부스트캠프 AI Tech 4기
[WEEK06-07] Metric Learning
- -
Metric learning
또한 Supervised Learning은 데이터와 레이블 정보가 함께 주어졌을 때 이 사이의 관계를 학습하기 때문에 양질의 레이블 정보를 충분하게 확보해야지만 이 부분이 매우 어렵다.
반면 Self-Supervised Learning은 자기 자신으로부터 얻은 정보를 활용해 좋은 representation을 할 수 있다.
Metric learning은 Self-Supervised Learning의 한 종류로 레이블 정보가 없어도 관측치끼리의 유사성을 바탕으로 이들을 잘 구분하도록 학습할 수 있다.
일반적인 Classification은 Feature 간의 Decision Boundary를 찾도록 학습한다.(Learn separable features)
Metric Learning은 유사하지 않은 Feature들을 멀리 떨어지도록 학습한다.(Learn Large-Margin features)
즉, 데이터 간의 유사도를 잘 수치화(embedding space)하는 거리 함수(metric function)를 학습한다고 볼 수 있다.
→ Feature 공간을 더 잘 사용할 수 있다.
Contrastive learning
Contrastive learning은 metric learning을 위한 여러 학습 방법 중 하나이다.Contrastive learning은 이름에서 알 수 있듯이 대조군들 (postive pair와 negative pair)를 사용해 Embedding space를 잘 구분할 수 있도록 학습한다.
그렇다면 Contrastive learning을 위해서, 어떤 Loss로 학습할 것인가?
Euclidean-distance 기반 loss
Contrastive Loss
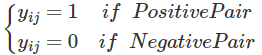


Pos pair는 거리가 0, Neg pair는 거리가 Margin( α )이 되도록 학습을 한다.
그러나 크게 차이나는 Neg Sample이나, 적게 차이나는 Neg Sample이 동일한 Margin( α )으로 차이가 나도록 학습된다는 단점이 있다.
Triplet Loss
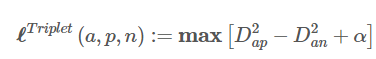

Anchor : 중심이 되는 이미지
Pos : Anchor와 동일한 ID의 이미지
Neg : Anchor와 다른 ID의 이미지
Triplet Loss는 Anchor-Pos와의 거리는 최소화하고 Anchor-Neg와의 거리는 최대화가 되도록 학습한다.
Contrastive는 절대적 거리(마진)을 고려하지만, Triplet Loss는 상대적 거리 차이를 학습할 수 있다.
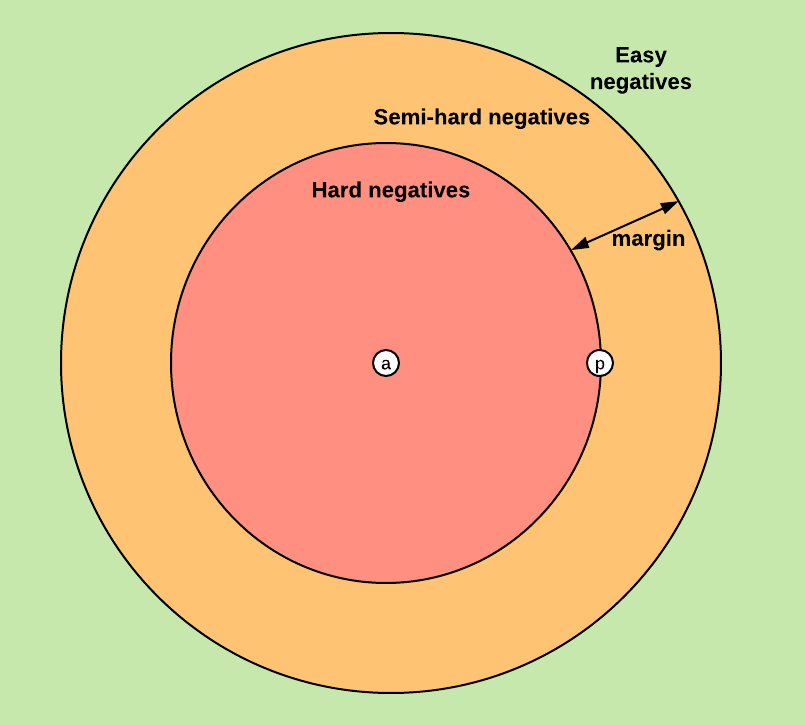
Neg sample을 어떻게 구성하느냐에 따라 세부적으로 3가지로 나눌 수 있다.
Easy Triplet
$ D^{2}_{ap} + \alpha < D^{2}_{an} $
이미 Neg sample이 멀리 떨어져있는 경우로, Anchor와 완전히 다른 데이터를 찾기는 쉽지만 유사한 데이터의 경우는 학습이 필요하다.
Semi-Hard Triplet
$ D^{2}_{ap} < D^{2}_{an} < D^{2}_{ap} + \alpha $
위 그림에서 margin 부분에 위치해 있는 Neg sample을 사용한 학습이다.
Hard Triplet
$ D^{2}_{an} < D^{2}_{ap} $
Pos sample보다 Anchor에 더 가까운 Neg sample을 사용한 학습이다.
negative sample을 잘 구성할 수록, 학습의 결과가 좋아진다.
딥러닝 모델이 헷갈리는 부분은 분명 유사한 샘플이지만 다른 클래스에 속하는 경우이다. 따라서 negative sample들을 anchor와 유사하게 구성할 수 록 더 좋은 방향으로 학습이 될 수 있다.
그러나 학습에 좋은 (즉, 어려운) pair/triplet을 구성하는 것이 어려운 부분이다.
728x90
'부스트캠프 AI Tech 4기' 카테고리의 다른 글
| [Product Serving 개론] 1.MLOps 개론 (0) | 2022.11.07 |
|---|---|
| [WEEK06-07] 의미 유사도 판별(Semantic Text Similarity, STS) 대회 Wrap-up 및 회고 (0) | 2022.11.03 |
| [WEEK06-07] Data EDA (0) | 2022.10.26 |
| [WEEK05 마스터클래스] 주재걸 마스터 (0) | 2022.10.21 |
| [WEEK05] 회고 (2) | 2022.10.21 |
Contents