딥러닝/자연어 처리
LSTM sequence-to-sequence with attention
- -

Encoder
source 문장을 압축한 context vecotor를 decoder에 넘겨준다.
Encoder 자체만 놓고 보면 non-auto-regressive task이므로 Bi-directional RNN을 사용 가능하다.
import torch
import torch.nn as nn
from torch.nn.utils.rnn import pack_padded_sequecne as pack
from torch.nn.utils.rnn import pad_packed_sequence as unpack
class Encoder(nn.Module):
"""
:input: Embedding tensor
:return: y, h
"""
def __init__(self, word_vec_size, hidden_size, n_layers=4, dropout_p=.2):
super(Encoder, self).__init__()
self.rnn = nn.LSTM(
word_vec_size,
int(hidden_size / 2), # bidirectional
num_layers=n_layers,
dropout = dropout_p,
bidirectional = True,
batch_first = True,
)
def forward(self, emb):
# |emb| = (batch_size, length, word_vec_size)
if isinstance(emb, tuple):
x, lengths = emb
x = pack(x, lengths.tolist(), batch_first = True)
else:
x = emb
y, h = self.rnn(x)
# |y| = (batch_size, length, hidden_size)
# |h[0]| = (num_layers*2, batch_size, hidden_size/2) #LSTM이므로 (hidden state, cell state) 튜플이 나오기때문
if isinstance(emb, tuple):
y, _ = unpack(y, batch_first=True)
return y, h✅ from torch.nn.utils.rnn import pack_padded_sequence, pad_packed_sequence
더보기
https://pytorch.org/docs/stable/generated/torch.nn.utils.rnn.pad_packed_sequence.html
import torch
import torch.nn as nn
from torch.nn.utils.rnn import pack_padded_sequence, pad_packed_sequence
a = [torch.tensor([1,2,3]), torch.tensor([3,4])]
b = torch.nn.utils.rnn.pad_sequence(a, batch_first=True)
b
>>>
tensor([[1, 2, 3],
[3, 4, 0]])
torch.nn.utils.rnn.pack_padded_sequence(b, batch_first=True, lengths=[3,2])
>>>
PackedSequence(data=tensor([1, 3, 2, 4, 3]), batch_sizes=tensor([2, 2, 1]), sorted_indices=None, unsorted_indices=None)
Decoder
Encoder로부터 문장을 압축한 context vector를 바탕으로 문장을 생성한다.
Auto-regressive task이므로 Bi-directional RNN을 사용할 수 없다.
class Decoder(nn.Module):
def __init__(self, word_vec_size, hidden_size, n_layers=4, dropout_p=.2):
super(Decoder, self).__init__()
self.lstm = nn.LSTM(
word_vec_size + hidden_size,
hidden_size,
num_layers = n_layers,
dropout = dropout_p,
bidirectional = False,
batch_first = True,
)
def forward(self, emb_t, h_t_1_tilde, h_t_1): # h_t_1 => h_(t-1)
# |emb_t| = (bs, 1, word_vec_size)
# |h_t_1_tilde| = (bs, 1, hidden_size)
# |h_t_1[0]| = (n_layers, bs, hidden_size)
batch_size = emb_t.size(0)
hidden_size = h_t_1[0].size(-1)
if h_t_1_tilde is None: # if it is first time step
h_t_1_tilde = emb_t.new(batch_size, 1, hidden_size).zero_()
# input feeding
x = torch.cat([emb_t, h_t_1_tilde], dim=-1)
y, h = self.lstm(x, h_t_1)
return y, h
Generator
Decoder의 hidden state를 받아 현재 time-step의 출력 token에 대한 확률 분포를 반환한다.
단어를 선택하는 문제이므로 cross entropy loss를 통해 최적화한다.
class Generator(nn.Module):
def __init__(self, hidden_size, output_size):
super(Generator, self).__init__()
self.output = nn.Linear(hidden_size, output_size)
self.softmax = nn.LogSoftmax(dim=-1)
def forward(self, x):
# |x| = (bs, len, hidden_size)
y = self.softmax(self.output(x))
# |y| = (bs, len, output_size)
return y # log probability

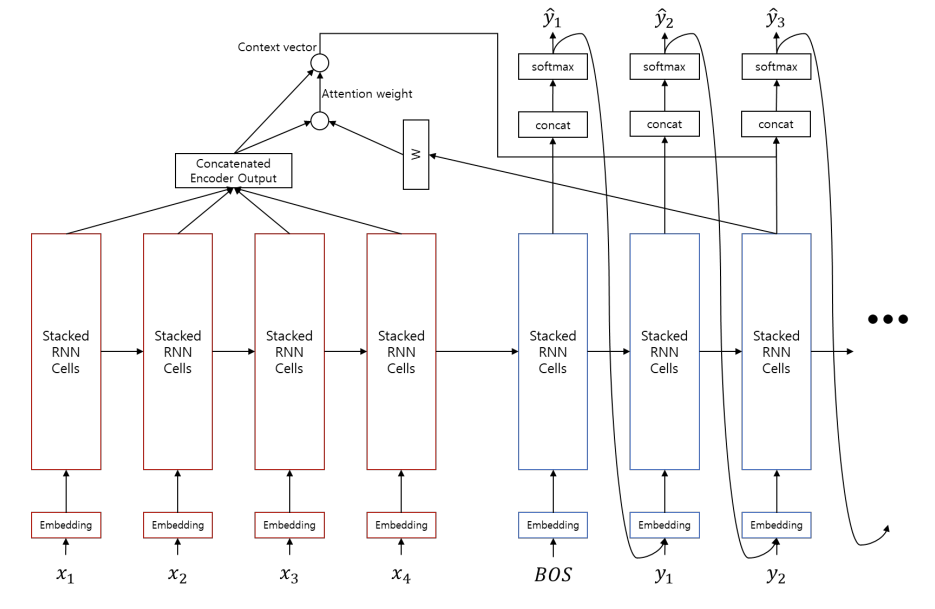
Attention
seq2seq 모델은 하나의 고정된 크기의 벡터(context vector)에 모든 정보를 압축하다보니 정보 손실이 발생한다.
이런 문제를 해결하기 위해 Attention이 등장하였다.
어텐션의 기본 아이디어는 디코더에서 출력 단어를 예측하는 매 시점(time step)마다, 인코더에서의 전체 입력 문장을 다시 한 번 참고한다. 단, 전체 입력 문장을 전부 다 동일한 비율로 참고하는 것이 아니라, 해당 시점에서 예측해야할 단어와 연관이 있는 입력 단어 부분을 좀 더 집중(attention)해서 보게 된다.
미분 가능한 Key-Value function이다.
Query와 Key의 유사도에 따라 Value를 반환한다.
현재 시점 decoder의 output으로 다음 output을 예측할 때 현재 시점 output과 인코더들의 output들간의 유사도를 내적을 통해 구한 뒤 해당 계산값을 반영하여 다음 decoder output의 예측의 성능을 높인다.
즉, Decoder의 hidden state의 한계로 인한 부족한 정보를 직접 encoder에 조회하여 예측에 필요한 정보를 얻어오는 과정이다.
- Query: 현재 time-step의 decoder의 output
- Keys: 모든 time-step 별 encoder output
- Values: 모든 time-step 별 encoder output
⇒ Attention을 통해 RNN의 hidden state의 한계(context vector에 모든 정보를 담기 어려움)를 극복하고 더 긴 길이의 입출력에 대처할 수 있다.

class Attention(nn.Module):
# Query: 현재 time-step의 decoder의 output
# Keys : 모든 time-step별 enocder output
# Values : 모든 time-step 별 encoder output
def __init__(self, hidden_size):
super(Attention, self).__init__()
self.linear = nn.Linear(hidden_size, hidden_size, bias=False)
self.softmax = nn.Softmax(dim = -1)
def forward(self, h_src, h_tgt, mask=None):
# |h_src| = (bs, len, hidden_size)
# |h_tgt| = (bs, 1, hidden_size)
# |mask| = (bs, len)
query = self.linear(h_tgt)
# |query| = (bs, 1, hidden_size)
weight = torch.bmm(query, h_src.transpose(1,2))
# |weight| = (bs, 1, hs) x (bs, hs, len) = (bs, 1, len)
if mask is not None:
weight.masked_fill_(mask.unsqueeze(1), -float('inf'))
weight = self.softmax(weight)
context_vector = torch.bmm(weight, h_src)
# |context_vector| = (bs, 1, len) X (bs, len, hs) = (bs, 1, hs)
return context_vector
Masking
Mini-batch내 문장 구성에 따라 <pad>가 동적으로 생성된다.
이 때, <pad>의 hidden state에는 attention weight가 할당되면 안된다.
따라서 Key와 Query의 dot product 이후에 masking을 통해 <pad> 위치의 값을 -∞로 설정
→ softmax 시 <pad>에는 0으로 할당
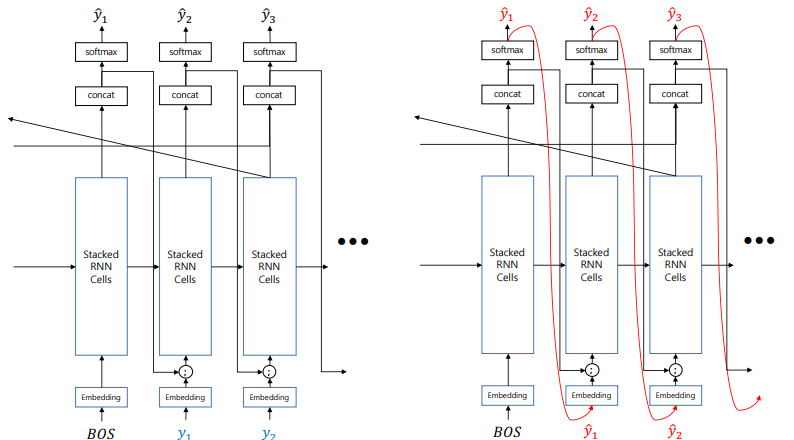
Input Feeding

- Softmax의 결과값은 continuous한 벡터의인데 argmax로 샘플링(원핫벡터)을 취하는 과정에서 정보손실이 발생한다.
→ softmax 이전 값과 word embedding 벡터를 concat해서 정보손실을 최소화 - Teacher Forcing으로 인한 학습/인퍼런스 사이의 괴리를 최소화
: Auto regressive task를 feed forward할 때는 보통 이전 time-step의 output이 현재 time-step의 입력이 되나, train 할 때는 teacher forcing을 통해 원래 정답을 넣어주어 학습하기 때문에 학습과 인퍼런스 사이에 괴리가 생기게 된다.
class Seq2Seq(nn.Module):
def __init__(
self,
input_size,
word_vec_size,
hidden_size,
output_size,
n_layers=4,
dropout_p=0.2,
):
self.input_size = input_size
self.word_vec_size = word_vec_size
self.hidden_size = hidden_size
self.output_size = output_size
self.n_layers = n_layers
self.dropout_p = dropout_p
super(Seq2Seq, self).__init__()
self.emb_src = nn.Embedding(input_size, word_vec_size)
self.emb_dec = nn.Embedding(output_size, word_vec_size)
self.encoder = Encoder(
word_vec_size, hidden_size, n_layers=n_layers, dropout_p=dropout_p
)
self.decoder = Decoder(
word_vec_size, hidden_size, n_layers=n_layers, dropout_p=dropout_p
)
self.attention = Attention(hidden_size)
self.concat = nn.Linear(hidden_size * 2, hidden_size)
self.tanh = nn.Tanh()
self.generator = Generator(hidden_size, output_size)
def generate_mask(self, x, length):
mask = []
max_length = max(length)
for l in length:
if max_length - l > 0:
mask += [
torch.cat(
[x.new_ones(1, l).zero_(), x.new_ones(1, (max_length - l))],
dim=-1,
)
]
else:
mask += [x.new_ones(1, l).zero_()]
mask = torch.cat(mask, dim=0).bool()
return mask
def merge_encoder_hiddens(self, encoder_hiddens):
# Merge bidirectional to uni-directional
# (n_layers * 2, bs, hidden_size /2) => (n_layers, bs, hidden_size)
h_0_tgt, c_0_tgt = encoder_hiddens
batch_size = h_0_tgt.size(1)
h_0_tgt = (
h_0_tgt.transpose(0, 1)
.contiguous()
.view(batch_size, -1, self.hidden_size)
.transpose(0, 1)
.contiguous()
)
c_0_tgt = (
c_0_tgt.transpose(0, 1)
.contiguous()
.view(batch_size, -1, self.hidden_size)
.transpose(0, 1)
.contiguous()
)
return h_0_tgt, c_0_tgt
def forward(self, src, tgt):
# |src| = (bs, n)
# |tgt| = (bs, m)
batch_size = tgt.size(0)
mask = None
x_length = None
if isinstance(src, tuple):
x, x_length = src
mask = self.generate_mask(x, x_length)
# |mask| = (bs, length)
else:
x = src
emb_src = self.emb_src(x)
# |emb_src| = (bs, length, word_vec_size)
h_src, h_0_tgt = self.encoder((emb_src, x_length))
# |h_src| = (bs, length, hidden_size)
# |h_0_tgt| = (n_layers * 2, batch_size, hidden_size/2) # last hidden state of the encoder would be an initial hidden state of decoder
h_0_tgt = self.merge_enocder_hiddens(h_0_tgt)
emb_tgt = self.emb_dec(tgt)
# |emb_tgt| = (bs, length(m), word_vec_size)
h_tilde = []
h_t_tilde = None
decoder_hidden = h_0_tgt
# Run decoder time by time step
for t in range(tgt.size(1)):
# Teacher forcing => take each input from training set, not from the last time step's output
emb_t = emb_tgt[:, t, :].unsqueeze(1)
# |emb_t| = (bs, 1, word_vec_size)
decoder_output, decoder_hidden = self.decoder(
emb_t, h_t_tilde, decoder_hidden
)
# |decoder_output| = (bs, 1, hs)
# |decoder_hidden| = (n_layers, 1, hs)
context_vector = self.attention(h_src, decoder_output, mask)
# |context_vector| = (bs, 1, hs)
h_t_tilde = self.tanh(
self.concat(torch.cat([decoder_output, context_vector], dim=-1))
)
# |h_t_tilde| = (bs, 1, hs)
h_tilde += [h_t_tilde]
h_tilde = torch.cat(h_tilde, dim=1)
# |h_tilde| = (bs, length, hs)
y_hat = self.generator(h_tilde)
# |y_hat| = (bs, length, output_size)
return y_hat
728x90
Contents