부스트캠프 AI Tech 4기
[ODQA] 3. MRC 데이터 전처리: prepare_train_features
- -
라이브러리 및 데이터 로드
import random
import numpy as np
import torch
from datasets import load_dataset, load_metric
# 데이터셋 로드
datasets = load_dataset("squad_kor_v1") # len(datasets["train"]) == 60407
# 평가지표 로드
metric = load_metric("squad")
▮ PLM 로드
from transformers import AutoConfig, AutoModelForQuestionAnswering, AutoTokenizer
model_name = "bert-base-multilingual-cased"
config = AutoConfig.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name, use_fast=True)
model = AutoModelQuestionAnswering.from_pretrained(model_name, config=config)
# 모델 구조 확인
model(qa_outputs) 부분이 QA 부분이다.
out_features가 2인 이유는 start, end position을 찾기 위함이다.
BertForQuestionAnswering(
(bert): BertModel(
(embeddings): BertEmbeddings(
(word_embeddings): Embedding(119547, 768, padding_idx=0)
(position_embeddings): Embedding(512, 768)
(token_type_embeddings): Embedding(2, 768)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(encoder): BertEncoder(
(layer): ModuleList(
(0): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
(intermediate_act_fn): GELUActivation()
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
...
(11): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
(intermediate_act_fn): GELUActivation()
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
)
)
(qa_outputs): Linear(in_features=768, out_features=2, bias=True)
)
▮ 파라미터 설정
# 데이터 전처리를 위한 파라미터
max_seq_length = 384 # Question과 Context, Special token을 합한 Sequence의 max size
pad_to_max_length = True
doc_stride = 128 # Context가 너무 길어서 나누었을 때 오버랩되는 시퀀스 길이# 학습을 위한 파라미터
max_train_samples = 16
max_val_samples = 16
preprocessing_num_workers = 4
batch_size = 16
num_train_epochs = 30
n_best_size = 20
max_answer_length = 30
▮ 데이터 전처리 : prepare_train_features
def prepare_train_features(examples):
# 주어진 텍스트를 토크나이징함
# 이 때 텍스트의 길이가 max_seq_length를 넘으면 stride만큼 슬라이딩하며 여러 개로 나눔
# 즉, 하나의 example에서 일부분이 겹치는 여러 sequence(feature)가 생길 수 있음
tokenized_examples = tokenizer(
examples["question"],
examples["context"],
truncation="only_second", # max_seq_length까지 truncate함 / pair의 두번째 파트(context)만 잘라냄
max_length=max_seq_length,
stride=doc_stride,
return_overflowing_tokens=True, # 길이를 넘어가는 토큰들을 반환할 것인지
return_offsets_mapping=True, # 각 토큰에 대해 (char_start, char_end) 정보를 반환한 것인지
padding="max_length",
)
# example 하나가 여러 sequence에 대응하는 경우를 위해 매핑이 필요
overflow_to_sample_mapping = tokenized_examples.pop("overflow_to_sample_mapping")
# offset_mappings으로 토큰이 원본 context 내 몇번째 글자부터 몇번째 글자까지 해당하는지 알 수 있음
offset_mapping = tokenized_examples.pop("offset_mapping")
# 정답지를 만들기 위한 리스트
tokenized_examples["start_positions"] = []
tokenized_examples["end_positions"] = []
for i, offsets in enumerate(offset_mapping):
input_ids = tokenized_examples["input_ids"][i]
cls_index = input_ids.index(tokenizer.cls_token_id)
# 해당 example에 해당하는 sequence를 찾음
sequence_ids = tokenized_examples.sequence_ids(i)
# sequence가 속하는 example을 찾는다
example_index = overflow_to_sample_mapping[i]
answers = examples["answers"][example_index]
# 텍스트에서 answer의 시작점, 끝점
answer_start_offset = answers["answer_start"][0]
answer_end_offset = answer_start_offset + len(answers["text"][0])
# 텍스트에서 현재 span의 시작 토큰 인덱스
token_start_index = 0
while sequence_ids[token_start_index] != 1:
token_start_index += 1
# 텍스트에서 현재 span 끝 토큰 인덱스
token_end_index = len(input_ids) - 1
while sequence_ids[token_end_index] != 1:
token_end_index -= 1
# answer가 현재 span을 벗어났는지 체크
if not (
offsets[token_start_index][0] <= answer_start_offset
and offsets[token_end_index][1] >= answer_end_offset
):
tokenized_examples["start_positions"].append(cls_index)
tokenized_examples["end_positions"].append(cls_index)
else:
# token_start_index와 token_end_index를 answer의 시작점과 끝점으로 옮김
while (
token_start_index < len(offsets)
and offsets[token_start_index][0] <= answer_start_offset
):
token_start_index += 1
tokenized_examples["start_positions"].append(token_start_index - 1)
while offsets[token_end_index][1] >= answer_end_offset:
token_end_index -= 1
tokenized_examples["end_positions"].append(token_end_index + 1)
return tokenized_examples
Tokenizer의 Input과 Output
tokenized_examples = tokenizer(
examples["question"],
examples["context"],
truncation="only_second", # max_seq_length까지 truncate함 / pair의 두번째 파트(context)만 잘라냄
max_length=max_seq_length,
stride=doc_stride,
return_overflowing_tokens=True, # 길이를 넘어가는 토큰들을 반환할 것인지
return_offsets_mapping=True, # 각 토큰에 대해 (char_start, char_end) 정보를 반환한 것인지
padding="max_length",
)💬 return_overflowing_tokens
길이를 넘어가는 토큰들을 반환할 것인지
💬 return_offsets_mapping
각 토큰에 대해 (char_start, char_end) 정보를 반환한 것인지
◾ Input

◾ Output
{ 'input_ids' , 'token_type_ids', 'attention_mask', 'offset_mapping', 'overflow_to_sample_mapping' }
Context는 max_seq_length 길이만큼 잘리며, doc_stride만큼 겹치게 된다.
위의 데이터를 tokenizing하면 'Question + Context 앞부분' , 'Question + Context 뒷부분' 형태로 2개가 반환될 것이다.
len(tokenized_examples["input_ids"]) → 2
💡 offset_mapping
원본 Context에서 각 token의 시작점과 끝점을 tuple 형태로 반환해준 정보
offset_mapping = tokenized_examples.pop("offset_mapping")
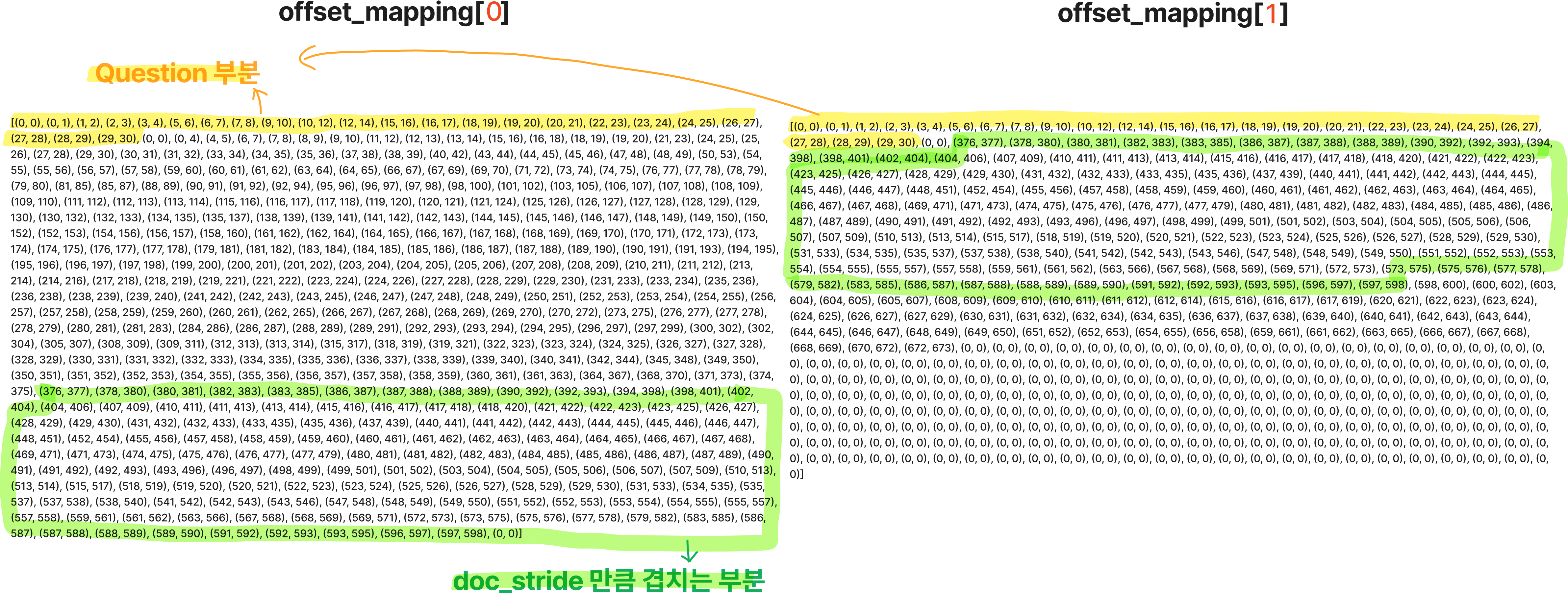
💡 overflow_to_sample_mapping
example(데이터 하나)가 위 그림처럼 max_seq_length를 초과하여 2개로 쪼개질 경우쪼개진 것[0]과 쪼개진 것[1]은 원래 examples[0]번째의 context임을 나타낸다.
overflow_to_sample_mapping = tokenized_examples.pop("overflow_to_sample_mapping")
>>> [0, 0]
⭐ for 문 뜯어보기
# 쪼개진 문장들만큼 돌겠다
for i, offsets in enumerate(offset_mapping):
input_ids = tokenized_examples["input_ids"][i]
cls_index = input_ids.index(tokenizer.cls_token_id)
# 384개의 토큰(max_seq_length)이 question인지 context인지에 대한 정보
sequence_ids = tokenized_examples.sequence_ids(i) # 101:[CLS] 102:[SEP]print(input_ids)
>>> [101, 9318, 78136, 70162, 11018, 8905, 119351, 10459, 9901, 89108, 101825, 9642, 11664, 9294, 119137, 10622, 9511, 11664, 13764, 9965, 11018, 11287, 136, 102, 16221, ... ]
print(cls_index) # [CLS] 토큰의 위치 인덱스
>>> 0
print(sequence_ids) # 0은 Question, 1은 문장, None은 special token
>>> [None, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, None, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, ... ]
print(f"special token ids : {tokenizer.all_special_ids}")
>>> special token ids : [100, 102, 0, 101, 103]
print(f"special tokens : {tokenizer.all_special_tokens}")
>>> special tokens : ['[UNK]', '[SEP]', '[PAD]', '[CLS]', '[MASK]']
- oveflow_to_ample_mapping
# 쪼개진 문장들만큼 돌겠다
for i, offsets in enumerate(offset_mapping):
input_ids = tokenized_examples["input_ids"][i]
cls_index = input_ids.index(tokenizer.cls_token_id)
# 384개의 토큰(max_seq_length)이 question인지 context인지에 대한 정보
sequence_ids = tokenized_examples.sequence_ids(i) # 101:[CLS] 102:[SEP]
# 🐥🐥🐥🐥🐥🐥🐥🐥🐥🐥🐥🐥🐥🐥🐥🐥🐥🐥🐥🐥🐥🐥🐥🐥🐥
# 하나의 Context가 길이가 길어져서 쪼개져도 answer는 같다
# overflow_to_sample_mapping을 이용해 context_1과 context_2가 같은 example이라는 것을 표시해주고
# 쪼개진 context에 맞춰서 정답지를 만들어주기 위해 example_index를 설정
example_index = overflow_to_sample_mapping[i]
answers = examples["answers"][example_index]
# answer의 시작점과 끝점
answer_start_offset = answers["answer_start"][0]
answer_end_offset = answer_start_offset + len(answers["text"][0])
- token_start_index, token_end_index : context의 시작과 끝 부분 index
# 쪼개진 문장들만큼 돌겠다
for i, offsets in enumerate(offset_mapping):
input_ids = tokenized_examples["input_ids"][i]
cls_index = input_ids.index(tokenizer.cls_token_id)
# 384개의 토큰(max_seq_length)이 question인지 context인지에 대한 정보
sequence_ids = tokenized_examples.sequence_ids(i) # 101:[CLS] 102:[SEP]
# 하나의 Context가 길이가 길어져서 쪼개져도 answer는 같다
# overflow_to_sample_mapping을 이용해 context_1과 context_2가 같은 example이라는 것을 표시해주고
# 쪼개진 context에 맞춰서 정답지를 만들어주기 위해 example_index를 설정
example_index = overflow_to_sample_mapping[i]
answers = examples["answers"][example_index]
# answer의 시작점과 끝점
answer_start_offset = answers["answer_start"][0]
answer_end_offset = answer_start_offset + len(answers["text"][0])
# 🐥🐥🐥🐥🐥🐥🐥🐥🐥🐥🐥🐥🐥🐥🐥🐥🐥🐥🐥🐥🐥🐥🐥🐥🐥
# sequence_ids는 0이면 Question, 1이면 Context였으므로 이를 이용해 context의 시작과 끝 부분의 index를 구함
token_start_index = 0
while sequence_ids[token_start_index] != 1:
token_start_index += 1
token_end_index = len(input_ids) - 1
while sequence_ids[token_end_index] != 1:
token_end_index -= 1
- Answer가 Context의 span을 벗어났는지 확인
- Context 내에 answer가 없을 경우 start_position과 end_position을 [CLS]의 index(0)로 설정
# context내에 answer가 없을 경우 정답지에 [CLS]의 index를 설정
if not (
offsets[token_start_index][0] <= answer_start_offset and offsets[token_end_index][1] >= answer_end_offset
):
tokenized_examples["start_positions"].append(cls_index)
tokenized_examples["end_positions"].append(cls_index)
- Answer가 Context 내부에 있다면 token_start_index와 token_end_idx를 answer의 시작과 끝 idx로 설정
else:
while (
token_start_index < len(offsets) and offsets[token_start_index][0] <= answer_start_offset
):
token_start_index += 1
tokenized_examples["start_positions"].append(token_start_index - 1)
while offsets[token_end_index][1] >= answer_end_offset:
token_end_index -= 1
tokenized_examples["end_positions"].append(token_end_index + 1)
▮ 전처리한 새로운 train_dataset 생성

# 학습 시간 때문에 그냥 전체 train dataset을 사용하지 않고 sampling된 데이터만 사용
train_dataset = train_dataset.select(range(max_train_samples))
column_names = datasets["train"].column_names # 새로운 train_dataset을 만들어 줄 것이므로 기존 칼럼은 삭제
train_dataset = train_dataset.map(
prepare_train_features,
batched=True,
num_proc=preprocessing_num_workers,
remove_columns=column_names,
load_from_cache_file=True,
)
▮ eval dataset도 생성
# validation을 위한 데이터 준비
def prepare_validation_features(examples):
tokenized_examples = tokenizer(
examples["question"],
examples["context"],
truncation="only_second",
max_length=max_seq_length,
stride=doc_stride,
return_overflowing_tokens=True,
return_offsets_mapping=True,
padding="max_length",
)
sample_mapping = tokenized_examples.pop("overflow_to_sample_mapping")
tokenized_examples["example_id"] = []
for i in range(len(tokenized_examples["input_ids"])):
sequence_ids = tokenized_examples.sequence_ids(i)
context_index = 1
sample_index = sample_mapping[i]
tokenized_examples["example_id"].append(examples["id"][sample_index])
tokenized_examples["offset_mapping"][i] = [
(o if sequence_ids[k] == context_index else None)
for k, o in enumerate(tokenized_examples["offset_mapping"][i])
]
return tokenized_examples# 전체 데이터로 평가
eval_examples = datasets["validation"]
eval_dataset = eval_examples.map(
prepare_validation_features,
batched=True,
num_proc=preprocessing_num_workers,
remove_columns=column_names,
load_from_cache_file=True,
)
728x90
'부스트캠프 AI Tech 4기' 카테고리의 다른 글
| [ODQA] 5. Passage Retrieval - Dense Embedding (0) | 2022.12.21 |
|---|---|
| [ODQA] 4. Passage Retrieval - Sparse Embedding (1) | 2022.12.21 |
| [ODQA] 2. Extraction-based MRC & Generation-based MRC (0) | 2022.12.21 |
| [ODQA] 1. MRC Intro & Python Basics (0) | 2022.12.19 |
| [WEEK13] Data Annotation for RE Task Wrap-Up Report (0) | 2022.12.19 |
Contents