딥러닝/자연어 처리
[Contrastive Data and Learning for Natural Language Processing] - 1.1 Contrastive Learning Objectives
- -
- Part 1: Foundations of Contrastive Learning
- Contrastive Learning Objectives
- Contrastive Data Sampling and Augmentation Strategies
- Analysis of Contrastive Learning
1. What is Contrastive Learning
최근의 NLP 모델들은 representation learning 알고리즘에 크게 의존한다.
Contrastive Learning은 유사한 데이터 샘플 쌍은 가깝게 representation되고, 유사하지 않은 데이터 샘플 쌍은 멀리 떨어져 있도록 임베딩 공간을 학습하는 기법이다.
Contrastive Learning을 하기위해서는 두 가지 필수 요소가 필요하다.
1. 어떻게 Contrastive Data를 만들 것인가
2. 어떤 Contrastive Learning Objective Function을 사용할 것인가

앞으로 위 두가지에 대해서 설명할 계획이다.
2. Contrastive Learning Objectives

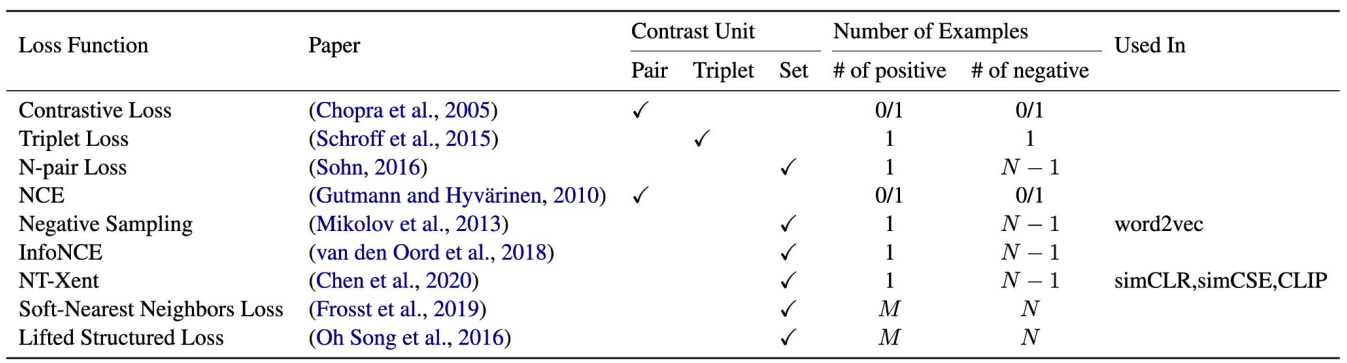
2.1 Contrastive Loss
초창기 Contrastive Learning에 사용된 Object Function으로는 Contrastive Loss가 있다.
아래 그림처럼 유사한 쌍의 example들 ($ y_i = y_j $인 경우 : $x_1과 x_2, x_5와 x_6$)은 L2 Loss를 통해 embedding 거리를 최소화 한다.
유사하지 않은 쌍의 경우($ y_i \neq y_j $인 경우 : $x_3과 x_4$)는 상수 값인 margin 값 $m$ 값을 사용하여 일정 거리를 갖도록 한다. ($m$ : lower bound distance)
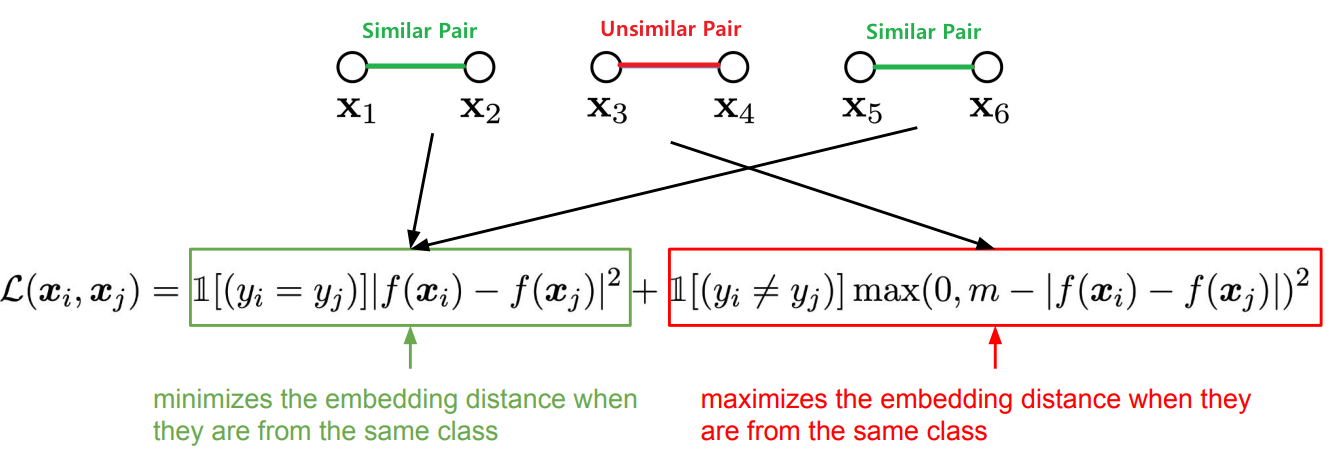
- 장점 1. 비교적 쉽게 학습 데이터셋을 구성해서 학습 가능
- 단점 1. $m$ 값을 설정해야줘야 함
- 단점 2. class 단위(pos, neg)이므로 class는 같지만 representation이 다른 데이터도 동일한 공간에 embedding 됨
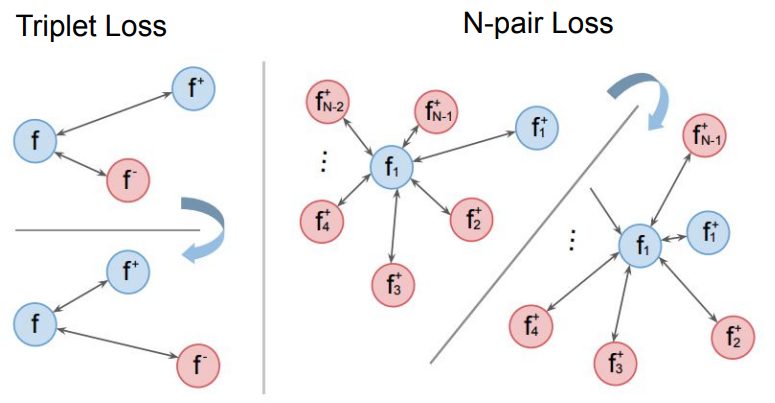
2.2 Triplet Loss
Contrastive Loss는 두 개의 term이 있어서 positive pair인 경우는 첫번째 term으로, negative pair인 경우는 두번째 term에서 계산된다.
그러나 Triplet Loss의 경우는 anchor와 이에 대한 Positive, Negative인 총 3가지 데이터를 가지고 anchor가 negative보다 positive에 더 가깝도록 학습한다.
아래 식을 보면 Triplet Loss의 경우 term이 하나만 존재한다.
만약 anchor와 Negative와의 거리가 더 가깝고, anchor와 Positive와의 거리가 더 멀다면 Loss 값은 0이 되지 않을 것이다.
그렇게 되면 오른쪽 그림처럼 될때까지 학습이 될 것이다.

2.3 N-pair Loss
Triplet Loss는 하나의 Negative sample을 가지고 계산을 했다면,
N-pair Loss는 여러개의 Negative sample들을 가지고 계산한다. (Triplet Loss를 일반화 했다고 볼 수 있음)
Loss function의 식은 multi-class classification 문제에 대한 softmax loss function과 유사하다.
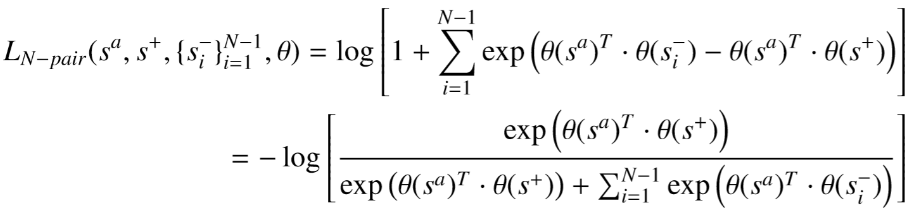
2.4 NCE (Noise Contrastive Estimation)
NCE Loss는 Logistic Regression의 cross entropy라고 볼 수 있다.
Positive sample의 경우 target distribution으로, Negative Sample의 경우 noise distribution으로 보고 계산한다.


2.5 NEG (Negative Sampling)
NEG는 word2vec에서 사용된 NCE의 변형이다.
NCE Loss의 경우 logit 값에 Sigmoid를 씌워주었는데 NEG에서는 logit값이 두 단어의 embedding 값의 내적 값으로 사용된다.
또한 랜덤 단어들을 negative sample들로 사용한다.
따라서 positive pair의 경우는 maximize가 되도록,
k개의 negative sample들의 summation의 경우에는 minmize 되도록 학습이 이루어진다.

2.6 InfoNCE
식을 보면 분자는 하나의 positive pair의 유사도 값이고, 분모는 하나의 positive pair와 N-1개의 negative pair의 유사도 값들의 합이다.
N-pair loss처럼 Loss function의 식이 multi-class classification 문제에 대한 softmax loss function과 유사하다.

InfoNCE Loss는 Representation Learning with Contrastive Predictive coding (van den Oord et al.. 2018) 논문에서 처음 소개되었다.
2.7 NT-Xent (Normalized Temperature-scaled Cross-Entropy)
A Simple Framework for Contrastive Learning of Visual Representations (SimCLR) 논문에서 사용된 Loss로,
InfoNCE와 유사하면서도 차이점이 존재한다.
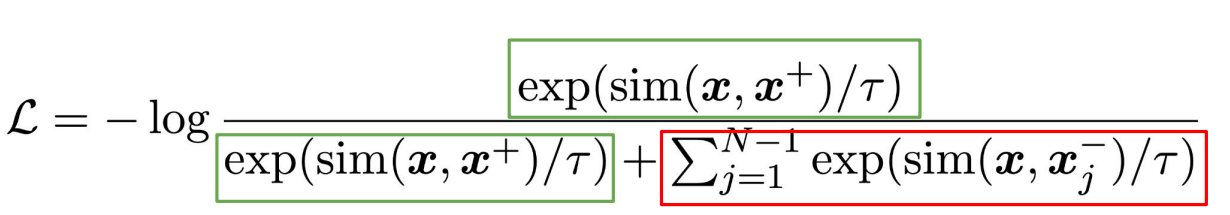
1. Cosine Similarity로 각 pair간의 유사도를 계산
아래 Cosine Similarity를 계산하는 식을 보면 두 벡터의 크기로 나누기 때문에 Embedding을 L2 Normalization을 한다고 볼 수 있다. 논문에서는 실험적으로 해당 방법이 정확도 향상에 기여한다고 한다.

2. $\tau$라는 temperature parameter로 나누어줌
$\tau$는 유사 쌍과 유사하지 않은 쌍의 영향을 제어하는데 사용된다.
$\tau$가 1을 기준으로 작을수록 유사한 쌍에 대한 exp(sim(zᵢ, zⱼ)/τ) 값과 유사하지 않은 쌍에 대한 exp(sim(zᵢ, zⱼ)/τ) 값의 차이가 커지게 된다.
논문에서 저자는 temperature을 적절하게 사용하는 것이 hard negatives로부터 모델을 학습시키는데에 도움을 준다고 설명한다.
2.8 Soft-Nearest Neighbors Loss
NCE Loss의 경우 negative sample들은 많지만 positive sample은 하나밖에 존재하지 않는다.
Soft-Nearest Neighbors Loss는 positive pair의 수를 M으로 확장한다.
(Negative Sample의 수는 N이라고 설정)
distance를 계산하는 방법은 L2 Distance를 사용하며 분자의 경우 M개의 positive example들의 값이다.
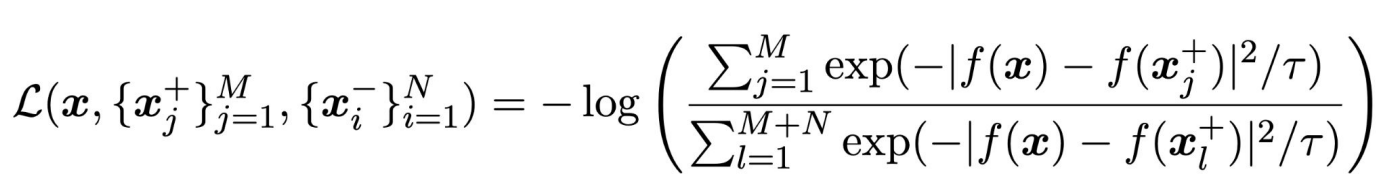
2.9 Lifted Structured Loss
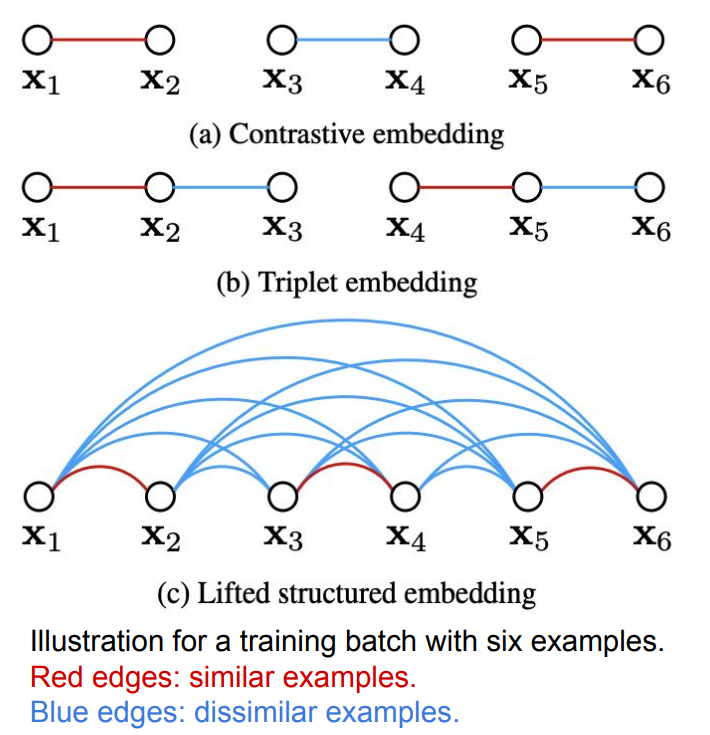
(a) Contrastive Loss의 경우 각각의 pair(pos따로 neg 따로)에 대해 연산을 진행하고
(b) Triplet Loss는 Contrast unit이 anchor-pos-neg 세 가지로 연산을 진행한다.
왼쪽 그림처럼 training batch안에 6개의 데이터 샘플이 있다고 하자. 위 (a)와 (b) 방식의 경우 individual하게 계산할 수 밖에 없지만
(c) Lifted Structured Loss의 경우 batch 내의 모든 쌍들을 고려할 수 있다.
아래 그림처럼 $x_i$가 $x_3$, $x_j$가 $x_4$라고 하자.
첫번째 항인 $d_{i,j} = |f(x_i) - f(x_j)| $ 는 두 데이터 샘플 $x_i$와 $x_j$의 distance를 구하는 함수이다.
두번째 항은 $x_3$와 $x_4$가 다른 sample들과 독립적으로 비교하여 Hardest Negative를 찾는 부분이다.
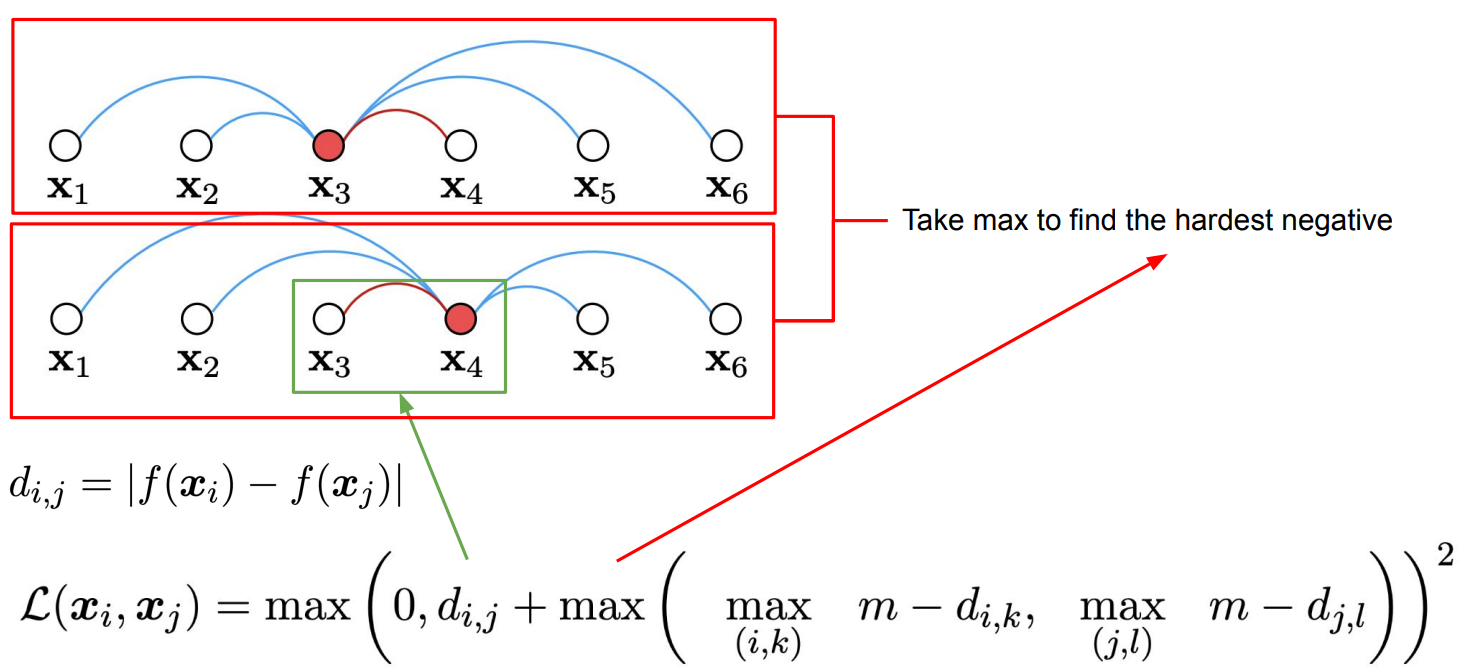
그러나 위와 같은 loss function은 smooth function(미분가능한 함수)가 아니기 때문에 optimize하기가 어렵다.
따라서 max() 함수를 LogSumExp( a smooth approximation to the maximum function )로 대체하여 non-smooth 문제를 해결한다.
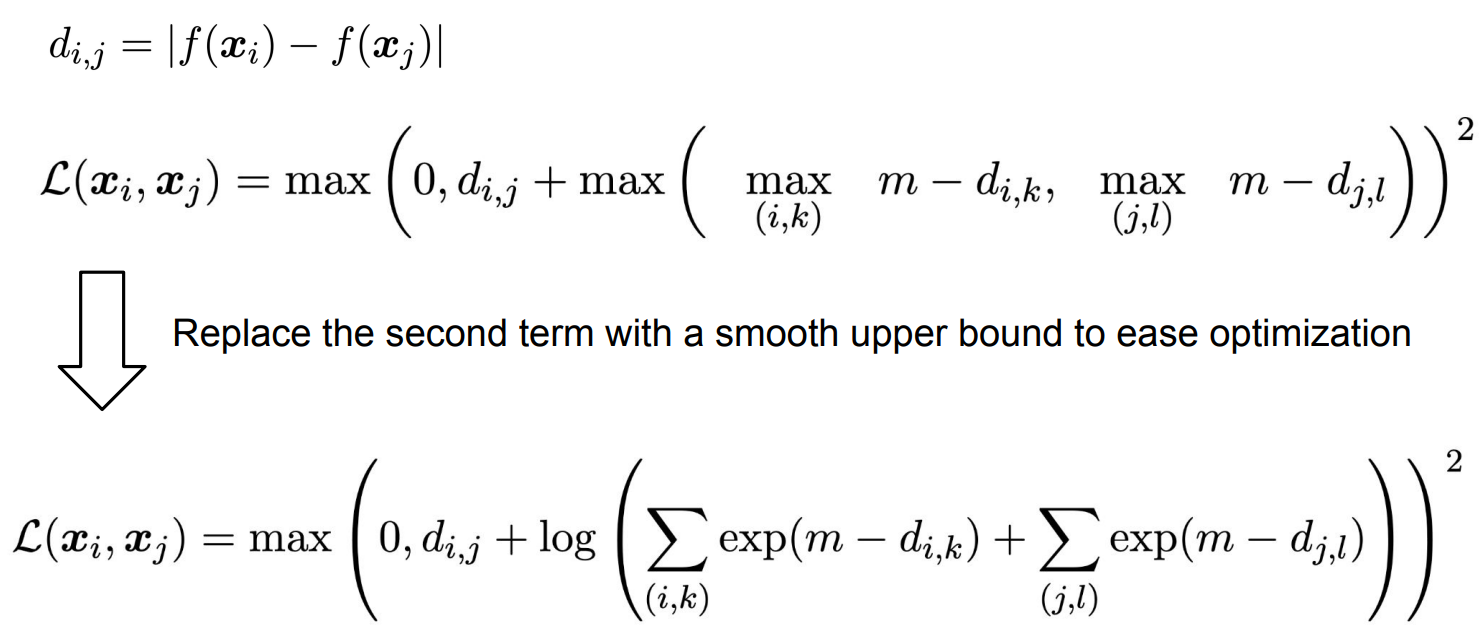
2.10 Summary of Contrastive Learning Objective
Reference
- Contrastive Data and Learning for Natural Language Processing (contrastive-nlp-tutorial.github.io)https://dilithjay.com/blog/nt-xent-loss-explained/
- https://dilithjay.com/blog/nt-xent-loss-explained/
- https://en.wikipedia.org/wiki/LogSumExp
728x90
'딥러닝 > 자연어 처리' 카테고리의 다른 글
Contents