부스트캠프 AI Tech 4기
[NLP_KLUE] 6. 최신 언어모델 관련 연구 트랜드
- -
1. BERT 이후의 다양한 LM
1.1 XLNet
BERT의 한계점
- BERT는 [MASK]를 통해서 [MASK] 된 문장을 다시 원본으로 복원하는 과정으로 학습이 이루어진다.
→ BERT는 [MASK] 토큰을 독립적으로 예측하게 된다.
→ 예측의 대상이 그저 [MASK] 토큰일 뿐인 것이다.
⇒ 따라서 토큰 사이의 관계를 학습하는 것은 불가능하다. - embedding_length의 한계로 512 토큰을 벗어나는 새로운 segment에 대해서는 segment와 segment 의 관계를 학습하는 것이 불가능하다.
GPT-2의 한계점
- 앞의 나온 단어를 바탕으로 다음 토큰이 어떤것이 나올지 예측하는 방법으로 학습한다.
⇒ 따라서 단일 방향성으로만 학습한다는 문제점이 존재한다.
이 두가지 문제점을 보완해서 나온 아이디어가 XLNet 이라는 Language Model이다.
▮ Relative Positional Encoding

XLNet은 BERT의 512토큰 한계점을 벗어나기 위해 positional encoding으로 Relative positional encoding 방식을 사용한다.
BERT는 512 토큰 내에서 절대값을 기준으로 positional encoding을 한다면
XLNet 같은 경우에는 현재 토큰의 위치대비 0번째, 1번째, 2번째 같이 상대적 거리 표현법을 바탕으로 positional encoding 을 한다. → sequence의 길이 제한이 없어진다는 장점이 있다.
▮ Permutation language modeling

MASK 토큰을 사용하지 않고 Permutation language modeling이라는 방법으로 학습을 진행한다.
위 그림처럼 기존 모델은 “발” 다음에 “없는”이 나오고 그 다음에 “말이” 나오듯이 단어를 순차적으로 예측하는 방식으로 학습이 이루어진다.
하지만 XLNet은 순열 조합을 통해서 문장을 학습한다.
예를 들어 “발 없는 말이 천리간다” 라는 sequence가 있을 때 이 sequence 내에 존재하는 모든 토큰들을 순열 조합을 통해서 순서를 모두 섞어버린다. 그리고 그 섞인 순서의 sequence가 학습의 대상이 된다.
위 그림처럼 [발, 없는, 말이, 천리간다]가 [없는, 발, 말이, 천리, 간다] 라는 문장으로 순열이 섞였다고 가정하자.
이 때 XLNet은 이 문장을 정답으로 여기고 “없는”, “발”, “말이” 처럼 섞인 순서를 가지고 학습을 하게 된다.
이렇게 순서를 섞었기 때문에 한 방향으로만 학습하게 되는 것을 방지할 수 있다.

1.2 RoBERTa
- BERT보다 Model 학습 시간 증가 + Batch size 증가 + Train data 증가
- Next Sentence Prediction 제거
→ Fine-tuning과 관계가 없고 해당 task는 너무 쉬운 문제라 오히려 성능 하락의 문제를 야기할 수 있다. - 좀 더 긴 sequence를 사용할 수 있다.
- Daynamic masking → 똑같은 텍스트 데이터에 대해 masking을 10번 다르게 적용하여 학습
1.3 BART

BART는 Transformer의 Encoder와 Deocoder를 하나로 합쳐서 만든 통합 LM이다.
기존의 GPT같은 경우에는 Next Token 을 예측하게 되어있고 BERT는 Mask 된 토큰을 예측하도록 학습한다.
BART는 다양한 학습 방법을 사용한다.
Token Masking한 것을 올바르게 예측하는 방법도 사용하고 Sentence를 Permutation한 다음에 올바른 순열을 만들도록 예측하는 것도 학습한다.
또한 문서 자체의 token을 ratation 해서 rotation 한 것을 올바르게 맞추는 것도 진행하였다.
기존의 MASK를 예측하는 것만 만들었던게 BERT라면 BART라는 모델은 온갖 어려운 task 들을 한꺼번에 예측할 수 있게 만들어놓은 것이고 이런 다양하고 복잡한 방법을 통해 언어를 좀 더 정확하게 학습할 수 있다고 한다.

1.4 T-5
T-5는 Transformer Encoder-Decoder 통합 LM이다.
T-5 모델은 Pre-training 과정에서 온갖 task 들을 다양하게 학습할 수 있다.
SQuAD 데이터를 통해서 학습하고 GLUE 데이터셋을 이용해 학습하기도 함
T-5 는 학습을 할 때 아래와 같은 Masking 기법을 사용한다.
하나의 토큰을 Masking 하는 것이 아닌 여러 토큰들을 동시에 Masking 하고 학습할 때 여러개의 Multi Mask를 다시 복원하는 과정으로 학습한다.
즉, encoder에서는 input 문장이 들어가게 되고 decoder에서는 target이 들어가 여러 문장을 동시에 복원하는 과정으로 학습을 하게 된다.
→ 훨씬 더 어려운 문제를 학습하게 되는 것

1.5 Meena
Meena는 대화만을 위한 Language Model이다.
아래 그림처럼 한 개의 Transformer 의 Encoder Block과 여러개의 Decoder Block으로 이루어져 있다.

소셜 미디어의 대화 데이터 총 341GB 의 대화 데이터를 사용했고 모델 자체의 사이즈는 26억개의 파라미터를 가지고 있는 end-to-end multi-turn 챗봇이다.
이런 end-to-end generation 챗봇들이 말만 잘한다고 인간답다고 말할 수는 없다.
인공지능 챗봇이 가장 인간다워지려면 인간과 같은 윤리성을 가지고 있어야 한다.
하지만 Generation 모델은 확률론적인 것에 생성을 맡기기 때문에 이런 윤리성을 control 할 방안이 없다.
1.6 Controllable LM
Plug and Play Language Model (PPLM)
일반적으로 Language Model이 다음 답변을 생성을 할 때는 단순히 다음에 등장할 단어에 대해서 확률 분포를 통해서 선택한다.
Plug and Play 모델은 다음에 나오기에 적절한 단어들을 bag of words 에 저장하고 있다.
예를 들어서 긍정의 답변을 원한다면 “좋아”, “그래”, “그렇게 하는게 좋을 것 같아” 와 같은 긍정적인 답변의 예시들을 저장을 해놓는 것이다.

즉, PPLM이 제안하는 방법은 원하는 bag of words의 단어들이 최대 확률로 되도록 이전 상태의 vector를 수정하는 방법이다.
위 그림처럼 Language Model이 “The chicken” 을 생성했다고 가정하자.
그러면 “The chicken” 다음에 Languae Model이 “taste” 라고 예측을 했고 “taste” 다음에 나올 수 있는 확률분포를 봤을 때 “ok” 라는 단어가 최대 확률분포이다.
그러면 “ok” 가 나와야 하는데 우리는 “delicious” 라는게 더 높은 확률로 나오길 바라는 상황이다.
즉, 나의 bag of words에는 “delicious”가 저장되어 있는 상황이다.
내가 가지고 있는 bag of words의 모든 확률 데이터를 현재 상태에 맞춰서 확인을 하게 된다.
그러면 “ok”가 가지고 있는 왼쪽의 그래프보다 나의 확률분포가 더 낮게 나올 것이다.
이 때 내가 가진 bag of words가 최대 확률로 유지될 수 있도록 backpropagation을 통해서 “chicken” 쪽에서 만들어진 vector를 다시 수정한다.
실제 gradient 가 업데이트 되는 것이 아니고 이전의 만들어진 vector 값을 수정함으로써 내가 가진 bag of words 의 단어들이 최대 확률로 되도록 수정하는 것이다.
그래서 최종적으로는 “The chicken tastes” 다음에 “ok” 가 아니라 “delicious” 가 선택될 수 있도록 의도적인 유도를 만들어낸다.
이 모델의 가장 큰 장점은 실제로 gradient update를 필요로 하지 않기 때문에 기존의 학습한 모델을 바탕으로 내가 원하는 단어로 생성하도록 유도할 수 있다는 점이다.
2. Multi-modal Language Model
2.1 LXMBERT
Cross-modal reasoning language model (Learning Cross-Modality Encoder Representations from Transformers)
이 모델은 이미지와 자연어를 동시에 학습하고 동시에 학습된 정보를 하나의 모델로 합침으로써 이미지와 자연어를 하나로 연결할 수 있다.

위 그림의 가장 오른쪽을 보면 Cross-Modality Output이라는 첫번째 토큰을 가져오게 된다. 즉, 이 Cross-Modality Output가 BERT의 [CLS] 토큰 역할이다.
이 토큰이 생성되기 위해서는 자연어의 embedding된 정보와 이미지가 embedding된 정보가 서로 cross가 되어 하나로 합쳐져 만들어져야 한다.
이 모델을 이용해서 자연어가 섞여있는 분류 task 를 시도했더니 성능이 가장 좋게 나왔다고 한다.

위 그림처럼 옆에 이미지가 보이고 이 이미지의 관련된 질문을 자연어로 주게 된다.
“Where is the cat?” 이라고 했을 때 답변으로 “desk” 라고 나옴
이것은 질문에 대한 자연어도 이해하고있고 “cat” 이라고 하는 자연어와 “desk” 라는 자연어간의 관계와 그 이미지에 어떻게 맵핑되는지가 모두 하나의 모델에 반영이 되어있기 때문에 좋은 답변을 만들어 낼 수 있다.
2.2 ViLBERT (BERT for vision-and-language)
이 모델은 BERT 와 구조가 똑같다.

BERT는 일반적으로 문장 1번과 [SEP] 토큰, 문장 2번을 넣는 형식인데
이 모델은 앞에 토큰은 Image 에 대한 embedding vector를 넣고 그 다음에 [SEP] 토큰 다음에는 자연어에 대한 vector를 넣는다.
BERT 입장에서는 Image에 대한 토큰과 자연어에 대한 토큰을 하나로 합쳐서 [CLS] 토큰을 만들어내게 된다.
만들어진 [CLS] 토큰 위에 classification layer를 부착하면 자연어와 이미지가 합쳐져있는 정보를 통해서 분류하는 task 를 수행할 수 있다.

MM-IMDB라는 데이터셋에는 이미지와 text 데이터가 있어서 이 정보를 통해서 주어진 정보가 어떤 장르의 영화인가를 분류하는 task를 진행해볼 수 있다.
이미지만 보고 분류했을 때와 text만 보고 분류했을 때 그리고 이미지와 text를 하나로 합쳐서 분류했을 때 세가지의 task 의 성능을 비교해보면 이미지와 text 를 하나로 합쳐서 분류했을 때 성능이 가장 좋았다고 한다.
2.3 Dall-e
자연어로부터 이미지를 생성할 수 있는 모델이다.
1. VQ-VAE 를 통해 이미지의 차원 축소 학습

이미지를 생성하기 위해서는 이미지 토큰을 학습해야 하는데 이미지 같은 경우에는 예를들어 256 x 256 x 3의 data size를 갖게 된다.
BERT만 하더라도 512 토큰으로 되어있는데 이 이상의 크기로 가면 모델사이즈가 어마어마하게 커지게 된다.
즉, 기존에 있던 LM 이 256 x 256 x 3 의 엄청난 사이즈를 수용하기 힘들 것이다.
그래서 이 이미지를 차원축소하는 방법을 사용하고자 하였다.
차원 축소 방법은 위 그림에서처럼 이미지에 대해 Encoder layer를 거쳐 나오는 latent vector를 이미지 vector로 환산하게 된다.
Dall-e 알고리즘인 VQ-VAE는 위 그림보다는 내부적으로 더 복잡한 방법을 통해서 latent vector를 만들어낸다.
위에서 설명한 것 처럼 큰 이미지에 대해 먼저 차원축소를 했고 그 다음은 GPT-3 의 과정과 똑같다.
2. Autoregressive 형태로 다음 토큰 예측 학습
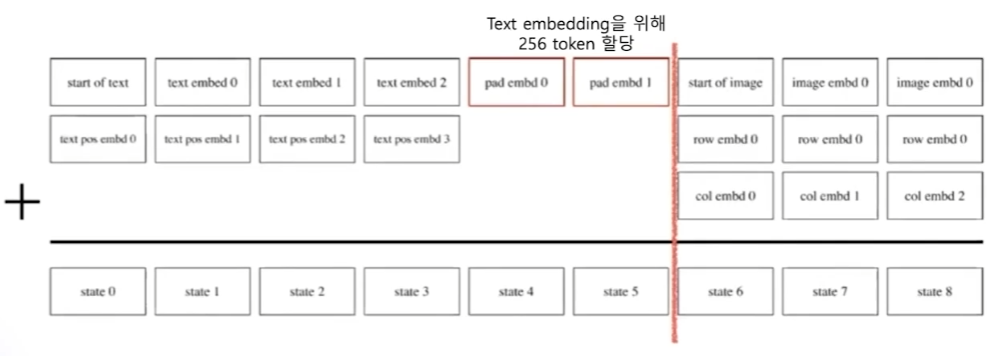
앞 부분에는 text 토큰이 들어가고 이 text를 위해서는 256 토큰을 할당한다.
그래서 256 토큰 동안은 반드시 text가 들어가고 만약에 이걸 못채우면 padding 이 들어간다.
그 다음은 이미지 vector를 생성하도록 하였다.
그래서 GPT와 마찬가지로 text 토큰이 입력으로 들어갔을 때 다음에 이미지 토큰을 생성해내는 방법으로 이미지를 만들어내도록 학습이 되는 것이다.
이렇게만 학습을 했는데도 자연어로 입력을 했을 때 굉장히 그럴듯한 이미지들을 생성해내는 결과를 볼 수 있었다.
728x90
'부스트캠프 AI Tech 4기' 카테고리의 다른 글
| [WEEK9/10/11] TIPS (1) | 2022.12.09 |
|---|---|
| [WEEK9/10/11] Relation Extraction 대회 진행 중의 기록 (0) | 2022.12.09 |
| [NLP_KLUE] 5. GPT (1) | 2022.12.08 |
| [NLP_KLUE] 4. BERT / Huggingface Tokenizer (2) | 2022.11.15 |
| [NLP_KLUE] 3. 한국어 Tokenizing (1) | 2022.11.14 |
Contents