딥러닝
Ensemble Learning
- -
앙상블 학습은 여러 개의 단일 모델들의 평균치를 내거나 투표를 통한 결과를 도출하는 등 여러 단일 모델을 하나로 엮어 더 좋은 결과를 도출해내는 것이 목적이다.
앙상블 학습에는 여러 종류가 있는데 대표적으로는 Voting, Boosting, Bagging이 있다.
Voting
서로 다른 알고리즘이 도출해 낸 결과물에 대해 투표로 최종 결과를 선택하는 방식이다.
- hard vote: 결과물에 대한 최종값을 투표로 결정
A모델의 분류 예측=1, B모델의 분류 예측=2, C모델의 분류 예측=1인 경우 '1'이 2표이기 때문에 최종 분류로 1을 선택 - soft vote: 각각의 확률의 평균값을 계산한 다음 가장 확률이 높은 값을 선택
A = {1일 확률: 0.7, 2일 확률:0.2, 3일 확률:0.1}
B = {1일 확률: 0.4, 2일 확률:0.3, 3일 확률:0.3}
C = {1일 확률: 0.0, 2일 확률:0.9, 3일 확률:0.1}
→ 1이라 예측한 확률의 값 총합 = 1.1
→ 2이라 예측한 확률의 값 총합 = 1.4 ⇨ 최종 결정→ 3이라 예측한 확률의 값 총합 = 0.5
Bagging (Bootstrap AGGregatING)
데이터 샘플링(Bootstrap)을 통해 모델을 학습시키고 결과를 투표(분류문제)나 평균(회귀)으로 산출해 내는 방식이다.
가장 유명한 알고리즘 중 하나는 랜덤 포레스트이다.
[1,2,3,4,5]라는 훈련 데이터셋이 있을 때 무작위 복원추출을 통하여 크기가 3인 하위 데이터셋을 만든다면 [3, 1, 3] , [1, 3, 4], [2, 3, 5] 등으로 만들 수 있다.
이렇게 각기 다른 샘플링을 통해 학습하기 때문에 각 모델은 상호 독립적이다.
Bagging과 Voting 기법의 가장 큰 차이점은 하나의 단일 알고리즘을 여러개 사용하는지, 아니면 다양한 알고리즘을 동일한 샘플 dataset에 적용하는지가 차이점이다.

model 일반화 오차에 기인하는 요소는 크게 분산(variance), 편향(bias)이 있다.
Bagging 기법은 단일 model을 활용하여 예측했을 때 보다 분산(variance)를 줄이는 효과를 볼 수 있다.왜 분산을 줄이는 효과를 일으키는 것일까?n개의 랜덤변수가 있고 분산이 σ²라고 가정하면, 랜덤변수가 완전히 독립적인 상황에서 n개의 랜덤변수의 분산은 σ²/n이다.모델 자체에 대한 관점으로 본다면 n개의 독립적이고 상호연관되어 있지 않은 모델의 예측 결과의 평균을 취해 분산이 원래 단일 모델의 1/n이 되게 만든다.
Boosting
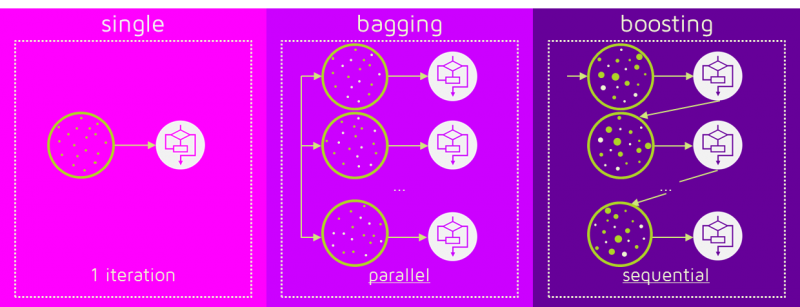
Boosting 알고리즘은 Bagging과 비슷하게 여러 모델(동일 알고리즘)을 학습시키고 각 모델의 출력을 Voting/Averaging한다.
그러나 Bagging과 다른 점은 약한 학습기를 순차적으로 학습하되, 이전 학습에 대하여 잘못 예측된 데이터에 가중치를 부여해 오차를 보완해나가는 방식이다.
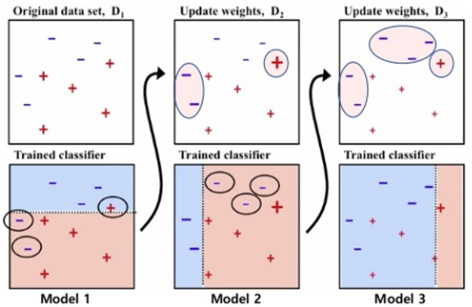
대표적인 Boosting 모델에는 Adaboost, XGBoost, LightGBM 등이 있다.
Boosting은 편향(bias)을 낮춘다.
Boosting은 약한 학습기를 훈련시킨 후, 약한 학습기의 오차를 계산해 다음 학습기에 input으로 넣는다.이 과정 자체가 손실함수를 계속 줄이기 때문에 모델의 편향(bias)를 줄여주게 되는 것이다.그러나 약한 학습기 사이의 강한 상관성을 갖도록 해 독립성이 부족해지기 때문에 Bagging처럼 분산을 줄이지는 못한다.
728x90
'딥러닝' 카테고리의 다른 글
| Batch Normalization (0) | 2022.07.10 |
|---|---|
| Gradient Descent Methods (0) | 2022.07.06 |
| CNN (0) | 2022.06.24 |
| Manifold Hypothesis (0) | 2022.06.23 |
| PCA (0) | 2022.06.23 |
Contents