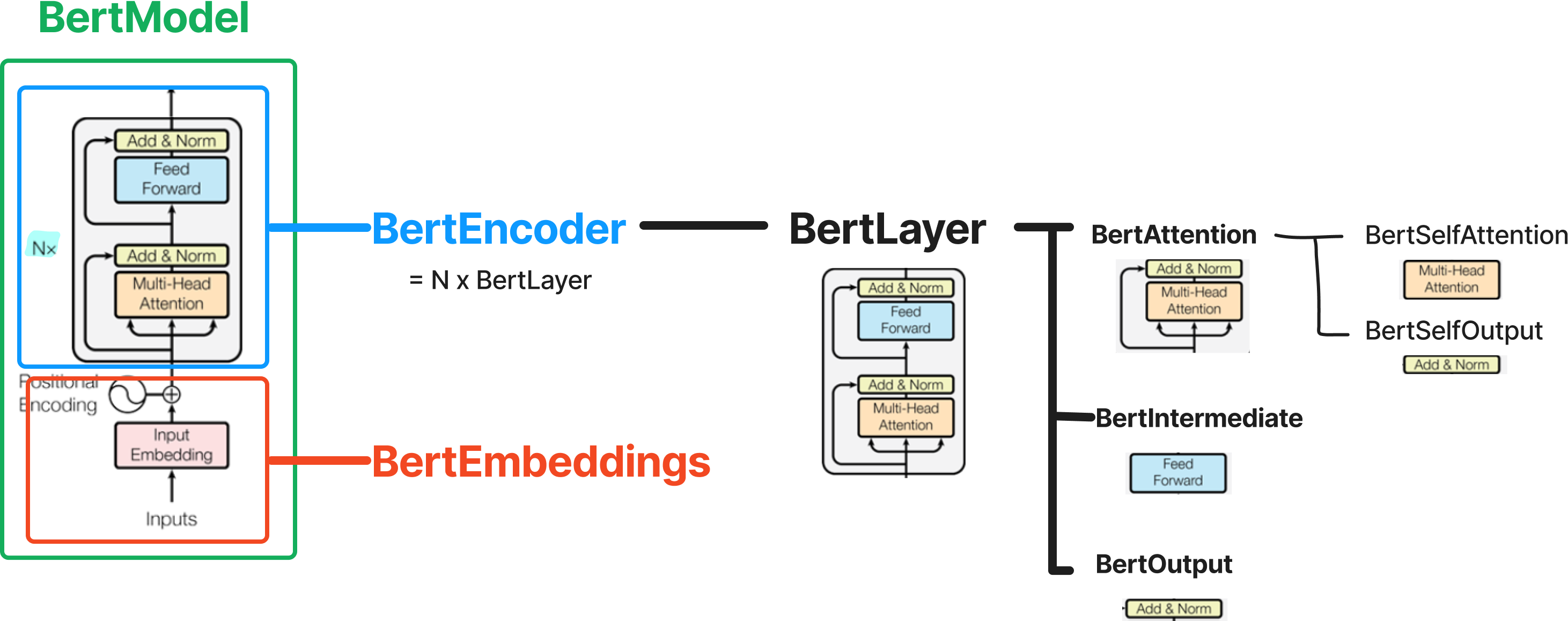
- BertEmbeddings : 입력된 input_ids를 위치 정보가 반영된 embedding으로 변환
- BertEncoder : BertEmbeddings에서 얻은 embedding을 여러 번의 BertLayer를 거쳐 contextual embedding으로 변환
- BertLayer
- BertAttention : 이전 BertLayer가 만든 hidden_states를 입력으로 받아, mutli-head self attention 연산 및 residual connection, layer normalization을 수행
- BertSelfAttention : hidden_states에 대해 multi-head attention을 수행
- BertSelfOutput : BertSelfAttention의 출력값을 입력으로 받아, residual connection, layer normalization을 수행
- BertIntermediate : BertAttention의 출력값을 입력으로 받아, feed forward 연산(linear + activation + linear)을 수행
- BertOutput : BertIntermediate의 출력값을 입력으로 받아, residual connection, layer normalization을 수행
- BertAttention : 이전 BertLayer가 만든 hidden_states를 입력으로 받아, mutli-head self attention 연산 및 residual connection, layer normalization을 수행
- BertLayer
- BertPooler : BertEncoder에서 얻은 contextual embedding 중 [CLS] token의 embedding만을 뽑아내어 classification task를 위한 텐서로 변환
2. BertModel
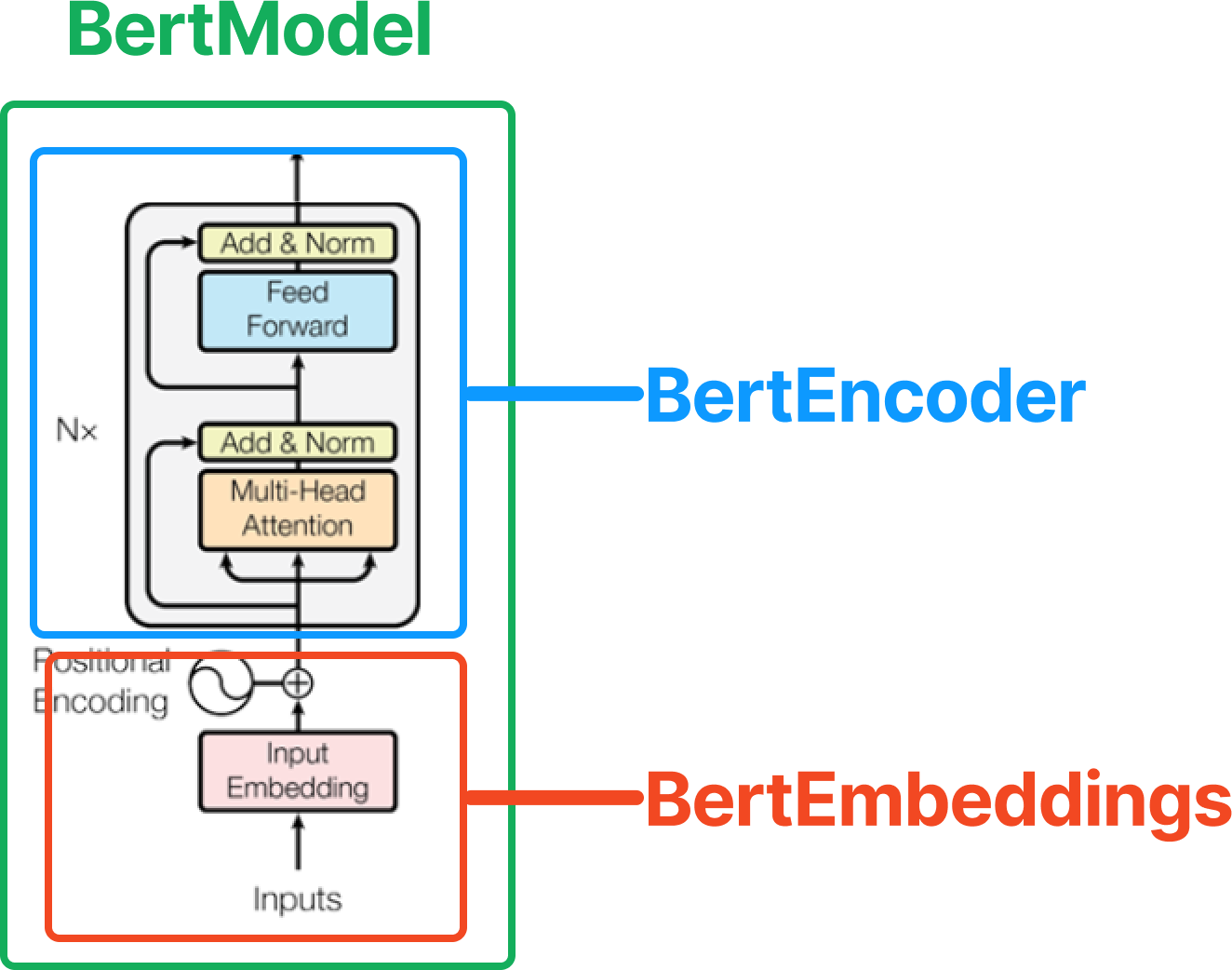
BertModel의 구성 모듈은 BertEmbeddings 클래스와 BertEncoder 클래스이다.
BertPooler 클래스도 있지만 BertModel 로드 시 add_pooling_layer 인자에 False 값을 주면 동작하지 않는다.
class BertModel(BertPreTrainedModel):
"""
The model can behave as an encoder (with only self-attention) as well as a decoder, in which case a layer of
cross-attention is added between the self-attention layers, following the architecture described in [Attention is
all you need](https://arxiv.org/abs/1706.03762) by Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit,
Llion Jones, Aidan N. Gomez, Lukasz Kaiser and Illia Polosukhin.
To behave as an decoder the model needs to be initialized with the `is_decoder` argument of the configuration set
to `True`. To be used in a Seq2Seq model, the model needs to initialized with both `is_decoder` argument and
`add_cross_attention` set to `True`; an `encoder_hidden_states` is then expected as an input to the forward pass.
"""
def __init__(self, config, add_pooling_layer=True):
super().__init__(config)
self.config = config
self.embeddings = BertEmbeddings(config)
self.encoder = BertEncoder(config)
self.pooler = BertPooler(config) if add_pooling_layer else None
# Initialize weights and apply final processing
self.post_init()
def get_input_embeddings(self):
return self.embeddings.word_embeddings
def set_input_embeddings(self, value):
self.embeddings.word_embeddings = value
def _prune_heads(self, heads_to_prune):
"""
Prunes heads of the model. heads_to_prune: dict of {layer_num: list of heads to prune in this layer} See base
class PreTrainedModel
"""
for layer, heads in heads_to_prune.items():
self.encoder.layer[layer].attention.prune_heads(heads)
@add_start_docstrings_to_model_forward(BERT_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
@add_code_sample_docstrings(
processor_class=_TOKENIZER_FOR_DOC,
checkpoint=_CHECKPOINT_FOR_DOC,
output_type=BaseModelOutputWithPoolingAndCrossAttentions,
config_class=_CONFIG_FOR_DOC,
)
def forward(
self,
input_ids: Optional[torch.Tensor] = None,
attention_mask: Optional[torch.Tensor] = None,
token_type_ids: Optional[torch.Tensor] = None,
position_ids: Optional[torch.Tensor] = None,
head_mask: Optional[torch.Tensor] = None,
inputs_embeds: Optional[torch.Tensor] = None,
encoder_hidden_states: Optional[torch.Tensor] = None,
encoder_attention_mask: Optional[torch.Tensor] = None,
past_key_values: Optional[List[torch.FloatTensor]] = None,
use_cache: Optional[bool] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> Union[Tuple[torch.Tensor], BaseModelOutputWithPoolingAndCrossAttentions]:
r"""
encoder_hidden_states (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
Sequence of hidden-states at the output of the last layer of the encoder. Used in the cross-attention if
the model is configured as a decoder.
encoder_attention_mask (`torch.FloatTensor` of shape `(batch_size, sequence_length)`, *optional*):
Mask to avoid performing attention on the padding token indices of the encoder input. This mask is used in
the cross-attention if the model is configured as a decoder. Mask values selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
past_key_values (`tuple(tuple(torch.FloatTensor))` of length `config.n_layers` with each tuple having 4 tensors of shape `(batch_size, num_heads, sequence_length - 1, embed_size_per_head)`):
Contains precomputed key and value hidden states of the attention blocks. Can be used to speed up decoding.
If `past_key_values` are used, the user can optionally input only the last `decoder_input_ids` (those that
don't have their past key value states given to this model) of shape `(batch_size, 1)` instead of all
`decoder_input_ids` of shape `(batch_size, sequence_length)`.
use_cache (`bool`, *optional*):
If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding (see
`past_key_values`).
"""
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
if self.config.is_decoder:
use_cache = use_cache if use_cache is not None else self.config.use_cache
else:
use_cache = False
if input_ids is not None and inputs_embeds is not None:
raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
elif input_ids is not None:
input_shape = input_ids.size()
elif inputs_embeds is not None:
input_shape = inputs_embeds.size()[:-1]
else:
raise ValueError("You have to specify either input_ids or inputs_embeds")
batch_size, seq_length = input_shape
device = input_ids.device if input_ids is not None else inputs_embeds.device
# past_key_values_length
past_key_values_length = past_key_values[0][0].shape[2] if past_key_values is not None else 0
if attention_mask is None:
attention_mask = torch.ones(((batch_size, seq_length + past_key_values_length)), device=device)
if token_type_ids is None:
if hasattr(self.embeddings, "token_type_ids"):
buffered_token_type_ids = self.embeddings.token_type_ids[:, :seq_length]
buffered_token_type_ids_expanded = buffered_token_type_ids.expand(batch_size, seq_length)
token_type_ids = buffered_token_type_ids_expanded
else:
token_type_ids = torch.zeros(input_shape, dtype=torch.long, device=device)
# We can provide a self-attention mask of dimensions [batch_size, from_seq_length, to_seq_length]
# ourselves in which case we just need to make it broadcastable to all heads.
extended_attention_mask: torch.Tensor = self.get_extended_attention_mask(attention_mask, input_shape)
# If a 2D or 3D attention mask is provided for the cross-attention
# we need to make broadcastable to [batch_size, num_heads, seq_length, seq_length]
if self.config.is_decoder and encoder_hidden_states is not None:
encoder_batch_size, encoder_sequence_length, _ = encoder_hidden_states.size()
encoder_hidden_shape = (encoder_batch_size, encoder_sequence_length)
if encoder_attention_mask is None:
encoder_attention_mask = torch.ones(encoder_hidden_shape, device=device)
encoder_extended_attention_mask = self.invert_attention_mask(encoder_attention_mask)
else:
encoder_extended_attention_mask = None
# Prepare head mask if needed
# 1.0 in head_mask indicate we keep the head
# attention_probs has shape bsz x n_heads x N x N
# input head_mask has shape [num_heads] or [num_hidden_layers x num_heads]
# and head_mask is converted to shape [num_hidden_layers x batch x num_heads x seq_length x seq_length]
head_mask = self.get_head_mask(head_mask, self.config.num_hidden_layers)
embedding_output = self.embeddings(
input_ids=input_ids,
position_ids=position_ids,
token_type_ids=token_type_ids,
inputs_embeds=inputs_embeds,
past_key_values_length=past_key_values_length,
)
encoder_outputs = self.encoder(
embedding_output,
attention_mask=extended_attention_mask,
head_mask=head_mask,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_extended_attention_mask,
past_key_values=past_key_values,
use_cache=use_cache,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
sequence_output = encoder_outputs[0]
pooled_output = self.pooler(sequence_output) if self.pooler is not None else None
if not return_dict:
return (sequence_output, pooled_output) + encoder_outputs[1:]
return BaseModelOutputWithPoolingAndCrossAttentions(
last_hidden_state=sequence_output,
pooler_output=pooled_output,
past_key_values=encoder_outputs.past_key_values,
hidden_states=encoder_outputs.hidden_states,
attentions=encoder_outputs.attentions,
cross_attentions=encoder_outputs.cross_attentions,
)
embeddings 모듈은 input_ids, position_ids, token_type_ids 등의 입력 데이터를 받아 embedding_output을 반환한다.
embedding_output = self.embeddings(
input_ids=input_ids,
position_ids=position_ids,
token_type_ids=token_type_ids,
inputs_embeds=inputs_embeds,
past_key_values_length=past_key_values_length,
)encoder 모듈은 embedding 모듈이 만든 embedding_output을 문맥 정보가 반영된 embedding (contextual embedding)으로 변환한다.
encoder_outputs = self.encoder(
embedding_output,
attention_mask=extended_attention_mask,
head_mask=head_mask,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_extended_attention_mask,
past_key_values=past_key_values,
use_cache=use_cache,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
2.1 BertEmbeddings
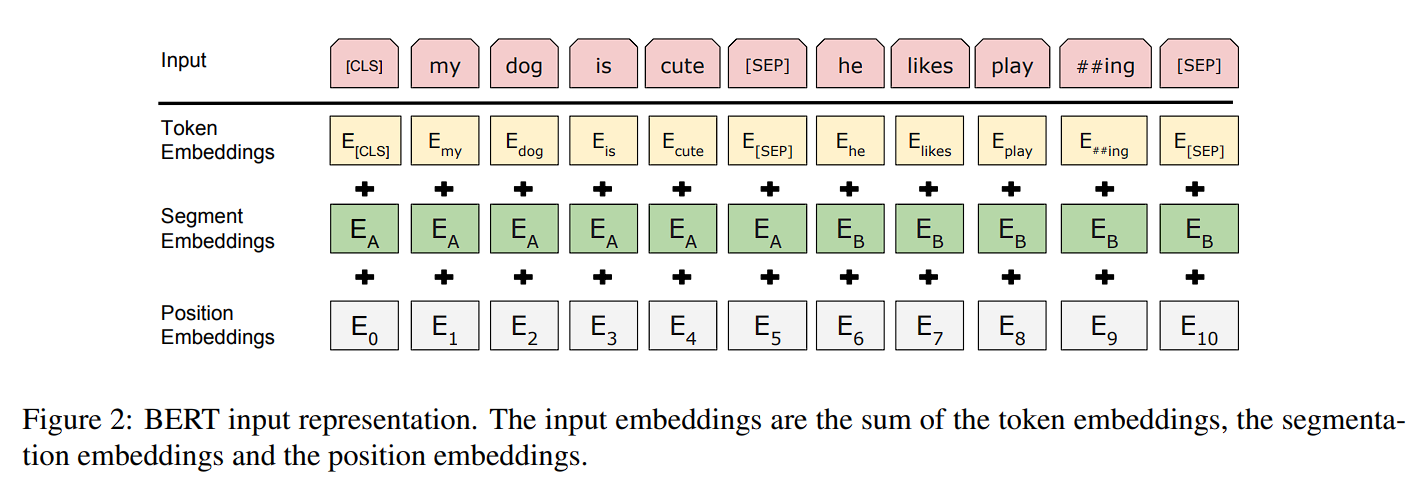
BertEmbeddings는 word_embeddings, position_embeddings, token_type_embeddings, LayerNorm, dropout 총 5개의 layer로 이루어져있다.
class BertEmbeddings(nn.Module):
"""Construct the embeddings from word, position and token_type embeddings."""
def __init__(self, config):
super().__init__()
self.word_embeddings = nn.Embedding(config.vocab_size, config.hidden_size, padding_idx=config.pad_token_id)
self.position_embeddings = nn.Embedding(config.max_position_embeddings, config.hidden_size)
self.token_type_embeddings = nn.Embedding(config.type_vocab_size, config.hidden_size)
# self.LayerNorm is not snake-cased to stick with TensorFlow model variable name and be able to load
# any TensorFlow checkpoint file
self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
# position_ids (1, len position emb) is contiguous in memory and exported when serialized
self.position_embedding_type = getattr(config, "position_embedding_type", "absolute")
self.register_buffer("position_ids", torch.arange(config.max_position_embeddings).expand((1, -1)))
self.register_buffer(
"token_type_ids", torch.zeros(self.position_ids.size(), dtype=torch.long), persistent=False
)
def forward(
self,
input_ids: Optional[torch.LongTensor] = None,
token_type_ids: Optional[torch.LongTensor] = None,
position_ids: Optional[torch.LongTensor] = None,
inputs_embeds: Optional[torch.FloatTensor] = None,
past_key_values_length: int = 0,
) -> torch.Tensor:
if input_ids is not None:
input_shape = input_ids.size()
else:
input_shape = inputs_embeds.size()[:-1]
seq_length = input_shape[1]
if position_ids is None:
position_ids = self.position_ids[:, past_key_values_length : seq_length + past_key_values_length]
# Setting the token_type_ids to the registered buffer in constructor where it is all zeros, which usually occurs
# when its auto-generated, registered buffer helps users when tracing the model without passing token_type_ids, solves
# issue #5664
if token_type_ids is None:
if hasattr(self, "token_type_ids"):
buffered_token_type_ids = self.token_type_ids[:, :seq_length]
buffered_token_type_ids_expanded = buffered_token_type_ids.expand(input_shape[0], seq_length)
token_type_ids = buffered_token_type_ids_expanded
else:
token_type_ids = torch.zeros(input_shape, dtype=torch.long, device=self.position_ids.device)
if inputs_embeds is None:
inputs_embeds = self.word_embeddings(input_ids)
token_type_embeddings = self.token_type_embeddings(token_type_ids)
embeddings = inputs_embeds + token_type_embeddings
if self.position_embedding_type == "absolute":
position_embeddings = self.position_embeddings(position_ids)
embeddings += position_embeddings
embeddings = self.LayerNorm(embeddings)
embeddings = self.dropout(embeddings)
return embeddings
word_embeddings layer는 입력된 정수 형태의 token id들을 hidden_size 크기의 벡터로 변환한다.
model.embeddings.word_embeddings[출력값]
Embedding(32000, 768, padding_idx=0)
32000은 vocabulary의 크기, 768은 hidden_size이다.
position_embeddings layer는 각 token의 위치 정보를 hidden_size 차원의 벡터 형태로 변환한다.
model.embeddings.position_embeddings[출력값]
Embedding(512, 768)
512는 BERT가 한번에 받아들일 수 있는 최대 token의 수, 768은 hidden_size이다.
if position_ids is None:
position_ids = self.position_ids[:, past_key_values_length : seq_length + past_key_values_length]만약 position_ids가 입력되지 않은 경우 past_key_values_length(default : 0)부터 seq_length + past_key_value_length 까지를 position_ids로 설정한다.
if self.position_embedding_type == "absolute":
position_embeddings = self.position_embeddings(position_ids)
embeddings += position_embeddings그리고 position_ids를 인덱스로 사용하여 model.embeddings.position_embeddings layer로 position_embeddings를 계산한다.
token_type_embeddings는 각 token의 type 정보를 입력하는 layer이다.
model.embeddings.token_type_embeddings[출력값]
Embedding(2, 768)
2는 BERT가 받아들일 수 있는 Sentence의 개수, 768은 hidden_size(출력되는 embedding의 차원)이다.
if token_type_ids is None:
if hasattr(self, "token_type_ids"):
buffered_token_type_ids = self.token_type_ids[:, :seq_length]
buffered_token_type_ids_expanded = buffered_token_type_ids.expand(input_shape[0], seq_length)
token_type_ids = buffered_token_type_ids_expanded
else:
token_type_ids = torch.zeros(input_shape, dtype=torch.long, device=self.position_ids.device)token_type_ids가 입력되지 않은 경우 default로 모든 값이 0으로 채워진 token_type_ids를 만들어 사용한다.
앞서 설명한 word_embeddings, position_embeddings, token_type_embeddings를 모두 합쳐서 embeddings라는 embedding을 만든다.
세 embeddings 모두 크기가 hidden_size이므로 만들어진 embeddings의 크기도 hidden_size인 벡터이다.
그리고 이 embeddings를 LayerNorm과 Dropout에 순차적으로 통과시켜 최종적인 embedding을 만든다.
embeddings = inputs_embeds + token_type_embeddings
if self.position_embedding_type == "absolute":
position_embeddings = self.position_embeddings(position_ids)
embeddings += position_embeddings
embeddings = self.LayerNorm(embeddings)
embeddings = self.dropout(embeddings)
2.2 BertEncoder
__init__에서 layer라는 이름으로 BertLayer 모듈이 torch.nn.ModuleList로 config.num_hidden_layers개(klue/bert-base의 경우 12개) 쌓여 있는 것을 볼 수 있다.
그리고 for 문을 통해 BertLayer를 하나씩 사용한다.
class BertEncoder(nn.Module):
def __init__(self, config):
super().__init__()
self.config = config
self.layer = nn.ModuleList([BertLayer(config) for _ in range(config.num_hidden_layers)])
self.gradient_checkpointing = False
def forward(
self,
hidden_states: torch.Tensor,
attention_mask: Optional[torch.FloatTensor] = None,
head_mask: Optional[torch.FloatTensor] = None,
encoder_hidden_states: Optional[torch.FloatTensor] = None,
encoder_attention_mask: Optional[torch.FloatTensor] = None,
past_key_values: Optional[Tuple[Tuple[torch.FloatTensor]]] = None,
use_cache: Optional[bool] = None,
output_attentions: Optional[bool] = False,
output_hidden_states: Optional[bool] = False,
return_dict: Optional[bool] = True,
) -> Union[Tuple[torch.Tensor], BaseModelOutputWithPastAndCrossAttentions]:
all_hidden_states = () if output_hidden_states else None
all_self_attentions = () if output_attentions else None
all_cross_attentions = () if output_attentions and self.config.add_cross_attention else None
next_decoder_cache = () if use_cache else None
for i, layer_module in enumerate(self.layer):
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
layer_head_mask = head_mask[i] if head_mask is not None else None
past_key_value = past_key_values[i] if past_key_values is not None else None
if self.gradient_checkpointing and self.training:
if use_cache:
logger.warning(
"`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`..."
)
use_cache = False
def create_custom_forward(module):
def custom_forward(*inputs):
return module(*inputs, past_key_value, output_attentions)
return custom_forward
layer_outputs = torch.utils.checkpoint.checkpoint(
create_custom_forward(layer_module),
hidden_states,
attention_mask,
layer_head_mask,
encoder_hidden_states,
encoder_attention_mask,
)
else:
layer_outputs = layer_module(
hidden_states,
attention_mask,
layer_head_mask,
encoder_hidden_states,
encoder_attention_mask,
past_key_value,
output_attentions,
)
hidden_states = layer_outputs[0]
if use_cache:
next_decoder_cache += (layer_outputs[-1],)
if output_attentions:
all_self_attentions = all_self_attentions + (layer_outputs[1],)
if self.config.add_cross_attention:
all_cross_attentions = all_cross_attentions + (layer_outputs[2],)
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
if not return_dict:
return tuple(
v
for v in [
hidden_states,
next_decoder_cache,
all_hidden_states,
all_self_attentions,
all_cross_attentions,
]
if v is not None
)
return BaseModelOutputWithPastAndCrossAttentions(
last_hidden_state=hidden_states,
past_key_values=next_decoder_cache,
hidden_states=all_hidden_states,
attentions=all_self_attentions,
cross_attentions=all_cross_attentions,
)
BertLayer의 출력값 layer_outputs는 hidden_states, selft_attentions, cross_attentions를 순서대로 포함하고 있다.
- layer_output[0] == BertLayer의 hidden_states
- layer_output[1] == BertLayer의 self_attentions
- layer_output[2] == BertLayer의 cross_attentions
또한 현재 BertLayer에 이전 hidden_states를 입력하여 계속 embedding 값을 업데이트함을 확인할 수 있다.
layer_outputs = layer_module(
hidden_states,
attention_mask,
layer_head_mask,
encoder_hidden_states,
encoder_attention_mask,
past_key_value,
output_attentions,
)
hidden_states = layer_outputs[0]
if use_cache:
next_decoder_cache += (layer_outputs[-1],)
if output_attentions:
all_self_attentions = all_self_attentions + (layer_outputs[1],)
if self.config.add_cross_attention:
all_cross_attentions = all_cross_attentions + (layer_outputs[2],)
model = AutoModel.from_pretrained("klue/bert-base", output_hidden_states=True, output_attentions=True) 로 설정한 경우
BertLayer의 hidden_states는 all_hidden_state 뒤에 추가되어 저장되고
BertLayer의 self_attentions는 all_self_attentions 뒤에 추가되어 저장된다. (위 코드의 if output_attentions: 부분)
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
2.2.1 BertLayer
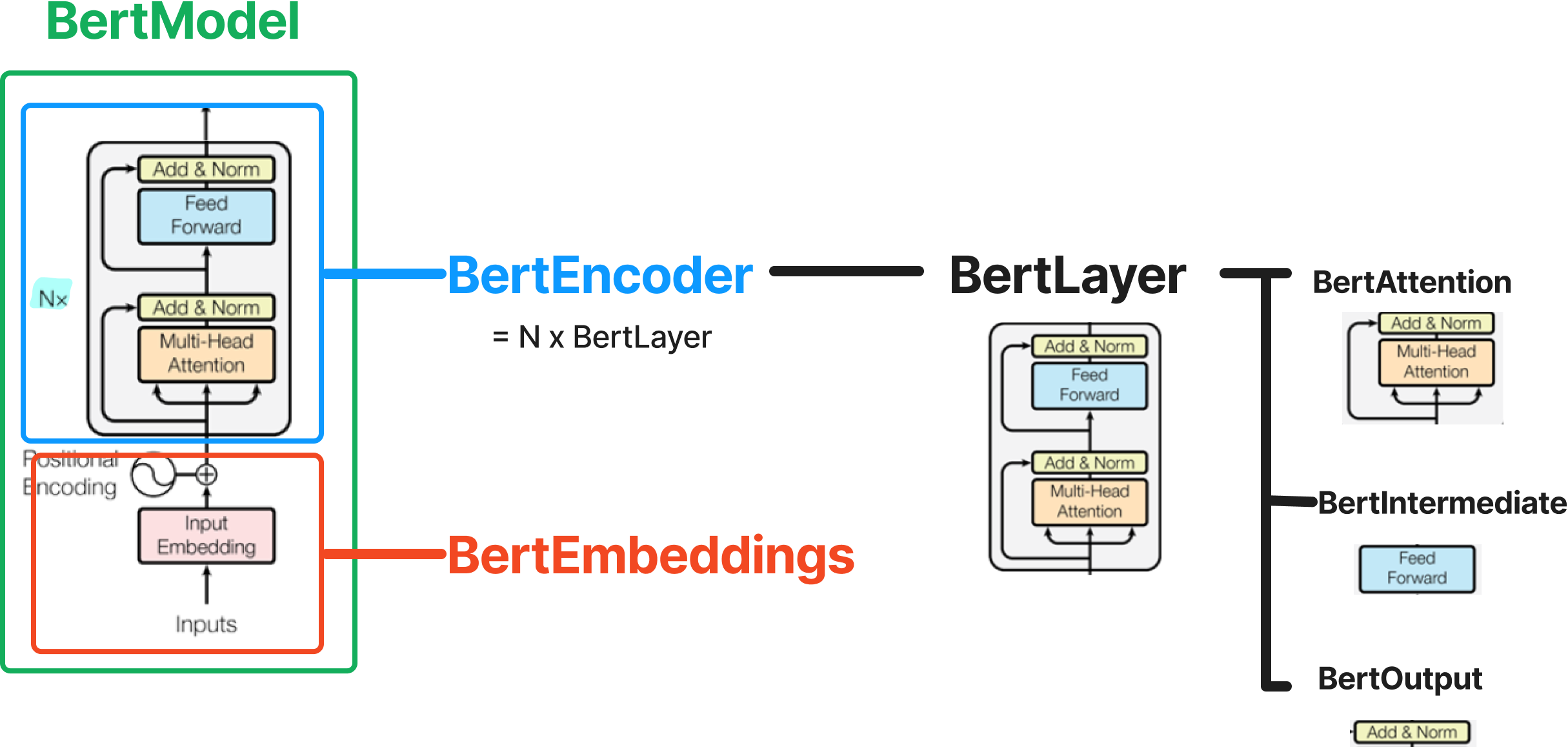
BertLayer는 앞서 설명한 BertEncoder의 구성 요소이다.
BertLayer는 BertAttention 클래스로 만들어진 attention 모듈, BertIntermediate 클래스로 만들어진 intermediate 모듈, BertOutput 클래스로 만들어진 output 모듈로 이루어져 있다.
class BertLayer(nn.Module):
def __init__(self, config):
super().__init__()
self.chunk_size_feed_forward = config.chunk_size_feed_forward
self.seq_len_dim = 1
self.attention = BertAttention(config)
self.is_decoder = config.is_decoder
self.add_cross_attention = config.add_cross_attention
if self.add_cross_attention:
if not self.is_decoder:
raise ValueError(f"{self} should be used as a decoder model if cross attention is added")
self.crossattention = BertAttention(config, position_embedding_type="absolute")
self.intermediate = BertIntermediate(config)
self.output = BertOutput(config)
def forward(
self,
hidden_states: torch.Tensor,
attention_mask: Optional[torch.FloatTensor] = None,
head_mask: Optional[torch.FloatTensor] = None,
encoder_hidden_states: Optional[torch.FloatTensor] = None,
encoder_attention_mask: Optional[torch.FloatTensor] = None,
past_key_value: Optional[Tuple[Tuple[torch.FloatTensor]]] = None,
output_attentions: Optional[bool] = False,
) -> Tuple[torch.Tensor]:
# decoder uni-directional self-attention cached key/values tuple is at positions 1,2
self_attn_past_key_value = past_key_value[:2] if past_key_value is not None else None
self_attention_outputs = self.attention(
hidden_states,
attention_mask,
head_mask,
output_attentions=output_attentions,
past_key_value=self_attn_past_key_value,
)
attention_output = self_attention_outputs[0]
# if decoder, the last output is tuple of self-attn cache
if self.is_decoder:
outputs = self_attention_outputs[1:-1]
present_key_value = self_attention_outputs[-1]
else:
outputs = self_attention_outputs[1:] # add self attentions if we output attention weights
cross_attn_present_key_value = None
if self.is_decoder and encoder_hidden_states is not None:
if not hasattr(self, "crossattention"):
raise ValueError(
f"If `encoder_hidden_states` are passed, {self} has to be instantiated with cross-attention layers"
" by setting `config.add_cross_attention=True`"
)
# cross_attn cached key/values tuple is at positions 3,4 of past_key_value tuple
cross_attn_past_key_value = past_key_value[-2:] if past_key_value is not None else None
cross_attention_outputs = self.crossattention(
attention_output,
attention_mask,
head_mask,
encoder_hidden_states,
encoder_attention_mask,
cross_attn_past_key_value,
output_attentions,
)
attention_output = cross_attention_outputs[0]
outputs = outputs + cross_attention_outputs[1:-1] # add cross attentions if we output attention weights
# add cross-attn cache to positions 3,4 of present_key_value tuple
cross_attn_present_key_value = cross_attention_outputs[-1]
present_key_value = present_key_value + cross_attn_present_key_value
layer_output = apply_chunking_to_forward(
self.feed_forward_chunk, self.chunk_size_feed_forward, self.seq_len_dim, attention_output
)
outputs = (layer_output,) + outputs
# if decoder, return the attn key/values as the last output
if self.is_decoder:
outputs = outputs + (present_key_value,)
return outputs
def feed_forward_chunk(self, attention_output):
intermediate_output = self.intermediate(attention_output)
layer_output = self.output(intermediate_output, attention_output)
return layer_output
2.2.1.1 BertAttention

BertAttention 모듈은 BertSelfAttention 클래스로 만들어진 self 모듈과 BertSelfOutput 클래스로 만들어진 output 모듈로 이루어져 있다.
BertSelfAttention 클래스는 multi-head self attention 연산을 수행하는 모듈이고 BertSelfOutput은 layer Normalization 연산을 수행하는 모듈이다.
BertAttention 모듈은 입력된 hidden_states에 대해 BertSelfAttention 클래스로 multi-head self attention 연산을 수행하고 그 결과와 원본 hidden_states를 가지고 Residual Connection을 만들고 layer Normalization을 수행한 결과값을 반환하는 역할이다.
class BertAttention(nn.Module):
def __init__(self, config, position_embedding_type=None):
super().__init__()
self.self = BertSelfAttention(config, position_embedding_type=position_embedding_type)
self.output = BertSelfOutput(config)
self.pruned_heads = set()
def prune_heads(self, heads):
if len(heads) == 0:
return
heads, index = find_pruneable_heads_and_indices(
heads, self.self.num_attention_heads, self.self.attention_head_size, self.pruned_heads
)
# Prune linear layers
self.self.query = prune_linear_layer(self.self.query, index)
self.self.key = prune_linear_layer(self.self.key, index)
self.self.value = prune_linear_layer(self.self.value, index)
self.output.dense = prune_linear_layer(self.output.dense, index, dim=1)
# Update hyper params and store pruned heads
self.self.num_attention_heads = self.self.num_attention_heads - len(heads)
self.self.all_head_size = self.self.attention_head_size * self.self.num_attention_heads
self.pruned_heads = self.pruned_heads.union(heads)
def forward(
self,
hidden_states: torch.Tensor,
attention_mask: Optional[torch.FloatTensor] = None,
head_mask: Optional[torch.FloatTensor] = None,
encoder_hidden_states: Optional[torch.FloatTensor] = None,
encoder_attention_mask: Optional[torch.FloatTensor] = None,
past_key_value: Optional[Tuple[Tuple[torch.FloatTensor]]] = None,
output_attentions: Optional[bool] = False,
) -> Tuple[torch.Tensor]:
self_outputs = self.self(
hidden_states,
attention_mask,
head_mask,
encoder_hidden_states,
encoder_attention_mask,
past_key_value,
output_attentions,
)
attention_output = self.output(self_outputs[0], hidden_states)
outputs = (attention_output,) + self_outputs[1:] # add attentions if we output them
return outputs
2.2.1.1.1 BertSelfAttention

BertSelfAttention은 BERT의 가장 핵심적인 연산인 multi-head self attention을 수행하는 모듈이다.
class BertSelfAttention(nn.Module):
def __init__(self, config, position_embedding_type=None):
super().__init__()
if config.hidden_size % config.num_attention_heads != 0 and not hasattr(config, "embedding_size"):
raise ValueError(
f"The hidden size ({config.hidden_size}) is not a multiple of the number of attention "
f"heads ({config.num_attention_heads})"
)
self.num_attention_heads = config.num_attention_heads
self.attention_head_size = int(config.hidden_size / config.num_attention_heads)
self.all_head_size = self.num_attention_heads * self.attention_head_size
self.query = nn.Linear(config.hidden_size, self.all_head_size)
self.key = nn.Linear(config.hidden_size, self.all_head_size)
self.value = nn.Linear(config.hidden_size, self.all_head_size)
self.dropout = nn.Dropout(config.attention_probs_dropout_prob)
self.position_embedding_type = position_embedding_type or getattr(
config, "position_embedding_type", "absolute"
)
if self.position_embedding_type == "relative_key" or self.position_embedding_type == "relative_key_query":
self.max_position_embeddings = config.max_position_embeddings
self.distance_embedding = nn.Embedding(2 * config.max_position_embeddings - 1, self.attention_head_size)
self.is_decoder = config.is_decoder
def transpose_for_scores(self, x: torch.Tensor) -> torch.Tensor:
new_x_shape = x.size()[:-1] + (self.num_attention_heads, self.attention_head_size)
x = x.view(new_x_shape)
return x.permute(0, 2, 1, 3)
def forward(
self,
hidden_states: torch.Tensor,
attention_mask: Optional[torch.FloatTensor] = None,
head_mask: Optional[torch.FloatTensor] = None,
encoder_hidden_states: Optional[torch.FloatTensor] = None,
encoder_attention_mask: Optional[torch.FloatTensor] = None,
past_key_value: Optional[Tuple[Tuple[torch.FloatTensor]]] = None,
output_attentions: Optional[bool] = False,
) -> Tuple[torch.Tensor]:
mixed_query_layer = self.query(hidden_states)
# If this is instantiated as a cross-attention module, the keys
# and values come from an encoder; the attention mask needs to be
# such that the encoder's padding tokens are not attended to.
is_cross_attention = encoder_hidden_states is not None
if is_cross_attention and past_key_value is not None:
# reuse k,v, cross_attentions
key_layer = past_key_value[0]
value_layer = past_key_value[1]
attention_mask = encoder_attention_mask
elif is_cross_attention:
key_layer = self.transpose_for_scores(self.key(encoder_hidden_states))
value_layer = self.transpose_for_scores(self.value(encoder_hidden_states))
attention_mask = encoder_attention_mask
elif past_key_value is not None:
key_layer = self.transpose_for_scores(self.key(hidden_states))
value_layer = self.transpose_for_scores(self.value(hidden_states))
key_layer = torch.cat([past_key_value[0], key_layer], dim=2)
value_layer = torch.cat([past_key_value[1], value_layer], dim=2)
else:
key_layer = self.transpose_for_scores(self.key(hidden_states))
value_layer = self.transpose_for_scores(self.value(hidden_states))
query_layer = self.transpose_for_scores(mixed_query_layer)
use_cache = past_key_value is not None
if self.is_decoder:
# if cross_attention save Tuple(torch.Tensor, torch.Tensor) of all cross attention key/value_states.
# Further calls to cross_attention layer can then reuse all cross-attention
# key/value_states (first "if" case)
# if uni-directional self-attention (decoder) save Tuple(torch.Tensor, torch.Tensor) of
# all previous decoder key/value_states. Further calls to uni-directional self-attention
# can concat previous decoder key/value_states to current projected key/value_states (third "elif" case)
# if encoder bi-directional self-attention `past_key_value` is always `None`
past_key_value = (key_layer, value_layer)
# Take the dot product between "query" and "key" to get the raw attention scores.
attention_scores = torch.matmul(query_layer, key_layer.transpose(-1, -2))
if self.position_embedding_type == "relative_key" or self.position_embedding_type == "relative_key_query":
query_length, key_length = query_layer.shape[2], key_layer.shape[2]
if use_cache:
position_ids_l = torch.tensor(key_length - 1, dtype=torch.long, device=hidden_states.device).view(
-1, 1
)
else:
position_ids_l = torch.arange(query_length, dtype=torch.long, device=hidden_states.device).view(-1, 1)
position_ids_r = torch.arange(key_length, dtype=torch.long, device=hidden_states.device).view(1, -1)
distance = position_ids_l - position_ids_r
positional_embedding = self.distance_embedding(distance + self.max_position_embeddings - 1)
positional_embedding = positional_embedding.to(dtype=query_layer.dtype) # fp16 compatibility
if self.position_embedding_type == "relative_key":
relative_position_scores = torch.einsum("bhld,lrd->bhlr", query_layer, positional_embedding)
attention_scores = attention_scores + relative_position_scores
elif self.position_embedding_type == "relative_key_query":
relative_position_scores_query = torch.einsum("bhld,lrd->bhlr", query_layer, positional_embedding)
relative_position_scores_key = torch.einsum("bhrd,lrd->bhlr", key_layer, positional_embedding)
attention_scores = attention_scores + relative_position_scores_query + relative_position_scores_key
attention_scores = attention_scores / math.sqrt(self.attention_head_size)
if attention_mask is not None:
# Apply the attention mask is (precomputed for all layers in BertModel forward() function)
attention_scores = attention_scores + attention_mask
# Normalize the attention scores to probabilities.
attention_probs = nn.functional.softmax(attention_scores, dim=-1)
# This is actually dropping out entire tokens to attend to, which might
# seem a bit unusual, but is taken from the original Transformer paper.
attention_probs = self.dropout(attention_probs)
# Mask heads if we want to
if head_mask is not None:
attention_probs = attention_probs * head_mask
context_layer = torch.matmul(attention_probs, value_layer)
context_layer = context_layer.permute(0, 2, 1, 3).contiguous()
new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)
context_layer = context_layer.view(new_context_layer_shape)
outputs = (context_layer, attention_probs) if output_attentions else (context_layer,)
if self.is_decoder:
outputs = outputs + (past_key_value,)
return outputs
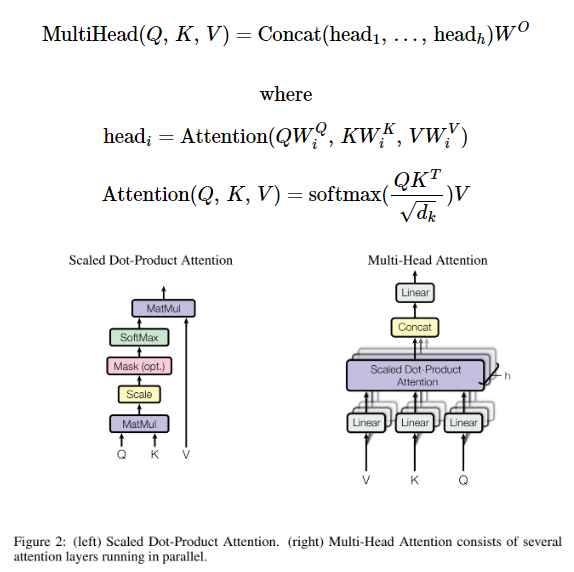
BertSelfAttention 모듈은 hidden_states($X$) = (batch_size, sequence_length, hidden_size)를 입력으로 받는다.
입력으로 받은 hidden_states를 torch.nn.Linear로 구현된 query layer, key layer, value layer에 넣어 Q, K, V를 얻는다.
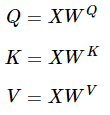
$W^{Q}$, $W^{K}$, $W^{V}$는 (hidden_size, hidden_size)인 가중치 배열이므로
$Q$, $K$, $V$는 (batch_size, sequence_length, hidden_size)가 된다.
multi-head attention 연산을 위해 $Q$, $K$, $V$를 num_attention_heads 개로 나눈다.
코드에서는 def transpose_for_score() 메소드를 이용하여 이를 구현하였다.
이 메서드는 (batch_size, sequence_length, hidden_size) → (batch_size, num_attention_heads, sequence_length, hidden_size / num_attention_heads)로 차원을 변환시켜준다.
$Q$, $K$, $V$를 구한 후에는 Q와 K 간의 scaled dot prodcut attention score를 계산한다.
결과값은 (batch_size, num_attention_heads, sequence_length, sequence_length)가 된다.
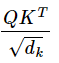
attention_scores = torch.matmul(query_layer, key_layer.transpose(-1, -2))
...
attention_scores = attention_scores / math.sqrt(self.attention_head_size)
그 다음에는 attention mask를 이용하여 attention 연산을 수행하지 않을 token들에 대해서 masking 처리를 해준다.
if attention_mask is not None:
# Apply the attention mask is (precomputed for all layers in BertModel forward() function)
attention_scores = attention_scores + attention_mask
attention mask는 BertModel의 get_extended_attention_mask 메소드의 출력값인 extended_attention_mask 값이다.
get_extended_attention_mask 메소드는 tokenizer가 만든 attention_mask를 입력받아 차원을 맞춰주고
0인 값에는 torch.finfo(dtype).min을, 1인 값에는 0으로 변환해준다.
(torch.finfo(dtype).min은 모델이 다루는 데이터 타입(dtype)에서 표현할 수 있는 가장 작은 값을 나타내는 값이다. 사실상 음의 무한대(-∞)를 의미한다고 보면 된다. 해당 값에 softmax 연산을 수행하면 모두 0으로 죽기 때문에 masking이 된다.)
def get_extended_attention_mask(
self, attention_mask: Tensor, input_shape: Tuple[int], device: device = None, dtype: torch.float = None
) -> Tensor:
"""
Makes broadcastable attention and causal masks so that future and masked tokens are ignored.
Arguments:
attention_mask (`torch.Tensor`):
Mask with ones indicating tokens to attend to, zeros for tokens to ignore.
input_shape (`Tuple[int]`):
The shape of the input to the model.
Returns:
`torch.Tensor` The extended attention mask, with a the same dtype as `attention_mask.dtype`.
"""
if dtype is None:
dtype = self.dtype
if not (attention_mask.dim() == 2 and self.config.is_decoder):
# show warning only if it won't be shown in `create_extended_attention_mask_for_decoder`
if device is not None:
warnings.warn(
"The `device` argument is deprecated and will be removed in v5 of Transformers.", FutureWarning
)
# We can provide a self-attention mask of dimensions [batch_size, from_seq_length, to_seq_length]
# ourselves in which case we just need to make it broadcastable to all heads.
if attention_mask.dim() == 3:
extended_attention_mask = attention_mask[:, None, :, :]
elif attention_mask.dim() == 2:
# Provided a padding mask of dimensions [batch_size, seq_length]
# - if the model is a decoder, apply a causal mask in addition to the padding mask
# - if the model is an encoder, make the mask broadcastable to [batch_size, num_heads, seq_length, seq_length]
if self.config.is_decoder:
extended_attention_mask = ModuleUtilsMixin.create_extended_attention_mask_for_decoder(
input_shape, attention_mask, device
)
else:
extended_attention_mask = attention_mask[:, None, None, :]
else:
raise ValueError(
f"Wrong shape for input_ids (shape {input_shape}) or attention_mask (shape {attention_mask.shape})"
)
# Since attention_mask is 1.0 for positions we want to attend and 0.0 for
# masked positions, this operation will create a tensor which is 0.0 for
# positions we want to attend and -10000.0 for masked positions.
# Since we are adding it to the raw scores before the softmax, this is
# effectively the same as removing these entirely.
extended_attention_mask = extended_attention_mask.to(dtype=dtype) # fp16 compatibility
extended_attention_mask = (1.0 - extended_attention_mask) * torch.finfo(dtype).min
return extended_attention_mask
다시 BertSelfAttention으로 돌아와서 masking된 attention_score에 softmax 연산을 적용하여 attention_probs를 얻는다.
attention_probs = nn.functional.softmax(attention_scores, dim=-1)
구한 attention_probs를 가지고 V를 곱하여 attention value를 계산한다.
(batch_size, num_attention_heads, sequence_length, hidden_size / num_attention_heads)
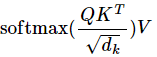
context_layer = torch.matmul(attention_probs, value_layer)
이렇게 각 attention head에서 attention 연산이 끝나면 각 attention head의 attention value들을 다시 합친다.
(batch_size, sequence_length, hidden_size)
context_layer = context_layer.permute(0, 2, 1, 3).contiguous()
new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)
context_layer = context_layer.view(new_context_layer_shape)
2.2.1.1.2 BertSelfOutput
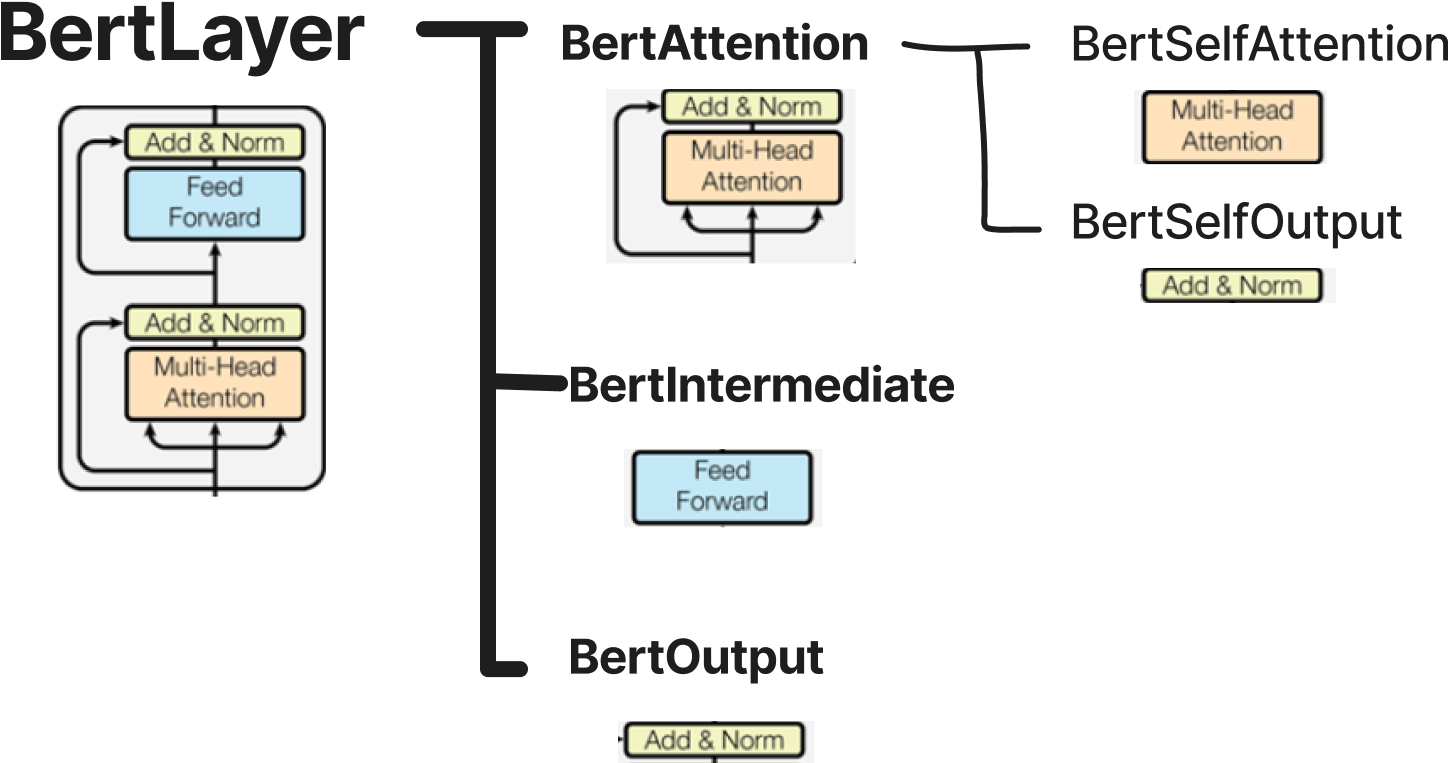
BertSelfAttention으로 부터 구해진 값에 BertSelfOutput을 통해 (hidden_size, hidden_size) 행렬을 곱해주는 linear연산을 진행해준다.
input_tensor라는 이름의 인자로 받는 multi-head self attention 연산을 수행하기 전의 원본 hidden_states와 더해져 (residual connection) LayerNorm을 수행한다.
class BertSelfOutput(nn.Module):
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.hidden_size, config.hidden_size)
self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
def forward(self, hidden_states: torch.Tensor, input_tensor: torch.Tensor) -> torch.Tensor:
hidden_states = self.dense(hidden_states)
hidden_states = self.dropout(hidden_states)
hidden_states = self.LayerNorm(hidden_states + input_tensor)
return hidden_states
2.2.1.2 BertIntermediate
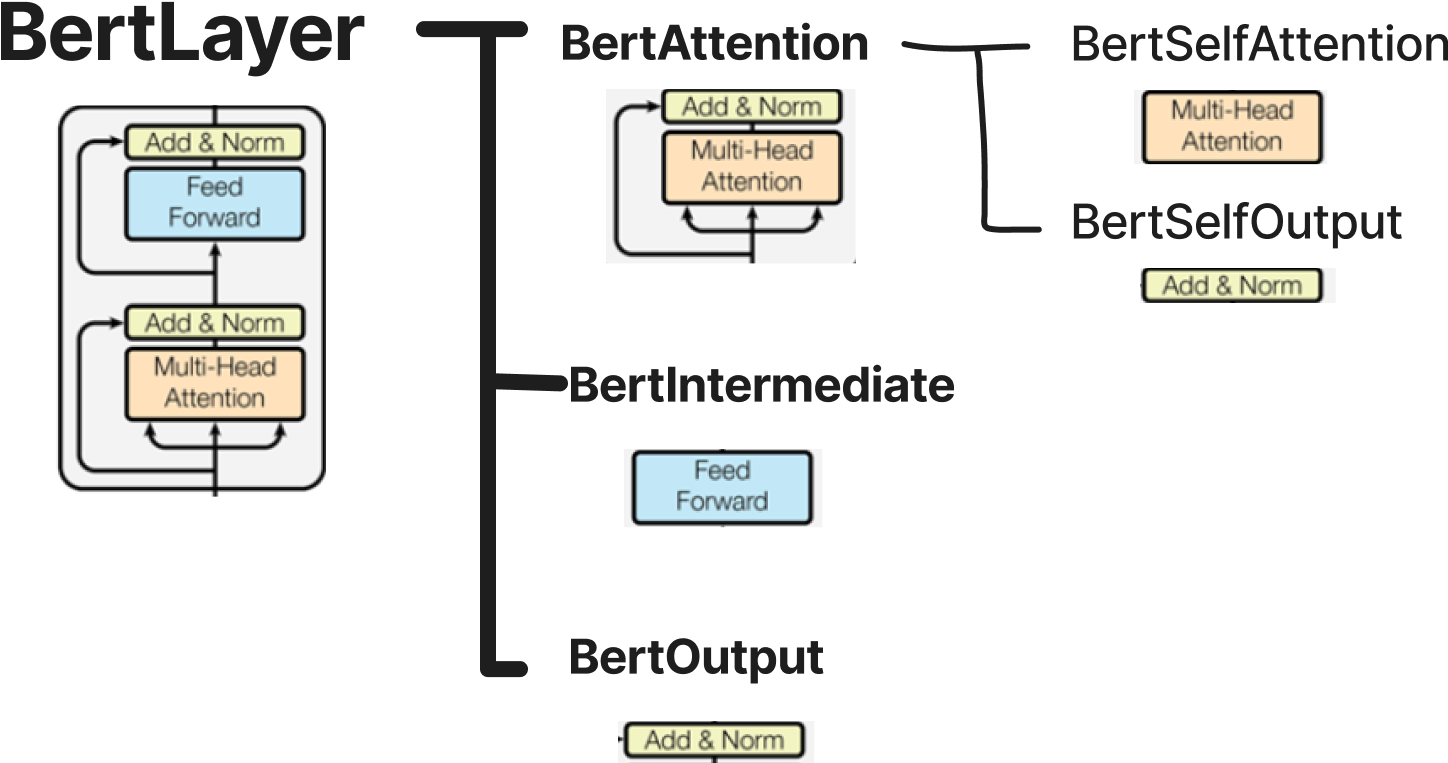
BertIntermediate는 linear 연산을 진행 후 activation 함수를 적용하는 feed foward 블록이다
(batch_size, sequnece_length, hidden_size) → dense layer → (batch_size, sequence_length, intermediate_size)
class BertIntermediate(nn.Module):
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.hidden_size, config.intermediate_size)
if isinstance(config.hidden_act, str):
self.intermediate_act_fn = ACT2FN[config.hidden_act]
else:
self.intermediate_act_fn = config.hidden_act
def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
hidden_states = self.dense(hidden_states)
hidden_states = self.intermediate_act_fn(hidden_states)
return hidden_states
2.2.1.3 BertOutput
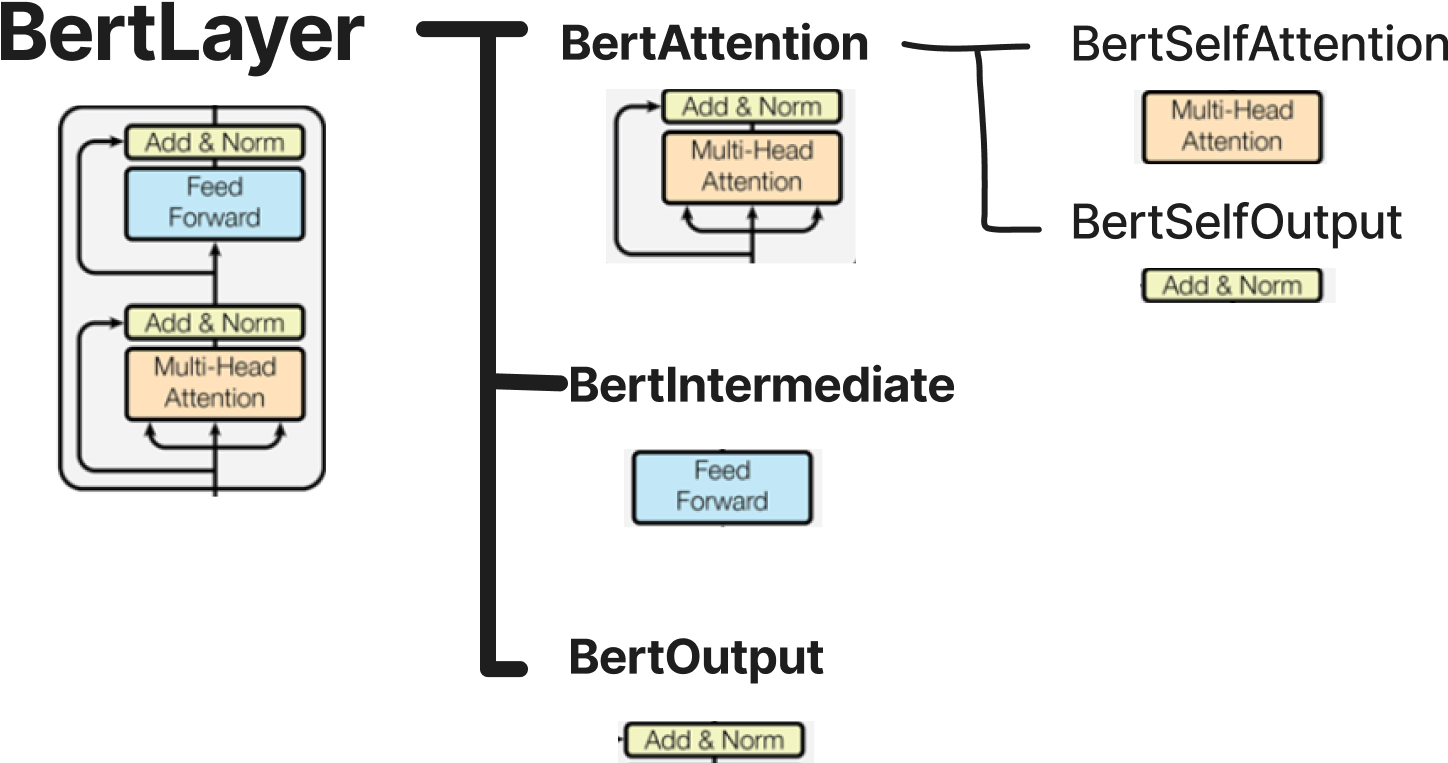
BertOutput은 Add&Norm 블럭이다.
BertIntermediate 으로 부터 출력된 값인 (batch_size, sequence_length, intermediate_size) → dense layer → (batch_size, sequence_length, hidden_size)로 변환한다.
최종 출력으로는 input_tensor이라는 이름의 인자로 받는, 원본 hidden_states와 더해져(residual connection) layer norm이 수행된다.
class BertOutput(nn.Module):
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.intermediate_size, config.hidden_size)
self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
def forward(self, hidden_states: torch.Tensor, input_tensor: torch.Tensor) -> torch.Tensor:
hidden_states = self.dense(hidden_states)
hidden_states = self.dropout(hidden_states)
hidden_states = self.LayerNorm(hidden_states + input_tensor)
return hidden_states
2.3 BertPooler
BertEncoder에서 얻은 contextual embedding 중 [CLS] token의 embedding만을 뽑아내어 classification task를 위한 텐서로 변환해주는 모듈이다.
BertModel을 로드 시 add_pooling_layer인자에 True를 주어야 동작하는 모듈이다.
입력으로 encoder 모듈이 만든 embedding_output의 첫 번째 요소, 즉 마지막 BertLayer가 출력한 hidden_states를 입력으로 받는다.
# BertModel 모듈
sequence_output = encoder_outputs[0]
pooled_output = self.pooler(sequence_output) if self.pooler is not None else None
forward과정에서 각 batch를 구성하는 sequence들의 첫번째 token([CLS])의 embedding 값을 뽑아낸다. (first_token_tensor)
이 값들에 대해 Linear 연산 후 activation 함수를 적용해 [CLS] token들의 embedding 값들을 모아 만든 (batch_size, hidden_size)크기의 tensor를 return한다.
일반적으로 해당 값은 classification task를 위해 사용된다.
class BertPooler(nn.Module):
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.hidden_size, config.hidden_size)
self.activation = nn.Tanh()
def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
# We "pool" the model by simply taking the hidden state corresponding
# to the first token.
first_token_tensor = hidden_states[:, 0]
pooled_output = self.dense(first_token_tensor)
pooled_output = self.activation(pooled_output)
return pooled_output