부스트캠프 AI Tech 4기
7. Pandas
- -
pandas
panel data 의 줄임말인 pandas는 구조화된 데이터의 처리를 지원하는 파이썬의 라이브러리이다.
Series
- DataFrame중 하나의 Column에 해당하는 데이터의 모음 Object


- 값에 접근하기 위해서는 data의 index를 이용한다.

- data index를 이용하여 값을 할당할 수 도 있다.

dataframe
▮ lambda, map, apply
Series 데이터에도 map을 적용할 수 있다.

- dict나 다른 Series 데이터로 같은 위치의 데이터를 교체하고 없는 값은 NaN으로 교체할 수 있다.


- replace
df.sex.replace({'male':0, 'female':1})
- apply : column 단위로 구할 때 주로 사용한다.
- applymap : 모든 칼럼에 다 적용
f = lambda x : -x
df_info['age'].apply(f)
Groupby

- 1개 이상의 컬럼을 Groupby할 수도 있다.
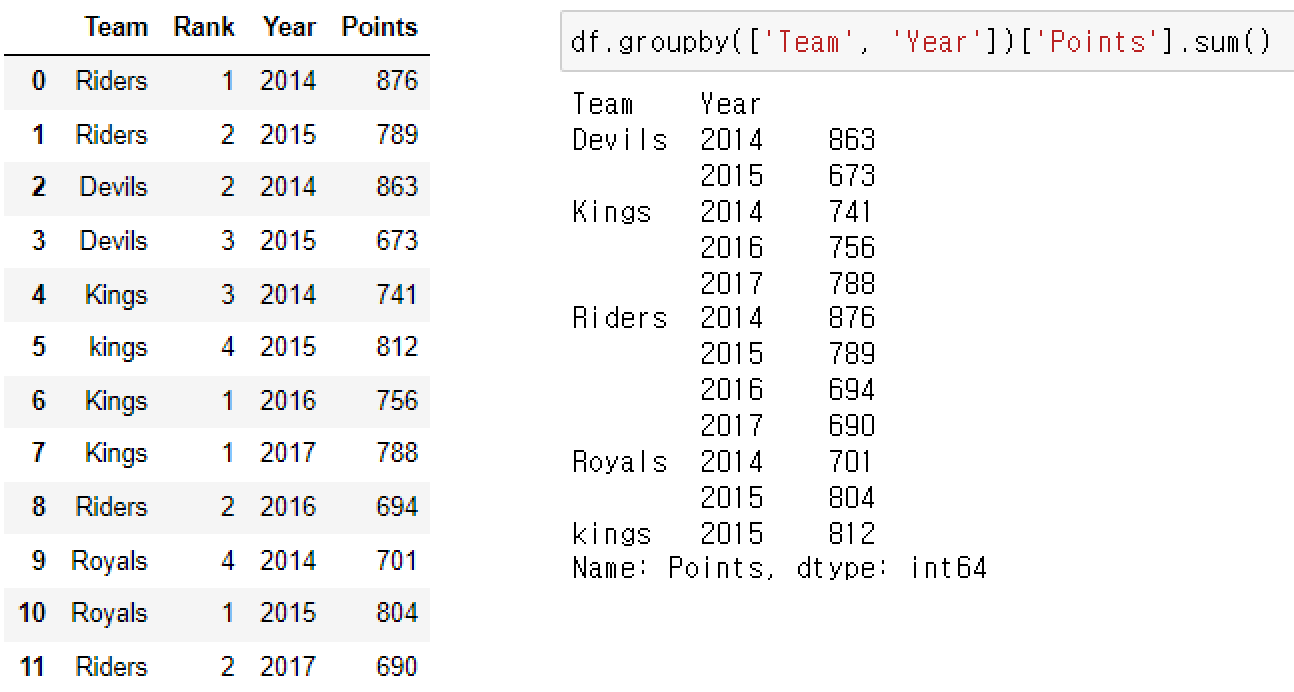
▮ Hierarchical index
- Goupby 명령의 결과물도 결국에는 DataFrame이다.
- 두 개의 column으로 groupby를 할 경우, index가 두 개 생성된다.
unstack()
- Groupby으로 묶여진 데이터를 matrix 형태로 전환해준다.

reset_index()
- Groupby로 묶인 데이터를 다시 풀어준다.

swaplevel()
- Groupby 기준 인덱스의 레벨을 바꾸어준다.

sort_index( ) / sort_values( )
- 지정한 level의 인덱스를 기준으로 인덱스를 sorting한다.
- 값을 기준으로 인덱스를 sorting한다.

▮ grouped
- Groupby에 의해 Split된 상태를 추출 가능하다.
- 특정 key값을 가진 그룹의 정보만 추출 가능하다.

- key, value 상태로 뽑을 수 있는 상태 = grouped 상태
- Tuple 형태로 그룹의 key 값, Value값이 추출할 수 있다.

Aggregation (agg)
- grouped 된 상태에서 컬럼별로 연산을 진행한다.
- 그룹별로 컬럼에 적용요약된 통계정보를 추출해준다. (sum, min)

- 특정 컬럼에 여러개의 function을 apply할 수도 있다.

Transofrmation
- Aggregation과 달리 Key값 별로 요약된 정보가 아니다.
- 개별 데이터의 변환을 지원한다.

- 단, max나 min처럼 Series 데이터에 적용되는 데이터들은 Key값을 기준으로 Grouped된 데이터를 기준으로 반환한다.

filter
- 특정 조건으로 데이터를 검색할 때 사용한다.

Pivot Table
- excel에서의 피벗테이블과 같다.
- index축은 groupby와 동일하다
- column에 추가로 labeling 값을 추가하여 value에 numeric type 값을 aggregation하는 형태이다.


더보기
pivot table을 사용하지 않고 groupby를 사용하고 싶다면
df.groupby(["month", "item", "network"])["duration"].sum().unstack()Crosstab
- 특히 두 column의 교차 빈도, 비율, 덧셈 등을 구할 때 사용한다.
- Pivot table의 특수한 형태
- User-Item Rating Matrix 등을 만들 때 사용가능하다.

merge & concat
- SQL에서 많이 사용하는 Merge와 같은 기능이다.
- 두 개의 데이터를 하나로 합친다.
▮ merge
- on : 공통적으로 있는 컬럼에 대한 merge 진행
pd.merge(df_a, df_b, on = '컬럼명')- 두 df의 column명이 다를 때 사용
pd.merge(df_a, df_b, left_on = '좌측df컬럼명', right_on = '우측df컬럼명')
- how
pd.merge(df_a, df_b, on="subject_id", how="left") # left join → left 쪽의 데이터만 보여주고 없으면 NaN
pd.merge(df_a, df_b, on="subject_id", how="right") # right join
pd.merge(df_a, df_b, on="subject_id", how="outer") # full(outer) join → 양쪽을 다 살림, 빈곳은 NaN # full : 일단 같은거 붙이고, 없는건 정리하여 붙임
pd.merge(df_a, df_b, on="subject_id", how="inner") # inner join (default) 양쪽 다 같은 값이 있을때
- Index based join
컬럼명이 아닌 index를 기준으로 merge할 때 사용한다.
인덱스 값을 기준으로 붙인다.
- 인덱스 값은 지정하지 않았을 경우에 숫자임
- 동일 컬럼명이 존재할 시에 _x, _y가 컬럼명 뒤에 붙는다.
▮ concat
- 같은 형태의 데이터(DataFrame)를 붙이는 연산작업
- merge와 다른 점은 전체를 붙인다는 점에 있다.
df_new = pd.concat([df_a, df_b], axis = 1)
부스트캠프 AI Tech 교육 자료를 참고하였습니다.
728x90
'부스트캠프 AI Tech 4기' 카테고리의 다른 글
| 9. 경사하강법 (1) | 2022.09.23 |
|---|---|
| 8. 벡터와 행렬 (1) | 2022.09.23 |
| 6. Exception/File/Log handling (1) | 2022.09.23 |
| 5. Python data handling (0) | 2022.09.23 |
| 5. Numpy (0) | 2022.09.23 |
Contents