딥러닝/자연어 처리
RNN & LSTM
- -
Recurrent Neural Network

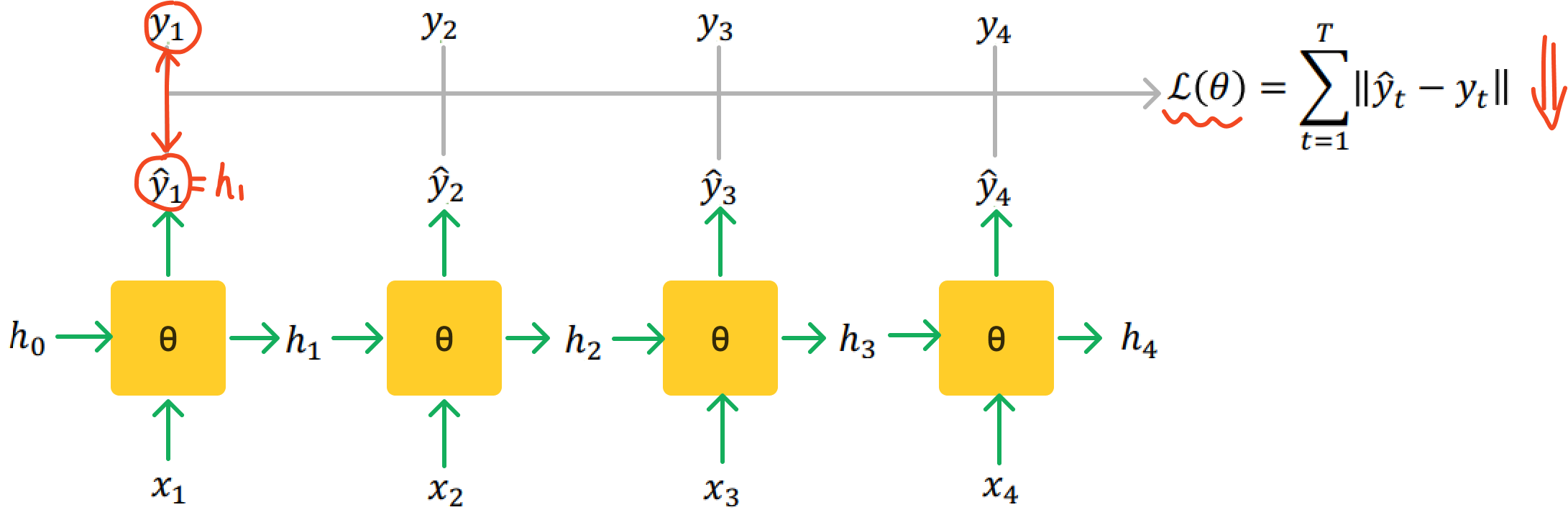
모든 hidden state layer는 같은 θ을 갖고 있다.
θ는 x와 h가 들어오는 것에 대해서 시간과 관계없이 동작을 잘 해야한다고 볼 수 있다.

RNN은 각 time step마다 y와 y hat이 같아지도록 하는 방향으로 학습을 진행한다.
Input Tensor

Hidden Tensor
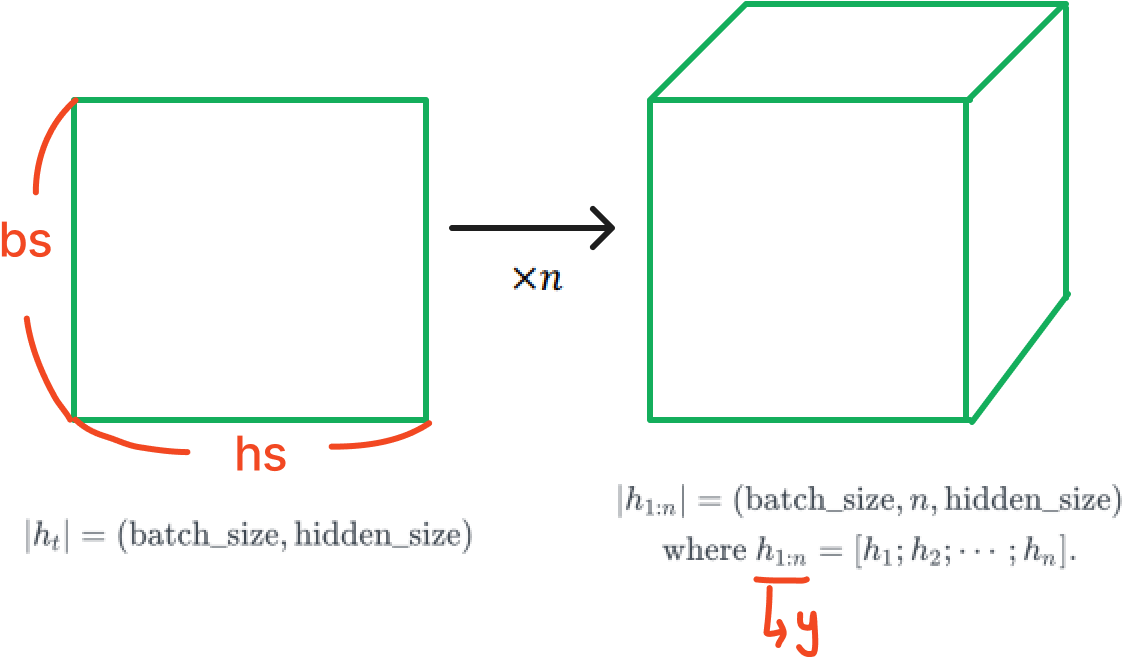
Multi-layered RNN
여러 층으로 layer를 쌓은 형태이다.
각 층 마다 파라미터가 다르다.

output은 마지막 layer의 모든 timestep의 hidden state이다.
Hidden state는 마지막 timestep의 모든 layer의 hidden state이다.
Bidirectional Multi-layered RNN
Hidden state는 layer의 개수가 2배이다.
방향이 양방향이므로 output은 hidden state가 2배가 된다.

RNN Application

1. Non-autoregressive (Non-generative)
문장 전체가 주어지는 경우
Text Classification, POS Tagging
→ Bidirectional RNN 사용 권장
2. Autoregressive (Generative)
이전 time step의 정보를 가지고 현재가 정해지는 경우
One-to-many case 해당
Bidrectional RNN 사용 불가
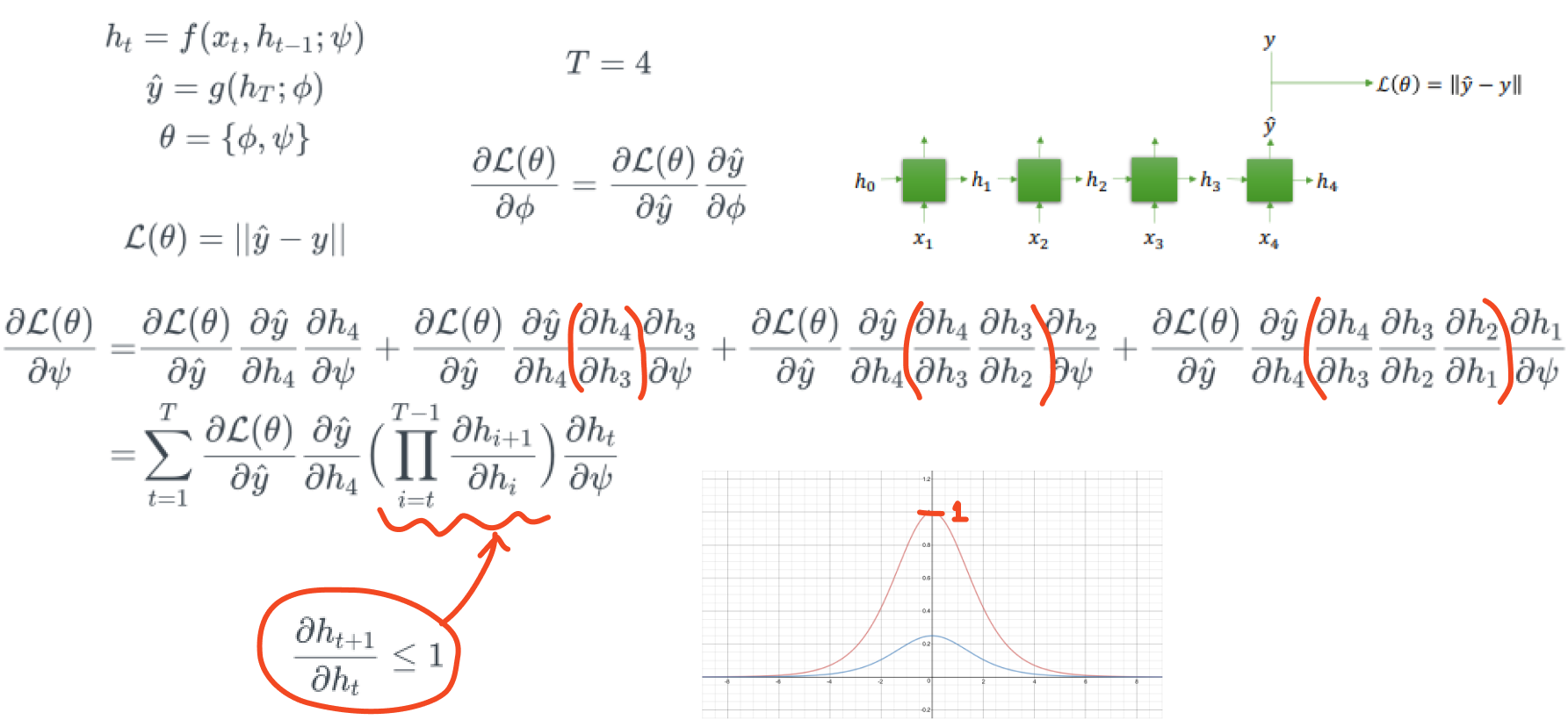
Tanh in Vanilla RNN ⇒ Gradient Vanishing Probelem
Neural Network는 여러 경로로 feed forward될 경우, back propagation을 하는 과정에서 최종 gradient값은 각 경로의 gradient들의 총합이다.

RNN은 time step에 따라 feed forward가 되므로 각 경로로부터 전달되어온 gradient들이 더해지게 된다.
즉, time step의 갯수만큼 레이어가 깊어졌다고 볼 수 있는데, RNN은 tanh를 activation function으로 사용하기 때문에 gradient vanishing problem이 발생한다.

tanh에 들어가는 값이 0일때를 제외하고는 gradient가 모두 1보다 작게 된다.
BPTT in RNN
아래 그림은 Many to One Case의 구조이다.
tanh의 gradient가 반복되어 곱해지는 구조이기 때문에 gradient vanishing problem이 발생한다.
Many to Many는 Many to One case가 여러개 있다고 생각하면 된다.
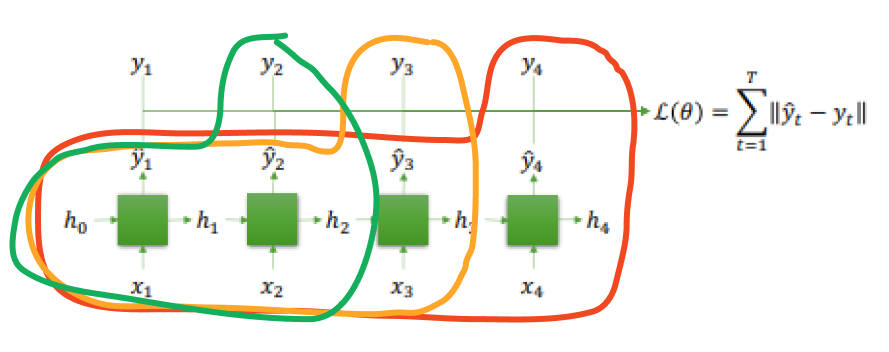
따라서 gradient vanishing problem이 발생한다. → 이전 데이터는 기억을 못하게 된다.
∴ 긴 sequence data를 RNN에서 다루기 힘들다.
LSTM
RNN의 gradient vanishing problem을 해결하고자 하였다.
- hidden state 뿐만 아니라 cell state가 존재한다.
- Gate using Sigmoid
- Sigmoid는 0과 1사이의 값을 반환하므로 sigmoid를 곱하면 마치 문을 열고 닫는 듯한 효과를 내어 정보의 흐름을 컨트롤
하기 위해 사용되었다.

BPTT in LSTM

f는 forget gate로 sigmoid를 사용한다.
forget gate가 열고 닫는 것을 어떻게 학습함에 따라서
gradient를 뒤에 전달할 것인지 말것인지를 정하게 된다.
→ gradient vanishing 문제 해결
아래 그림처럼 Multi-layer로 쌓게 된다면,
LSTM은 시간축에 대해서 backprogation을 할 때 gradient vanishing 문제를 막는다.
그러나 depth에 대한 backpropagation은 gradient vanishing 문제를 해결하지는 못한다.
(4 layer까지는 쌓으나 이 보다 많이 쌓을 경우 residual을 이용하는 것을 추천)

GRU
LSTM은 gate마다 weight 파라미터가 존재하는 복잡한 구조이다.
이런 단점을 보완하고자 한 것이 GRU이다.
그러나 실제로는 LSTM이 좀 더 널리 쓰이는 추세이다.
LSTM은 vanilla RNN에 비해서 훨씬 많은 파라미터를 갖기 때문에 더 많은 학습데이터와 학습 시간이 필요하다.
또한 Gradient Vanishing 문제를 어느정도 해결하였지만 Network capacity의 한계가 존재하기 때문에 긴 sequence 데이터를 모두 기억할 수 있는 것은 아니다.
→ Attention을 통해 이를 해결
https://life-is-also-pizza.tistory.com/28?category=919539
https://life-is-also-pizza.tistory.com/97?category=919539
728x90
'딥러닝 > 자연어 처리' 카테고리의 다른 글
| NLP_Preprocessing : 3)Labeling (0) | 2022.06.26 |
|---|---|
| NLP_Preprocessing : 1)코퍼스 수집 & 2)정제 (0) | 2022.06.26 |
| How to generate text: decoding methods (0) | 2022.06.15 |
| [LM metric] BLEU(Bilingual Evaluation Understudy) (0) | 2022.06.08 |
| [LM metric] Perplexity (0) | 2022.06.07 |
Contents