딥러닝
Autoencoder
- -
AutoEncoder
x를 입력받아서 X̂이라는 출력을 반환하게 되는데 이 x와 X̂의 차이를 최소로 하도록 학습
∴ 입력을 그대로 뱉어내도록 학습

- bottleneck을 통과시키는 과정에서 압축과 해제를 실행
- 인코더는 입력(x)의 정보를 최대한 보존하도록 손실 압축을 수행
(X̂을 복원하는데 있어서 가장 중요한 정보를 뽑아내는 방법을 학습) - 디코더는 중간 결과물(z)의 정보를 입력(x)와 같아지도록 압축 해제(복원)을 수행
⇨ 오토인코더는 복원을 성공적으로 하기 위해 압축과 해제를 반복하며 특징(feature)을 추출하는 방법을 자동으로 학습
Encoder
복원에 필요한 정보를 중심으로 손실 압축을 수행
: 필요 없는 정보는 버리게 된다. (e.g 고양이 얼굴을 학습할 때: 고양이 귀는 2개이다.)
Bottleneck
입력(x)에 비해 작은 차원으로 구성되어 있어 정보의 선택과 압축을 필요로 한다.
차원에 따라 압축의 정도를 결정한다.
∴ z는 입력(x)에 대한 feature vector라고 할 수 있다.
즉, 인코더에 통과시키는 것은 feature vector에 대한 embedding 과정이라고 볼 수 있다.
Decoder
압축된 중간 결과물(z)를 바탕으로 최대한 입력(x)과 비슷하게 복원한다. → X̂
(보통 MSELoss를 통해 최적화 수행)
인코더의 결과물 Z를 plot해보았을 때, 비슷한 샘플들은 비슷한 곳에 위치함을 확인할 수 있다.
이 plot이 뿌려진 공간을 hidden(latent) space라고 한다.
x(input space)의 MNIST 샘플이 latent space에 embedding된 것이라고 볼 수 있다.


Mapping to Hidden(Latent) Space
deep neural network에 sample을 통과시키는 과정은 input space에서 latent space로 mapping(embedding)하는 과정이라고 볼 수 있다. (고차원 공간 → 저차원 공간)
각 Hidden layer의 결과물을 hidden vector라고 부른다. 이들은 샘플의 feature을 담고 있다.
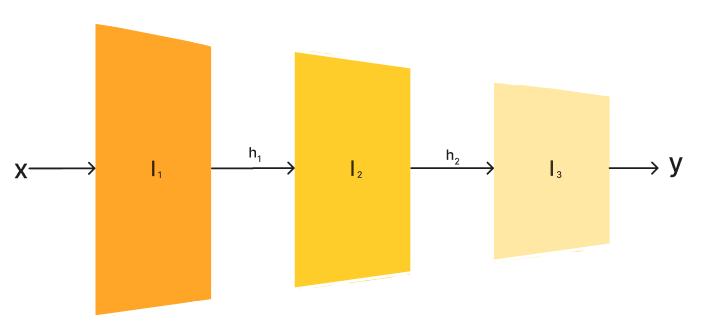
hidden vector는 해석이 어렵다. 그러나 비슷한 특징을 가진 샘플은 비슷한 hidden vector을 가진다.
https://github.com/kimbyeolhee/ML-DL-Algorithms-Study/tree/main/DL/AutoEncoder/autoencoder
728x90
'딥러닝' 카테고리의 다른 글
| KL-Divergence (0) | 2022.06.23 |
|---|---|
| MLE(Maximum Likelihood Estimation) (0) | 2022.06.23 |
| Training / Inference Design & Model Training Procedure (0) | 2022.06.22 |
| 머신러닝 프로젝트 Flow (0) | 2022.05.26 |
| Tensorflow 모델 서비스하기 (0) | 2022.05.19 |
Contents