부스트캠프 AI Tech 4기
[NLP 데이터 제작] 3. 원시 데이터의 수집과 가공
- -
1. 원시 데이터의 수집과 가공
1.1 원시 데이터의 정의
1.2 원시 데이터 수집 시 고려 사항
1.3 원시 데이터 전처리
1.4 원시 데이터의 가공 - 주석 도구
1. 원시 데이터의 수집과 가공
1.1 원시 데이터의 정의
▮ 원시 데이터란?
- 과제를 해결하기 위해 특정 도메인, 장르, 주제 등에 대하여 조건에 맞춰 수집하였으나, 주석 단계를 거치지 않은 상태의 데이터
- 원하는 형태로 가공하기 이전의 데이터로 목적에 맞는 전처리 과정을 거쳐 가공이 되어야 활용할 수 있음
▮ 원시 텍스트 수집 시 검토 사항

▮ 원시 데이터의 종류
- 웹스크래핑
- 직접 사람들이 만들어서 입력하는 방식
- 모델을 통해서 생성하는 방법
- 모두의 말뭉치, AI Hub 등의 기존의 데이터를 활용하는 방안
▮ 원시 텍스트 데이터 사용역(장르)에 따른 분류
- 문어
신문기사, 소설, 수필, 논문, 잡지, 보고서 등 - 구어 (음성 파일을 텍스트로 전사)
일상 대화, 연설, 강연
준구어 : 방송 대본, 영화 대본 등 - 웹
SNS, 커뮤니티 게시판, 메신저 대화, 블로그, 이메일 등
▮ 원시 텍스트 데이터의 메타 정보
- 텍스트 외에 텍스트를 설명하는 정보
- 텍스트 ID, 이름, 저장 정보, 매체 정보, 주석 정보, 출처, 형태/구문 분석 정보 등을 사전에 정해진 양식에 맞춰 기록
- NIA 텍스트 데이터 메타 정보 예시
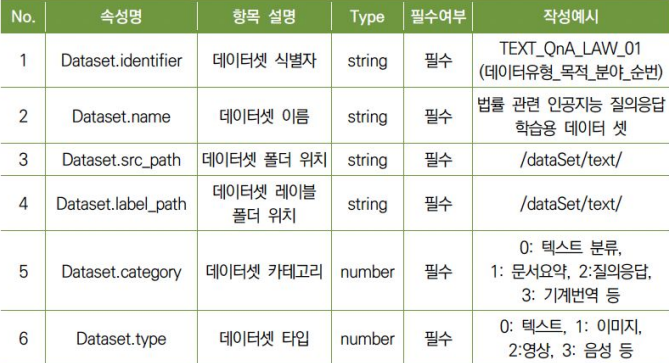
1.2 원시 데이터 수집 시 고려 사항
획득 가능성
- 획득이 불가능하거나 통제 불가능한 주기를 가지고 있다면 원시데이터의 정책에 의존하게 되므로 바람직하지 않음
- 획득이 용이하더라도 서비스 활용 측면에서 데이터를 활용하기 위해 가공 처리에 많은 비용이 드는 데이터는 선정하기 어려움
- 직접 산출이 어려운 경우 획득 난이도 측면에서 트래픽량과 저장처리 장치의 용량 등을 고려 대상, 획득 대상의 대안 필요
데이터 균형과 다양성
- 개체의 다양성, 목적 및 상황의 다양성, 시간별, 종류별, 사람별, 지역별 다양성
신뢰성
- 데이터의 품질이 신뢰할 수 있는지 검토
법 제도 준수

- 개인정보 및 사생활 보호가 필요한 항목 획득 시, 개인정보보호법 등에 따라 적절한 법적, 기술적 절차를 거친 데이터를 활용하며, 그렇지 않은 데이터는 정제 과정에서 처리될 수 있도록 함
- 정규표현식이 굉장히 유용
저작권
- 원시 데이터에 주석 작업을 하는 경우, 결과물은 2차적 저작물로 간주되며 라이센스는 원시 데이터를 따름
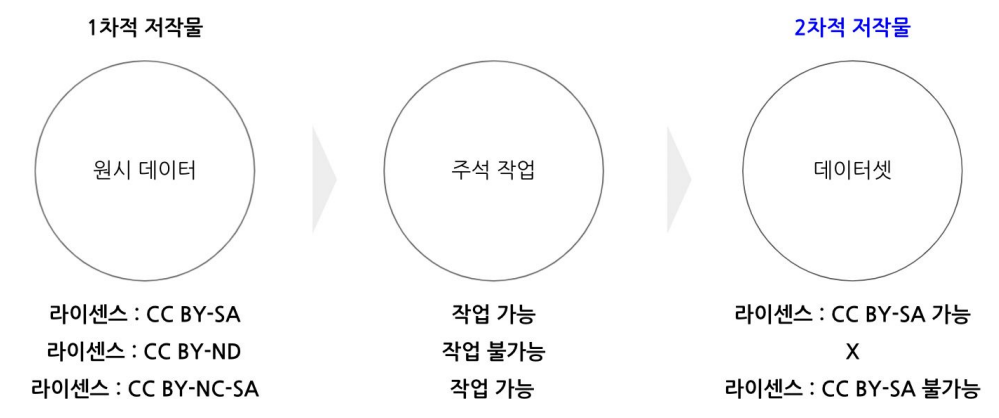
- CC BY-SA : 동일조건 변경 허락
- CC BY-ND : 변경 금지
- CC BY-NC-SA : 비영리인 경우 동일조건 허락
1.3 원시 데이터 전처리
▮ 전처리 단계
추출 대상 확인
- 메타 정보
- 주석 대상 텍스트
- 주석 대상 표현 포함 텍스트 여부
- 텍스트 길이 범위
불필요 요소 제거 및 변환
- 개인정보 비식별화
- 비윤리적 표현 정제
정제 대상 확인
- 숫자, 외국어, 기호, 이모지
- 띄어쓰기, 맞춤법, 오탈자
- 개인 정보
- 문장 분리
말뭉치 정제 기준 예시

요즘의 트렌드는 엄밀하게 정제하지는 않는것 같음
1.4 원시 데이터의 가공 - 주석 도구
원시 데이터의 가공
▮ 주석(annotation, labeling)
- 원시 데이터를 가공하여 원하는 정보를 부착하는 작업
- 텍스트를 단순히 분류하여(긍부정, 주제) 해당 분류를 텍스트에 삽입하거나 개체명, 관계 정보 등의 정보를 문자열에 직접 주석할 수 있음
- 주석 시에는 다양한 도구(tool)가 사용됨
주석 도구의 종류
▮ 구글 스프레드 시트
- 여러 명의 작업자 동시 작업 가능, 작업과 동시에 저장, 데이터 관리 용이
- csv 형식으로 export 가능
▮ 구글 폼
- 단순 분류 문제 등 복잡한 주석 도구가 필요하지 않은 경우에 적합
- 결과를 구글 스프레드 시트로 확인할 수 있음
- 작업자 모집에도 활용
▮ Doccano
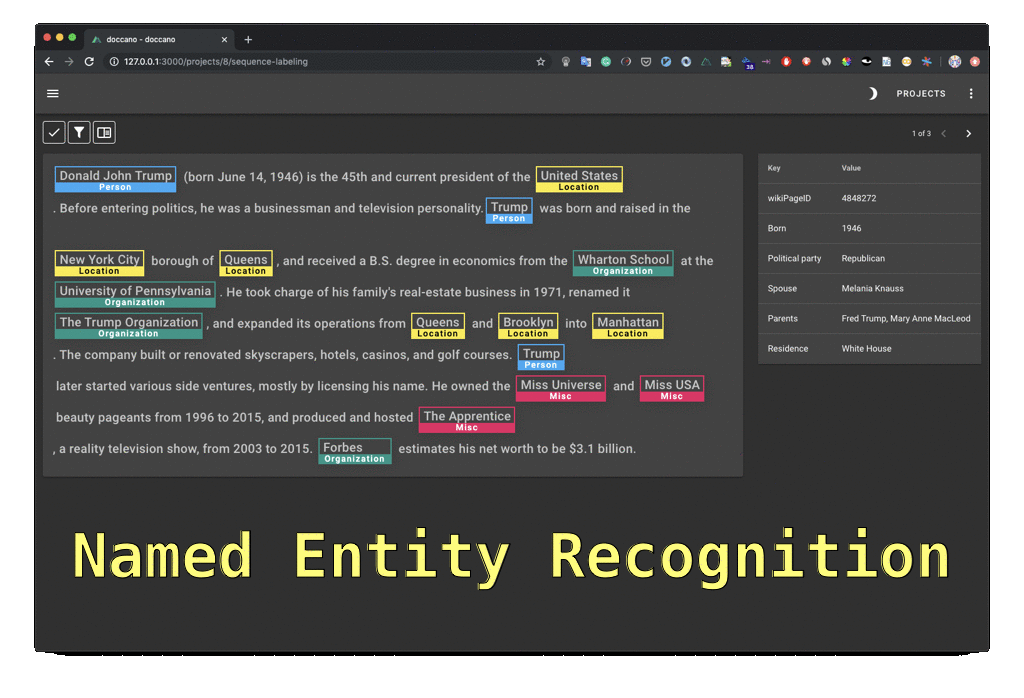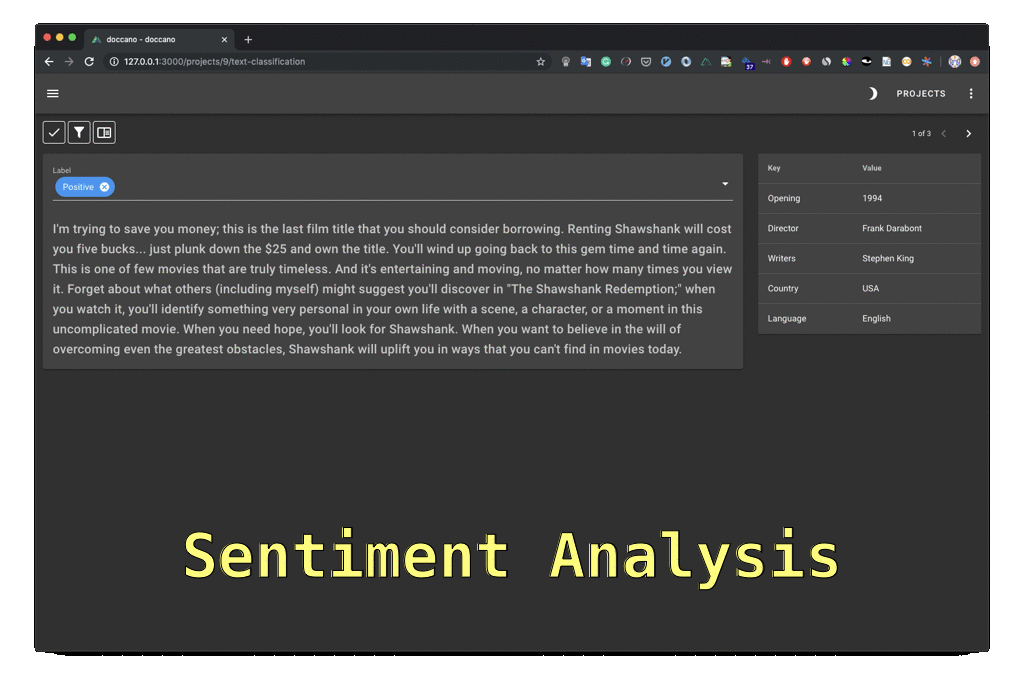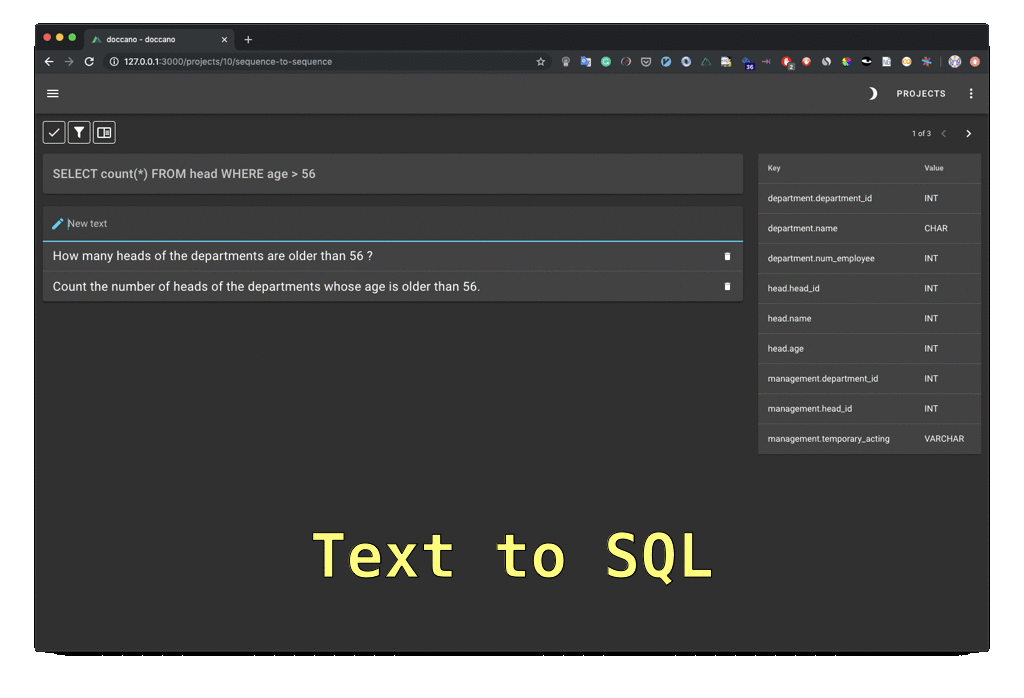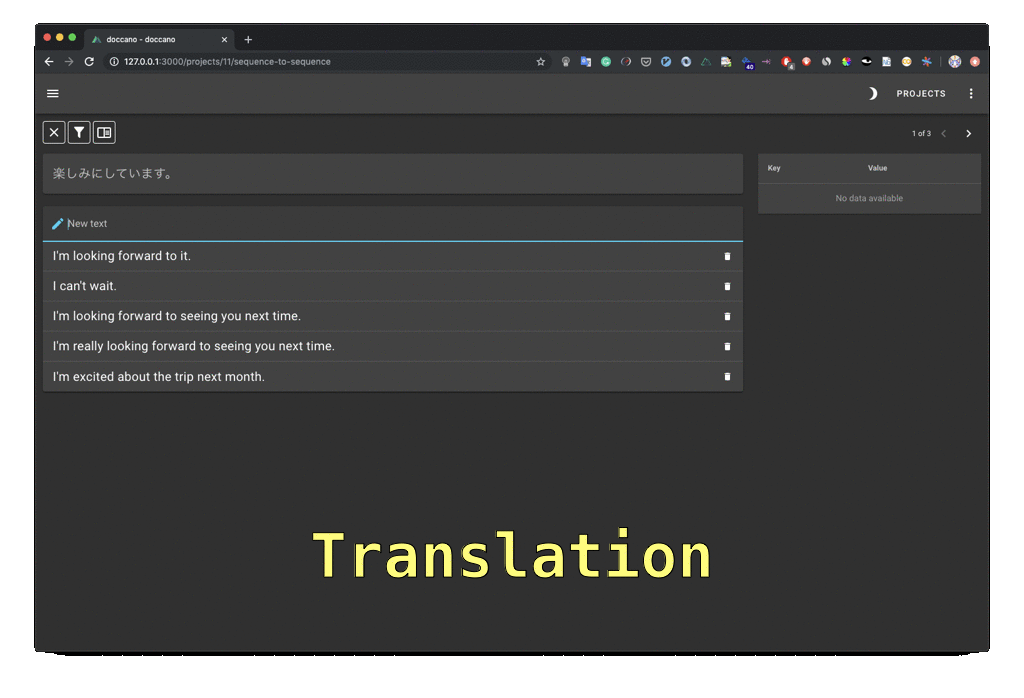
- NER, 감성분석, 기계 번역 등 주석 기능 제공
- 서버 또는 로컬에 설치하여 사용
- https://doccano.github.io/doccano/
▮ Tagtog
- 웹 기반 주석 도구
- 다양한 형식 지원
- 무료 이용시 데이터 공개
- https://www.tagtog.com/
Further Reading
- 나만의 웹 크롤러 만들기 시리즈 [Blog]
- 다양한 분야의 개인정보보호 가이드라인 [Site]
728x90
'부스트캠프 AI Tech 4기' 카테고리의 다른 글
| [NLP 데이터 제작] 5. 데이터 구축 가이드라인 작성 기초 (0) | 2022.12.09 |
|---|---|
| [NLP 데이터 제작] 4. 데이터 구축 작업 설계 (0) | 2022.12.09 |
| [NLP 데이터 제작] 2. 자연어처리 데이터의 특성 (1) | 2022.12.09 |
| [NLP 데이터 제작] 1. 데이터 제작의 전체적인 흐름 (0) | 2022.12.09 |
| [WEEK09/10/11] 문장 내 개체간 관계 추출(Relation Extraction, RE) 대회 Wrap-up 및 회고 (1) | 2022.12.09 |
Contents