딥러닝/논문 리뷰(GitBook으로 이전)
[Paper Review] Dense Passage Retrieval for Open-Domain Question Answering
- -

Abstract
Open-Domain Question Answering은 후보 context를 선택하기 위한 Passage Retrieval(문단 검색)이 중요하다.
기존에는 TF-IDF나 BM25같은 sparse vector space model을 사용하지만 본 논문에서는 dual-encoder를 통해 적은 양의 데이터로 학습된 dense representation을 사용한 retrieval을 제안한다.
1. Introduction
ODQA는 대량의 문서를 이용해 사실에 입각한 질문에 대한 답을 찾는 Task이다.

ODQA는 아래와 같은 두 단계의 프레임워크로 이루어져있다.

기존 연구에서는 Retrieval 하기 위해서 inverted index를 활용해 키워드를 기반으로 탐색하는 TF-IDF나 BM25같은 고차원의 sparse representing을 사용하였다.
이와 다르게 context의 sementic한 정보를 인코딩하여 dense vector로 표현하는 기법은 sparse representation을 보완하는 역할을 한다.
즉, Sparse Retrieval는 휴리스틱하게 문서를 검색하는 기법이라면 Dense Retrieval는 Retriever를 학습을 통해 최적화를 한다.
Question : "Who is the bad guy in lord of the rings?"
위 질문에 대한 답변은 "Sala Baker is an actor and stuntman from New Zealand. He is best known for portraying the villain Sauron in the Lord of the Rings”라는 context에서 찾을 수 있을 것이다.
Sparse retrieval의 경우는 동의어나 paraphrase한 context에 대해서 유사하다고 판단할 수 없기 때문에 해당 문서를 관련 문서로 판단하지 못한다.
그러나 Dense Retrieval은 "bad guy"와 "villain"이 유사한 의미임을 semantic하게 판단할 수 있기 때문에 해당 문서를 관련 문서로 판단할 수 있다.
기존 Dense Retrieval : ORQA
TF-IDF/BM25의 성능을 넘어선 Dense Retrieval 기법이다.
ORQA는 Retrieval를 Inverse Cloze Task(ICT)로 unsupervised pretraining을 수행한다.
(finetuning 시 빠르게 Wikipedia를 인코딩하고 supurious ambiguity를 피하도록 bias를 부여하기 위한 목적)

각 Passage들이 존재하고 특정 Passage로부터 추출한 임의의 문장을 가지고 각각의 Passage와 유사한 context인지를 학습하여 유사하면 positive한 관계를, 유사하지 않으면 negative한 관계를 갖게 하는 것이 목적이다.

ORQA의 한계점

본 논문에서는 추가적인 pretraining 없이 question과 passage pair만을 가지고 dense embedding model을 만들고자 하였다.
2. Related Work
BM25


동일한 단어가 여러 번 등장했을 때 두 가지 문서가 비슷하다고 표현한다.
전체 문장의 context보다는 이 문장에 어떤 단어가 들어와서 이 단어가 많이 겹쳤을 때 유사하다는 내재적인 가정이 있다.
ORQA 논문이 나오기 전까지는 BM25를 능가하는 Retrieval이 거의 없었다.
3. 제안 방법론
Dense Passage Retriever (DPR)
Reader보다는 Retrieval의 성능을 향상 시키는데 집중하고자 하였고 DPR 방법을 제안하였다.
사전 학습된 BERT로 이루어진 두 개의 Encoder를 사용해 각각 Question과 Passage를 encoding하고, Question과 Passage간의 유사도는 dot product로 계산한다.
Question과 Passage간의 유사도를 측정하는데 있어서 신경망을 사용할 수도 있지만, Passage의 Embedding 계산이 사전에 계산될 수 있도록 유사도 함수는 기능적으로 분해성(decomposable)이 있을 필요가 있다.
왜 Decomposable한 유사도 함수를 사용할까?
- ODQA에서 실시간으로 질문과 가장 유사한 passage를 찾을 때 필요한 전체 연산 시간을 최소화 하기 위해서이다. decomposable하지 않은 cross attention 같은 방법을 사용할 경우 Question sequence의 word와 Passage sequence의 word를 하나하나 고려하면서 유사도 계산을 하기 때문에 시간이 너무 오래 걸린다. 그러나 Dot product를 사용할 경우 Passage에 대한 임베딩 벡터는 사전에 만들어 둘 수 있으므로 더 빠르게 처리할 수 있다.
분해성이 있는 유사도 함수로는 dot product 외에도 L2, Cosine Similarity도 있지만 성능은 비슷했기 때문에 간단한 연산인 dot product를 선택하였다.
M개의 passage가 주어졌을 때 모든 passage에 대한 index를 연속적인 저차원 공간에 매핑하는 것이 목적이다. (본 논문에서는 passage가 wikipedia이기 때문에 M=2.1 million개의 passage이다.) 그렇게 함으로써 question과 연관된 top-k개의 passage를 효과적으로 추출할 수 있다. (k=20~100)

Dual Encoder
DPR은 BERT(base, uncased)를 기반으로 2개의 독립적인 Encoder를 사용한다.

왜 2개의 독립적인 Encoder를 사용할까?
Passage와 Question이 가지는 역할을 생각해보자. Passage는 QA에서 여러 개의 문장들로 구성되는 경우가 대부분이다.(document의 fragment)
Question은 보통 한 문장으로 구성되는 경우가 대부분이다. → 즉, Passage와 Question은 본질적으로 다른 특성을 갖고 있다.
역할(목적)이 다른 text가 있을 때는 독립적인 Encoder를 사용하는 것이 좋다.
Passage나 Question Encoder로부터 나온 representation 벡터는 대체로 CLS 벡터를 가지고와서 사용한다.
이 때 CLS 벡터는 단어 하나하나의 의미가 아니라 sentence/passage를 대표하는 하나의 벡터이다.
Passage와 Question의 길이는 CLS에 영향을 줄 수 밖에 없기 때문에 Encoder를 구분해서 사용하는 것이 가장 간단하고 직관적인 방법이다.
DPR이라는 논문에서는 Passage와 Question의 distribution이 다를 것이라는 내재적인 가정이 있다고 생각하면 된다.
Question과 Passage의 Similarity는 각 인코더의 output vector를 dot product 연산을 통해 계산한다.

Training
연관된 Question-Passage는 가깝게, 그렇지 않은 pair는 멀리 위치하도록 하는 vector space를 구축하는 것을 목표로 학습한다.

Positive and negative passages
Positive passage의 경우 명확하게 선정할 수 있지만 Negative passage는 선정할 수 있는 범위가 광범위하다.
Negative passage를 어떻게 선택하느냐에 따라 encoder의 성능이 달라질 수 있다.

본 논문에서는 Gold passages에 하나의 BM25 negative passage(Hard negative)를 더해주는 것이 최고 성능을 나타내었다.
In-batch negatives

하나의 Question에 대해서 이 Question에 할당된 negative passage 뿐만 아니라 mini-batch 내에 있는 다른 Question에 대한 passage들도 negative로 활용할 수 있다. 이 방법은 학습 샘플 수를 늘려줄 수 있다.
하나의 mini-batch 내에서 positive passage에 대한 similarity와 negative passage에 대한 similarity를 모두 활용할 수 있기 때문에 메모리 효율적이다.
Contribution
두 개의 BERT encoder로 이루어진 dual encoder 구조를 Fint-tuning하는 방식을 통해

4. 실험 및 결과
Dataset
데이터셋이 갖는 특성을 이해하는 것이 중요하다. (아래 결과 부분 참조)

Baseline

결과
Retrieval Accuracy

Single과 Multi의 차이점은 SQuAD 데이터셋의 포함 유무이다.

SQuAD 데이터셋의 경우 annotator가 passage를 보고 Question을 작성하였기 때문에 Passage에 있는 text가 정답으로 똑같이 만들어질 가능성이 높고 적은양의 Wikipedia 문서만 사용했기 때문에 편향성을 갖고 있을 수 있어 휴리스틱 기반의 BM25가 성능이 더 좋게 나타난 것이라고 분석한다.
→ 데이터의 특성에 따라 성능의 경향이 다르다.
또한 SQuAD 데이터셋을 제외하고는 BM25만을 사용했을 때보다 DPR을 사용했을 때 성능이 더 높았다.
BM25 + DPR은 DPR과 BM25의 결과를 Linear combination한 결과이다.
Sample efficiency

1000개의 데이터만 사용하여도 DPR이 BM25를 능가한다. 또한 데이터 개수를 늘려갈 수록 Retrevial accuracy도 증가하였다.
In-batch negative training

최상단의 실험 부분은 negative pair의 개수에 대한 실험이다. k=20이상으로 갈수록 negative passage의 종류는 크게 영향이 없었다.

중단의 실험 부분은 in-batch negative training에 관한 실험이다. In-batch negative 방식이 성능 향상에 영향을 끼쳤음을 알 수 있다. 또한 Batch 크기가 클수록 정확도가 향상되었다.
In-batch negative는 메모리 효율 향상을 위해 사용했는데 성능까지 좋아지는 이유는 무엇일까?
loss에서 학습하는 기법이 유사한 것은 더 유사하게, 유사하지 않은 것은 더 멀리 떨어질 수 있도록 Similarity 기반으로 학습하기 때문에 학습 효율성 뿐만 아니라 representation이 더 좋아지도록 학습하고 있기 때문이다.
In-batch negative에서는 왜 Gold type의 실험만 진행할까?
In-batch negative에서 negative를 구성하는 것이 지금 다루고자 하는 Question이 아닌 다른 Question들의 Gold 값을 사용하기로 정의하였기 때문에 In-Batch Negative 실험에서는 Gold로 밖에 실험을 할 수 밖에 없다.
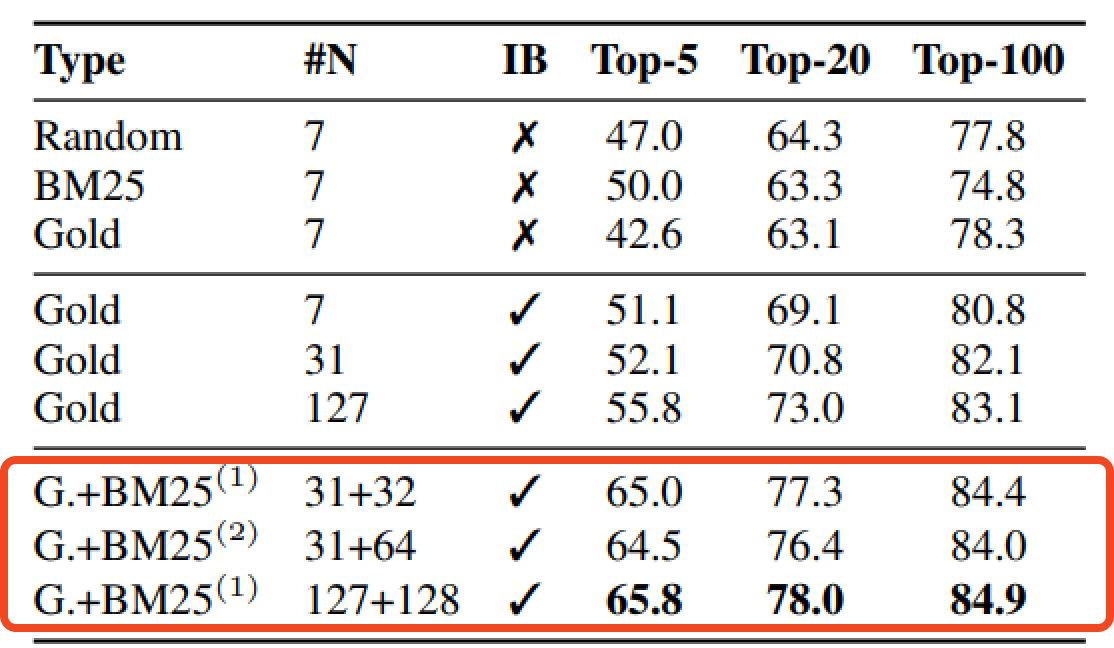
BM25로 만든 하나의 hard negative passage를 Batch 내 모든 질문에 대해 negative passage로 적용하도록 추가했을 때 성능이 향상되었다.
모델 입장에서는 헷갈리는 답을 오답이라고 알려주면 성능이 좋아진다.
모델 입장에서는 Question이랑 Passage를 비교했을 때 겹치는 단어는 많지만 정답이 아닌 문제의 경우는 굉장히 까다로운 문제일 것이다.
그래서 BM25라는 lexical matching에 특화되어 있는 지표로 만든 hard negative sample이 모델이 더 정확하게 학습할 수 있도록 하는 보조장치 역할을 한다.
또한 하나를 추가했을 때가 여러개를 추가했을 때 보다 성능이 더 높았다. 이에 대한 이유는 논문에서 명확하게 제시하고 있지는 않다.
In-batch negative가 메모리 효율성을 목적으로 사용하고 있는데 hard negative를 많이 넣게 되면 오히려 효율성이 낮아질 것이라고 생각된다.
Impact of gold passages

Gold passage의 효과를 알아보기 위해 BM25를 이용해 positive passage를 구성하여 실험한 결과 1점 정도의 차이로 큰 효과를 보이지는 않았다.
Similarity and loss

dot product, L2, Cosine Similarity를 모두 실험해본 결과 dot product와 L2의 성능은 비슷했으며 Cosine Similarity는 두 방법보다 성능이 낮았다.
NLL loss가 아닌 Triplet loss도 사용해보았지만 큰 영향을 끼치지는 못하였다.
Cross-dataset generalization
DPR 모델이 Fine-tuning을 하지 않고도 일반화 성능이 좋은지 확인하기 위해 NQ 데이터셋으로 학습한 뒤 작은 양의 데이터인 WebQuestion과 CuratedTREC 데이터셋에 적용해본 결과와 Fine-tuning을 진행한 결과와 비교했을 때 3-5 점 정도의 차이만을 보임을 확인하였다.
즉, DPR은 일반화 성능이 좋다.
Qualitive Analysis
DPR이 BM25보다 더 높은 점수를 보였지만 Quality 측면에서는 두 방식은 다른 양상을 나타낸다.
BM25는 많이 사용되는 키워드나 구절에 대해 집중한 결과를 보였고 DPR은 문맥적인 부분을 더 집중한 결과를 나타냈다.
Run time Efficiency
Retrieval 단계를 거치는 이유는 질문에 대한 답을 찾기 위해 검색하는 범위를 최대한 줄이기 위해서이다.
Intel Xeon CPU E5-2698 v4 / 2.20GHz / 512 GB memory 환경에서 Inference 속도를 비교하였다.
DPR은 FAISS 라이브러리를 사용해서 초당 995개의 질문 처리 속도를 보였고, 각 질문 당 100개의 passage를 반환하였다. BM25의 경우에는 초당 23.7개의 질문 처리 속도를 보였다.
그러나 Passage들을 dense vector로 매핑하는 과정은 시간이 오래 걸렸다. FAISS 라이브러리를 이용해 2100만개의 문장을 dense embedding하는데 8개의 GPU로 8.8시간이 소요되었다. Inverted Index를 사용하는 방법은 30분밖에 걸리지 않았다.
End-to-End QA System

Retrieval로부터 추출된 top-k passage들에 대해 reader model이 answer를 도출한다.
Reader는 각 passage들에 대해 아래와 같은 score를 계산한다.

가장 높은 passage selection score과 best span score를 가진 span을 정답으로 선택한다.
Passage Selection model
Question과 Passage 사이의 Cross Attention을 이용해 질문과 가장 관련있는 Passage를 도출한다. Cross Attention은 decomposable하여 대규모 말뭉치에서는 활용하기 어렵지만 Retrieval를 통해 Passage의 후보 양을 줄였으므로 활용할 수 있다.
Reader model : how to find span

$ P_{i} $는 i번째 Passage에 대한 BERT representation이다.
(Lxh)를 가지며 L은 maximum length of the passage, h는 hidden dimension을 의미한다.
(Lxh)를 가지며 L은 maximum length of the passage, h는 hidden dimension을 의미한다.
정답 span의 시작과 끝 idx에 대한 토큰의 확률과 해당 passage가 정답에 적합한지를 나타내는 확률은 위 수식처럼 정의한다.
$ P_{selected}(i) $는 모든 passage들의 [CLS] 토큰에 대한 hidden embedding vector와 학습가능한 $ w_{selected}와의 연산을 통해 계산된다.
Passage Selection score는 $ P_{selected}(i) $로 계산하고
Span score는 $ P_{start,i}(s) * P_{end,i}(t) $ 로 계산한다.
본 논문은 Training 과정에서는 Retriever로부터 주어진 100개의 passage들 중 1개의 possitive passage와 m-1개의 negative passage를 sampling한다. (m=24)
Reader model에서는 Positive passage의 모든answer span의 marginal log-likelihood를 최대화하는 방향으로 학습한다. (모든 answer span인 이유는 한 passage의 여러 부분에서 정답이 될 수 있기 때문이다.)

Result

최종 QA 테스크에서의 성능을 평가하는 실험에서도 DPR이 더 좋은 성능을 보임을 확인할 수 있다.
또한 BM25과 DPR로 top-2000개의 passage 후보를 추린 다음 이를
$ BM25(q,p) + \lambda sim(q,p) $ 식을 통해 reranking을 수행한 경우가 가장 성능이 좋았다. (λ = 1.1)
5. 결론 (배운점)

728x90
'딥러닝 > 논문 리뷰(GitBook으로 이전)' 카테고리의 다른 글
Contents