딥러닝/자연어 처리
[Language Model] n-gram
- -
언어모델(Language Model)은 문장 자체의 출현 확률을 예측하거나, 이전 단어들이 주어졌을 때 다음 단어를 예측하기 위한 모델이다.
많은 문장들을 수집하여, 단어와 단어 사이의 출현 빈도를 통해 확률을 계산한다.
궁극적인 목표는 우리가 일상 생활에서 사용하는 언어의 문장 분포를 정확하게 모델링 하는 것이다.
한국어의 어려움
- 한국어는 단어의 어순이 중요하지 않고, 생략도 가능하기 때문에 단어와 단어 사이의 확률을 계산하는 것이 어렵다.
ex) 나는 버스를 타고 학교에 갑니다.
ex) 버스를 타고 나는 학교에 갑니다.
ex) (나는) 버스를 타고 학교에 갑니다.
언어모델은 주어진 코퍼스 문장들의 likelihood를 최대화하는 파라미터를 찾아내, 주어진 코퍼스를 기반으로 문장들에 대한 확률 분포 함수를 근사한다.(언어의 분포 학습)
문장의 확률은 단어가 주어졌을 때, 다음 단어를 예측하는 확률을 차례대로 곱한 것과 같다.

따라서 언어 모델링(Language Modeling)은 주어진 단어가 있을 때, 다음 단어의 likelihood를 최대화 하는 파라미터를 찾는 과정(다음 단어에 대한 확률 분포 함수를 근사하는 과정)이라고 볼 수 있다.

▮ N-gram
확률값을 근사하는 가장 간단한 방법은 코퍼스에서 빈도를 세는 것이다.
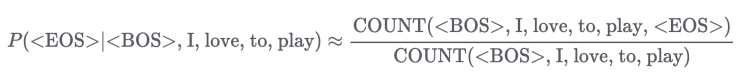

빈도 방식의 문제점은 그런 단어 시퀀스가 학습 코퍼스 내에 없는 경우이다.
그렇게 되면 분자가 0이 되는데 학습 코퍼스 내에만 없을 뿐이지 가능한 문장이기 때문이다.
즉, 복잡한 문장일수록 학습 코퍼스에서 출현 빈도가 낮아, 부정확한 근사가 이루어질 것이다.
→ Markov Assumption
train 코퍼스에 없는 문장에 대해서도 확률값을 구하기 위해
n번째 단어를 알고 싶다면 n-1~1번째 단어까지 다 보지 않고 앞에 k개만 보고 근사하겠다는 아이디어이다.
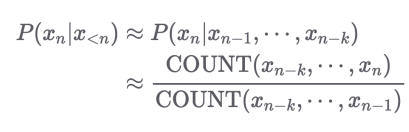
n = k + 1
- k=0 → 1-gram = uni-gram
- k=1 → 2-gram = bi-gram
- k=2 → 3-gram = tri-gram
n이 커질수록 정확한 확률을 산출하는 것이 어렵기 때문에 보통은 3-gram을 가장 많이 사용한다.
→ Smoothing
Markov assumption을 하더라도 여전히 확률 값이 0이 될 수 있는 문제점을 갖고 있다.
이러한 문제점을 완화하기 위해 Smoothing기법이나 Discounting기법을 도입하였다.
Laplace(add-one) smoothing

분자에 + 1 , 분모에 Vocabulary size를 더해주게 되면, 학습 코퍼스에 해당 문장이 없더라도 확률값이 0이 되는 것을 방지할 수 있다.
⇒ 단어를 discrete symbol로 보기 때문에 Exacting Match에 대해서만 count를 하여 확률 값을 근사하는 방식이기 때문에
여전히 unseen word sequence에 대한 문제점은 존재한다.
Smoothing, Interpolation, Back-off 같은 다양한 기법을 통해 문제점을 완화하고자 하지만 근본적인 해결책은 아니다.
728x90
'딥러닝 > 자연어 처리' 카테고리의 다른 글
| LSTM sequence-to-sequence with attention (0) | 2022.07.04 |
|---|---|
| [Language Model] Neural Network Language Model (0) | 2022.07.02 |
| Text Classification using RNN (0) | 2022.06.28 |
| [WordEmbedding] Embedding Layer (0) | 2022.06.28 |
| [WordEmbedding] Word2Vec & Glove & FastText (0) | 2022.06.28 |
Contents