부스트캠프 AI Tech 4기
[NLP] 10. Other Self-supervised Pre-training Models
- -
GPT-2: Language Models are Unsupervised Multi-task Learners
- GPT-1처럼 Pre-training task로 Language Modeling task인 다음 단어를 예측하는 task를 학습한다.
차이점으로는 Transformer 모델의 layer를 점점 더 많이 쌓아서 모델을 키웠다는 점이다. - training 데이터는 40GB으로, 굉장히 훨씬 더 증가된 사이즈의 데이터를 사용하였다.
- 주목할만한 것은 데이터셋을 대규모로 사용하는 과정에서 되도록 퀄리티가 높은 글로부터 효과적으로 다양한 지식을 배울 수 있도록 하는 그런 방식을 유도하였다.
- 여러 down-stream task가 language 생성 task에서의 zero-shot setting으로서 다뤄질 수 있다는 잠재적인 능력도 보여준다.
zero-shot setting이란 원하는 task를 위한 별도의 예제를 주지 않고 task에 대한 지시사항만을 모델에 전달하는 것을 말한다.
GPT-2는 지금까지 주어진 text를 바탕으로 다음 단어를 순차적으로 예측하는 task이다.
아래 그림과 같이 첫 문단이 주어지면 이 문단을 이어받아서 다음 단어 그리고 그 다음 단어를 순차적으로 예측해서 하나의 긴 글을 완성할 수 있는 능력을 갖고 있다.

GPT-2: Datasets
GPT-2의 데이터셋은 좀 더 잘 쓰여진 글로부터 지식을 효과적으로 배울 수 있도록 높은 수준의 글을 선별하여 구성되어있다.
“스파게티를 어떻게 요리해야 맛있게 하나요?” 라고 질문이 있다면 그 밑에 답글들이 존재할텐데 답글들 중에 스파게티를 잘 요리할 수 있는 법을 잘 정리해둔 장문의 잘 쓰여진 글이 있는 외부링크를 포함한 답글이 있을 수 있다.
3개 이상의 좋아요를 받은 답글들 중 외부링크를 포함하는 경우 해당하는 외부링크의 document가 고품질의 잘 쓰여진 text 문서라고 보고 수집하여 데이터셋을 구성하게 된다.
또 다른 기술적인 특징으로는 BERT에 사용된 WordPiece와 비슷하게 Byte pair encoding이라는 sub-word 레벨의 word embedding 을 도출해주고 사전을 구축해줄 수 있는 알고리즘을 사용한다.
GPT-2: Model
transformer 모델의 self-attention blcok과 GPT-2에서 사용된 attention block을 비교 해보면

- Layer normalization layer가 Residual처럼 하위 블록의 입력으로 위치가 변경되었다.
- 각 layer들을 random initialization 할 때 layer가 위로가면 갈수록(더 깊을수록) layer의 index에 비례해서 혹은 반비례해서 initialization되는 값을 더 작은 값으로 만든다. (1/√n 배,n은 residual layer의 수)
→ layer가 위쪽으로 가면 갈 수록 거기서 쓰이는 여러 선형변환에 해당하는 값들이 점점 더 0에 가까워 지도록 하여 위쪽에 있는 layer가 하는 역할이 점점 더 줄어들 수 있도록 모델을 구성하였다.
GPT-3
- GPT-3 는 앞서 봤던 GPT-2 를 개선한 모델이다.
- 개선의 방향은 모델 구조 측면에서의 특별한 점이 있다기 보다는 기존의 있었던 GPT-2의 파라미터 숫자들에 비해서 비교할 수 없을 정도로 훨씬 더 많은 파라미터수를 가지도록 Transformer의 self-attention block을 많이 쌓았다.
- 또한 더 많은 데이터 그리고 더 큰 배치사이즈를 통해 학습을 진행했더니 성능이 점점 더 계속 좋아지더라 라는 결론을 내게된 모델이다.

GPT-3: Language Models are Few-Shot Learners
- prompt : 모델에 주어진 Prefix
- Zero-shot : 다운스트림 태스크 데이터를 전혀 사용하지 않고 모델이 바로 다운스트림 태스크를 수행
- One-shot : 다운스트림 태스크 데이터를 1 건만 사용한다. 모델은 1건의 데이터가 어떻게 수행되는지 참고한 뒤 다운스트림 태스크를 수행한다. GPT-3 모델 자체를 전혀 변형하지 않고 단지 inference하는 과정 중에 학습 데이터를 example로 제시할 때 Zero-shot setting보다 성능이 더 좋게 나온다.
- Few-shot : 다운스트림 태스크 데이터를 몇 건만 사용한다. 모델은 몇 건의 데이터가 어떻게 수행되는지 참고한 뒤 바로 다운스트림 태스크를 수행한다.

- GPT-3는 모델 사이즈를 점점 더 키우면 키울수록 방금 설명했던 zero-shot, one-shot 그리고 few-shot에서의 성능이 올라가는 갭이 훨씬 더 빠르게 올라가는 것을 보여주는 그래프이다.

ALBERT : A Lite BERT for Self-Supervised Learning of Language Representations
- 경량화된 BERT 모델
- 기존의 BERT 모델을 성능의 큰 하락없이 오히려 성능이 더 좋아지는 형태를 유지하면서도 모델 사이즈는 훨씬 더 줄이고 학습시간도 빠르게 만들고 추가적으로 새로운 변형된 형태의 문장레벨의 Self-supervised learning의 Pre-training task를 제안한 모델이다.
▮ Factorized Embedding Parameterization
BERT나 GPT의 경우 입력으로 "Thinking" "Machines"라는 2개의 단어를 입력으로 주었을 때 각 단어는 임베딩 layer를 통해서 4차원 embedding vector가 되어 Self-attention block에 들어간다고 가정해보자.
BERT나 GPT는 Residual Connection이 있기 때문에 입력으로 들어가게 되는 4 dimension이 유지된다.
따라서 이 dimension이 너무 작다면 정보를 담을 수 있는 공간자체가 굉장히 작이진다는 단점이 있을 수 있고,
dimension이 너무 커지게되면 모델 사이즈도 커지게 되고 연산량도 증가하게되는 단점이 있다.
생각해보면 딥러닝에서 점점 깊이 layer를 통과하는 과정은 점점 더 high-level의 sementically(의미론적으로) 유의미한 정보들을 추출해나가는 과정이다.
Embedding layer(첫번째 layer)의 경우는 각 Word의 정보만을 담고 있는 Embedding 벡터일 것이다. 그리고 Self-attention block의 경우에는 전체 Sequence를 고려한 contextual한 정보까지 담고 있는 벡터일 것이다. 즉, 담고 있는 정보량 자체가 다르기 때문에 embedding layer의 dimension size는 Transformer 단의 layer dimension size보다 작아도 될 것이라고 생각할 수 있다.
⇒ ALBERT : embedding layer의 dimension을 줄이는 추가적인 기법을 제시!

- V = Vocab size
- H = Hidden-state dimension
- E = Word embedding dimension
BERT의 경우 Word Embedding Dimension과 Self-attention block의 Hidden state dimension이 동일해야하는데,
ALBERT는 위 그림처럼 4 dimension보다 더 작은 수인 2 dimension을 갖는 embedding layer를 구성하고, Residual Connection이 성립하는 벡터를 만들어주어야하기 때문에 추가적으로 layer를 하나 더 두어서 word embedding 벡터를 4 dimension으로 늘려준다.
(Embedding 과정을 2개의 Matrix로 나누어서 수행하므로 Factorized Embedding 이라고 한다.)

파라미터 수를 계산해보면 훨씬 그 양이 적어짐을 알 수 있다.
▮ Cross-layer parameter sharing
한 self-attention block에서 학습해야하는 파라미터는 Query, Key, Value 각각의 vector 역할을 하도록 적용되는 선형변환 행렬들이고 Multi-Head를 사용하기 때문에 Head 수가 8개인 경우는 8개의 선형변환 set가 필요하다.
self-attention block을 여러번 쌓게 되는데, self-attention block들은 각각 별개의 파라미터 셋을 갖는다.
ALBERT는 Transformer layer간 같은 Parameter를 공유하여 학습하는 파라미터의 수를 줄이게 된다.
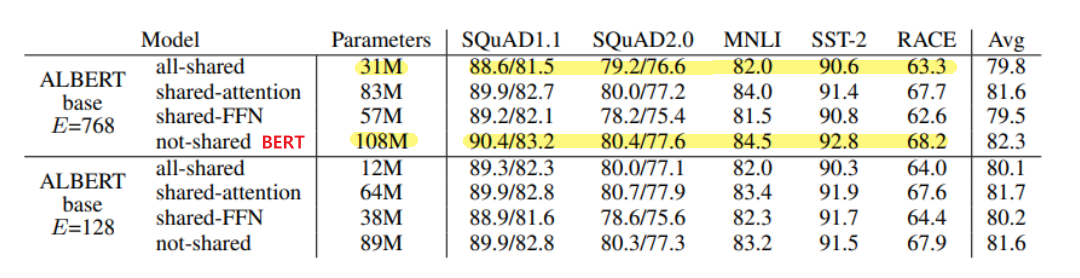
위 표를 살펴보면 FFN과 attention의 파라미터를 모두 share한 모델이 가장 파라미터수는 적으면서 성능에 있어서는 share 되지 않던 original BERT 모델에 비해서 성능의 하락폭이 그렇게 크지 않음을 알 수 있다.
▮ Sentence Order Prediction
BERT의 Pre-training 기법 중 하나인 Next Sentence Prediction은 모델에서 실효성이 많이 없다는 후속 연구들의 지적들이 있었다.
ALBERT는 나은 학습 방식인 Sentence order prediction을 제안하였다.
SOP는 실제 연속인 두 문장(Positive Example)과 두 문장의 순서를 앞뒤로 바꾼 것(Negative Example)으로 구성되고 문장의 순서가 옳은지 여부를 예측하는 방식으로 학습한다.
Next Sentence Prediction의 경우, 첫번째 문서는 정치면에서의 특정기사를 가져오고 두번째 문서는 사회면에서 가져온 기사라면 별개의 두 문서로부터 추출된 두 문장간에는 실제로 내용이 굉장히 상이할 수 있다. 두 문장간에 겹치는 단어들이 거의 존재하지 않기 때문에 이것이 Next Sentence의 관계가 아니다라는 것을 예측하기가 굉장히 쉬울 것이다.
Sentence Order Prediction에서는 동일 문서에서 뽑힌 여전히 인접문장 2개를 사용하되 Next Sentence가 아닌 경우를 여부를 판단하도록 하여 학습 시 두 문장의 연관 관계를 보다 잘 학습할 수 있도록 하였다.

Sentence Order Prediction는 다른 두 케이스보다 유의미하게 더 좋은 성능을 냄을 알 수 있다.
ALBERT : GLUE Results

다양한 task 들에 대해서 BERT, XLNet, RoBERTa 모델들에 비해 ALBERT 모델이 전체적으로 가장 좋은 성능을 내는 것을 알 수 있다.
또한 ALBERT에서도 역시 모델사이즈나 필요로 하는 파라미터수가 더 큰 모델을 사용했을 때 좀 더 좋은 성능을 내는 것을 볼 수 있다. (1M < 1.5M)
ELECTRA: Efficiently Learning an Encoder that Classifies Token Replacements Accurately

- 기존의 BERT 나 GPT-2 등의 모델들과는 조금은 다른 형태로 Pre-training을 한 모델
- 위의 그림을 보면 Maksed Language Modeling 을 수행하는 경우 일부 단어를 [Mask] 토큰으로 치환한 뒤 단어를 복원해주는 모델 Generator를 통해 단어를 복원한다.
그리고서 이 단어가 원래 있었던 단어인지 replaced 된 단어인지를 예측하는 Discriminator라는 두번째 모델을 별도로 둔 형태가 ELECTRA 모델의 가장 핵심적인 특징이다. - 두 모델이 Adversarial Learning의 형태로 학습이 진행된다.
Generator(BERT 모델과 유사한 역할)를 학습을 함으로써 문장을 복원하는 모델을 학습하고
복원된 문장에서 이 단어가 실제로 Masked 된 단어였어서 실제로 replaced 된 단어인지 어떤 단어는 원래 있었던 단어인지에 대한 정보를 알고 있기 때문에, 이 ground-truth 정보를 통해서 두번째 network 인 Discriminator를 학습한다.
위 과정을 반복적으로 수행함으로써 Discriminator를 고도화 시킬 수 있다. - Pre-training을 마친 후에는 Discriminator 모델을 down-stream task들에 fine-tuning한 형태로 사용한다.

ELECTRA 모델 같은 경우는 다른 모델과 비교했을 때 같은 Pre-training 계산량에 비해 더 좋은 성능을 보여준다.
Light-weight Models
- BERT, GPT-2, GPT-3, ELECTRA 등의 모델들은 self-attention block을 점점 더 많이 쌓음으로써 점점 더 좋은 성능을 낼 수 있었지만 Pre-training하는데에 많은 GPU resource와 학습시간 혹은 계산량이 필요하기 때문에 실제로 서비스하기에는 어려움이 있다.
따라서 굉장히 비대해진 모델을 좀 더 적은 layer 수나 적은 파라미터수를 가지는 형태의 경량화된 모델로 발전시키는 연구들이 진행되고 있다. - 경량화 모델의 연구 추세는 기존의 큰 사이즈의 모델이 가지던 성능을 최대한 유지하면서도 이 모델의 크기와 그리고 모델의 계산속도를 빠르게 하는것에 초점이 맞추어져 있다.
- 경량화된 모델은 클라우드 서버나 고성능의 GPU resource 를 사용하지 않고서도 가령 휴대폰 등의 소형 디바이스에서도 이러한 모델을 load 해서 더 적은 양의 전력소모 혹은 배터리 소모량으로 빠르게 계산을 수행하고자 할 때에 주로 사용된다.
DistillBERT
- teacher 모델과 student 모델이라는 것이 있다.
- 말 그대로 teacher 모델은 student 모델을 가르치는 역할이다.
- student 모델은 teacher 모델에 비해서 layer 수나 여러가지 파라미터 측면에서 더 작은 경량화된 형태의 모델로 설계되어 있어서 훨씬 더 큰 사이즈의 모델인 teacher 모델이 내는 output을 잘 모사할 수 있도록 학습을 진행한다. → Knowledge Distillation
- Knowledge Distillation이라는 개념을 사용한 것을 BERT에 적용해서 모델을 경량화시킨 모델을 DistillBERT라고 한다.
TinyBERT
- 마찬가지로 teacher 모델 그리고 student 모델이 존재한다.
- 그러나 DistillBERT처럼 target distribution을 ground-truth로 모사하여 softmax loss를 통해 학습하는 것 뿐만아니라 Embedding layer, Self-attention의 attention matrix와 결과물로 나오는 hidden state 벡터들까지도(즉, 중간 결과물과 파라미터들까지도) teacher를 닮도록 학습을 진행한다.
- 일반적으로 student 모델은 hidden state vector가 기존 teacher 모델의 hidden state vector의 차원수보다 더 작을 수 있기 때문에 이 차원이 달라짐으로써 벡터가 동일한 차원만큼의 벡터와 유사해지도록 해야한다라는 loss 를 적용하기 어려울 수도 있다.
→ 서로 차원이 다른 hidden state vector 와 최대한 유사해지도록 하고자 하는 loss를 적용하기 위해 teacher 모델의 hidden state vector 가 student 모델의 더 적은 수의 hidden state vector 로 차원이 변환되는 Fully connected layer 하나를 더 두어서 dimension 간의 mismatch 를 해결하였다. - 최종 output 즉, vocabulary 사이즈 만큼의 어떤 softmax output 으로서 나타나는 예측값만 똑같아지도록 학습할 뿐만 아니라 이 중간 결과물들도 teacher와 student network가 최대한 유사해지도록 학습을 진행하는 점이 TinyBERT의 특징이다.
Fusing Knowledge Graph into Language Model
BERT는 주어진 문장이 있을 때 문맥이나 각 단어들간의 어떤 유사도는 잘 파악하지만 주어진 문장에 포함되어 있지 않은 추가적인 정보가 필요한 경우에는 그 정보를 효과적으로 활용하는 능력은 잘 보여주지 못한다.
"꽃을 심기위해서 땅을 팠다” 라는 문장과 “집을 짓기 위해서 땅을 팠다” 라는 문장이 주어져있다고 생각을 해보자.
Question Answering이라는 task 를 예로 들었을 때 “땅을 무슨 도구로 팠을까?” 를 질문으로 한다면 그러면 앞서 말했던 문장에서는 땅을 무엇으로 팠는지에 대한 도구의 정보는 문장내에서는 나타나 있지 않다.
그래서 이러한 질문에 대해 답을 하기 위해서는 담고 있는 정보뿐만 아니라 기본적으로 가지고 있는 외부지식(상식)이 필요하다. 이렇게 이미 알고 있는 여러 상식들이 자연어 처리를 할 때 중요한 요소이다.
이러한 외부정보 혹은 외부지식들이 전통 인공지능 분야에서 Knowledge Graph 라는 형태로 표현이 된다.
땅이라는 개체 그리고 파다라는 행동이라는 개체 이 두가지의 개체를 이어주는 어떤 관계로서 그 도구는 가령 부삽이라는 도구도 있을 수 있고 포크레인 같은 중장비의 도구도 있을 것이다.
그래서 이 세상에 존재하는 다양한 개념이나 개체들을 잘 정의하고 그들간의 관계를 잘 정형화해서 만들어 둔 것이 Knowledge Graph이다.
→ BERT 는 주어진 문장에서 여러 정보들을 잘 추출하지만 외부지식이 필요한 경우에는 취약점을 보이기 때문에 이러한 부분을 Knowledge Graph로 잘 정의하고 이를 어떻게하면 기존에 우리가 하던 BERT 등의 Language Modeling 혹은 Pre-training 모델에 잘 결합해서 외부지식이 필요한 경우에도 다양한 task를 잘 할 수 있을까에 대한 연구가 이어지고 있다.
728x90
'부스트캠프 AI Tech 4기' 카테고리의 다른 글
| [WEEK05 마스터클래스] 주재걸 마스터 (0) | 2022.10.21 |
|---|---|
| [WEEK05] 회고 (2) | 2022.10.21 |
| [NLP] 9. Self-Supervised Pre-Training Models (1) | 2022.10.21 |
| [NLP] 8. Transformer (0) | 2022.10.19 |
| [NLP] 7. Transformer - Scaled Dot-Product Attention (0) | 2022.10.18 |
Contents