딥러닝/자연어 처리
[Contrastive Data and Learning for Natural Language Processing] - 1.2 Contrastive Data Sampling and Augmentation Strategies
- -
- Part 1: Foundations of Contrastive Learning
- Contrastive Learning Objectives
- Contrastive Data Sampling and Augmentation Strategies
- Analysis of Contrastive Learning

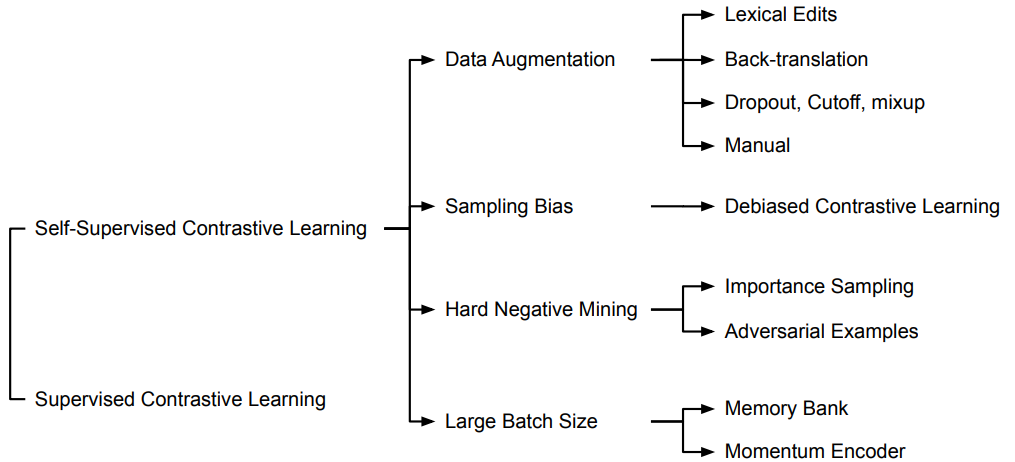
1. Self-Supervised Contrastive Learning
대부분의 Contrastive Learning 프레임워크는 Self-Supervised Learning이다.
보통 Positive Pair의 경우 Data Augmentation을 진행하고
Negative Pair의 경우 랜덤으로 선정한다. (e.g. In-batch Negatives)
이렇게 Self-Supervised Learning을 할 때 가장 큰 이점은 라벨링을 할 필요가 없다는 것이다.
1.1 Self-Supervised Contrastive Learning의 4가지 과제
1. Non-trivial Data Augmentation
특히 텍스트 데이터의 경우 example에 대해 Non-trivial한 변경을 하면서도 의미론적인 의미를 변하게 해서는 안된다.
2. Risk of "Sampling Bias" (i.e., False Negative)
Negative Pair를 랜덤 샘플링을 통해 구성하면 False Negative 문제가 발생할 수 있다. 이를 Sampling Bias 라고도 한다.
즉, 풀어서 설명하면 우리는 랜덤 샘플링해서 얻은 Negative Pair를 Negative라고 간주하지만 사실은 anchor와 Similar할 가능성이 있기 때문에 False Negative 문제가 발생할 수 있다.
3. Hard Negative Mining
Hard Negative는 anchor와 Negative이면서도 embedding이 가까운 Negative 샘플을 의미한다. 이런 샘플들의 경우 학습할 때 난이도가 어렵기 때문에 Hard Negative라고 한다.
이런 Hard Negative 데이터가 Contrastive Learning에서 중요하기 때문에 이 Hard Negative를 어떻게 설정하느냐 또한 Contrastive Learning의 과제이다.
4. Large Batch Size
In-batch negative를 사용하면 Large batch size를 통해 더 많은 negative sample들을 모델에게 제공해 의미있는 학습을 제공할 수 있다.
2. Data Augmentation for Text
1. Text Space 상에서의 augmentation 방법
1.1 Lexical Editing (토큰 레벨)
EDA: Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks 논문에서 제시된 방법으로 토큰을 변경해주는 방법이다.
- SR (Synonm Replacement): 동의어로 대체
- RI (Random Insertion): 랜덤 삽입
- RS (Random Swap): 랜덤 위치 교환
- RD (Random Deletion): 랜덤 삭제
1.2 Word Replacement with c-BERT (Conditional BERT)
Lexical Editing은 간단하지만 랜덤하기 때문에 문맥을 고려하지는 못한다.
따라서 Conditional BERT Contextual Augmentation(Wu et al.. 2018) 논문에서는 문맥을 고려한 augmentation 방법을 제안한다.
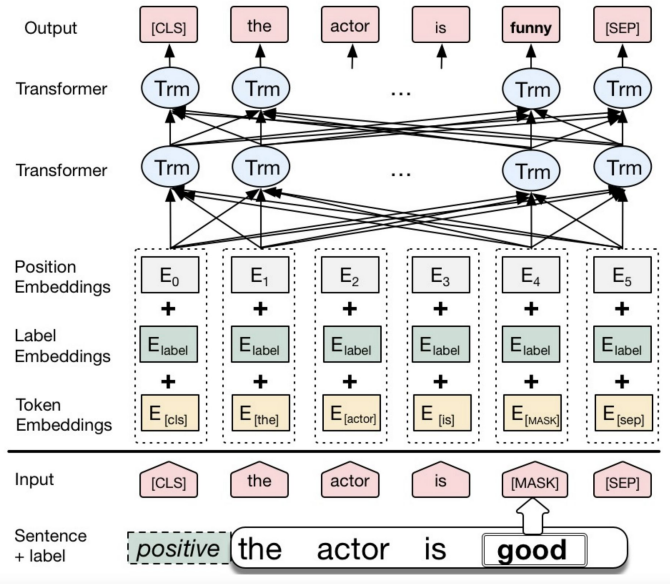
아래 그림을 보면 제일 앞에 positive라는 label 토큰을 넣어주고 good 이라는 단어를 [MASK] 토큰으로 치환해서 입력한다.
모델의 구조는 BERT와 같지만 각 토큰마다 segmentation embedding 대신 Label Embedding 값을 계산하여 더해준다.
최종적인 output으로는 [MASK] 토큰 자리에 들어갈 단어를 예측함으로써 문맥을 고려하면서 augmentation을 할 수 있다고 논문에서 제안하는 방법이다.
1.3 Back-Translation (문장 레벨)
아래 그림처럼 영어로 된 문장 x가 있다고 가정하면 영어→독일어로 번역한 문장 y를 다시 독일어→영어로 번역한 문장 x′를 만드는 과정을 통해 문장을 paraphrasing하는 방법이다.
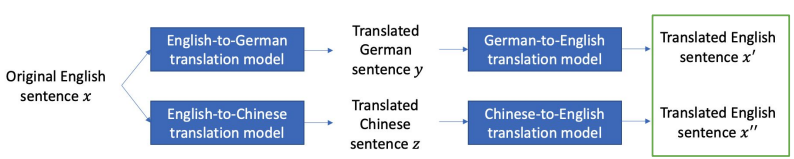
- Positive: 동일한 문장을 번역해서 사용
- Negative: 다른 문장을 번역해서 사용
2. Embedding Space 상에서의 augmentation 방법
2.1 Dropout
SimCSE: Simple Contrastive Learning of Sentence Embeddings. (Gao et al., 2021) 논문에서 Contrastive learning을 수행할 때 Positive Pair를 구성한 방법으로 Unsupervised, Supervised setting을 모두 제안한다.
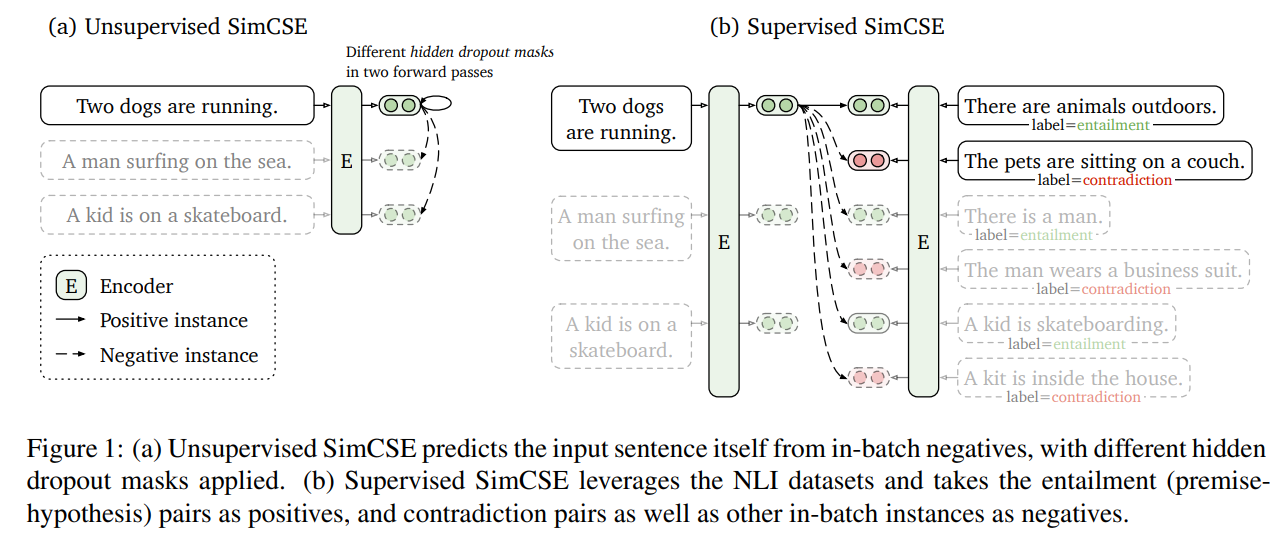
Unsupervised SimCSE의 경우, 동일한 문장을 Positive pair로 활용한다.
위 그림을 보면 encoder가 존재할 때, 하나의 문장을 encoder에 2번 반복해서 넣어줌으로써 output으로 hidden representation을 얻게 된다.
동일한 문장을 넣었지만 해당 output은 완전히 동일하지 않은데, 그 이유는 Encoder의 dropout 값을 다르게 설정해주기 때문에 minimal augmentation을 적용했다고 볼 수 있다.
Negative Pair의 경우는 다른 방식들처럼 in-batch negatives 방식을 활용한다.
Supervised SimCSE의 경우, 서로 다른 문장을 Positive Pair로 활용한다.
서로 다른 문장이라는 것을 정의하기 위해 NLI(Natural Language Inference) 데이터를 활용해 "entailment" label을 positive pair로 구성한다.
"contradiction" label은 Hard negative pair로 사용한다.
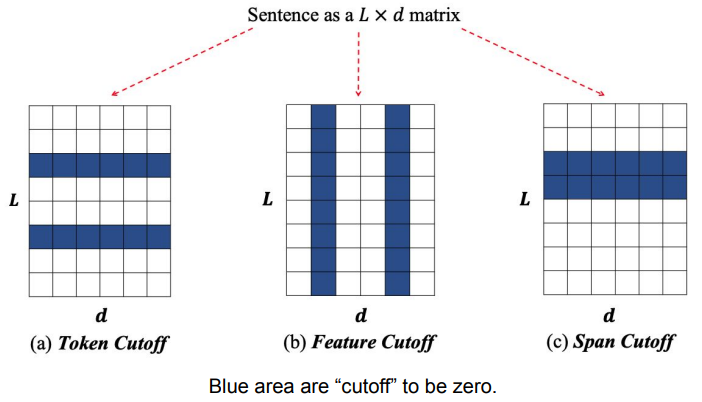
2.2 Cutoff
Cutoff는 A Simple but Tough-to-Beat Data Augmentation Approach for Natural Language Understanding and Generation. (Shen et al., 2020) 논문에서 제안된 방법으로,
아래 그림처럼 입력 문장 중 일부를 제거(zero)하여 fine-tuning 과정에서 입력 문장을 제한하는 Data Augmentation 방법이다.
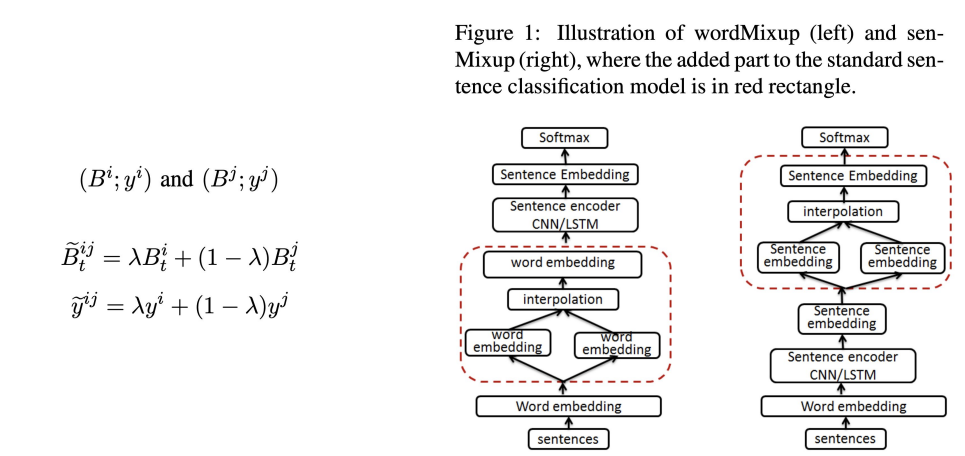
2.3 Mixup
Mixup은 mixup: Beyond Empirical Risk Minimization. (Zhang et al., 2017) 논문에서 제안된 방법으로,
두 샘플 데이터에 대해서 Linear interpolation(선형 보간:알려진 지점의 값 사이(중간)에 위치한 값을 알려진 값으로부터 추정하는 것)하여 새로운 샘플을 만드는 방법이다.
3. NL-Augmenter: Manual Data Augmentation
- augmentation 도구
- 117가지 방법의 Data Augmentation이 존재
- GitHub - GEM-benchmark/NL-Augmenter: NL-Augmenter 🦎 → 🐍 A Collaborative Repository of Natural Language Transformations
3. Sampling Bias
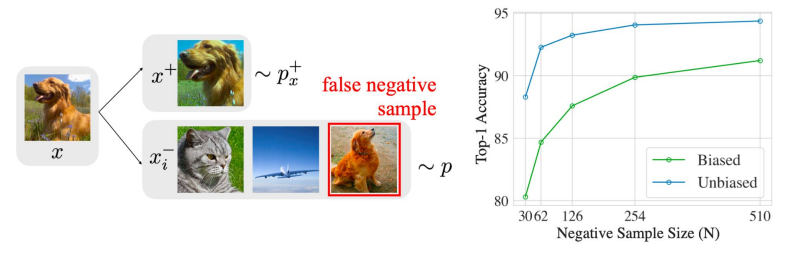
Self-Supervised이기 때문에 label이 존재하지 않는다. 그렇기 때문에 anchor 데이터인 x에 대해서 augmentation을 해서 positive pair인 x+를 구성하고, 랜덤 샘플을 negative sample을 사용하게 된다.
그런데 랜덤으로 샘플링하기 때문에 사실 positive pair로 설정되어야 할 데이터가 negative로 들어가는 문제가 발생할 수 있다.
이런 문제를 Sampling Bias라고 한다. (혹은 False Negative)
3.1 Debiased Contrastive Learning
Debiased Contrastive Learning (Chuang et al., 2020)논문에서 제시된 방법으로,
Positive와 Negative example의 사전확률을 가정하고, negative example에 대한 분포를 근사화하여 loss에 대한 bias를 줄이는 방법이다.
아래 식을 보면 우리의 sample 분포를 p라고 한다면 이 p는 positive의 사전확률 τ+와 positive 분포의 곱과 negative의 사전확률 τ−와 negative 분포의 곱의 합일 것이다.
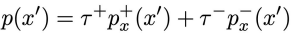
그리고 우리는 sample을 알기 때문에 p(x′)를 알 수 있고, 이 sample에 대한 positive sample을 직접 만들기 때문에 p+x(x′)값도 알 수 있다. 그러나 우리는 p−x(x′) 값은 모른다.
그러므로 만약 N개의 sample들이 존재하고 그 중 M개가 positive sample이라면 우리는 위 식을 아래 식처럼 p−에 대해 정리할 수 있다.
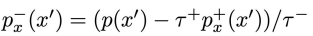
그렇게 구한 p−를 Contrastive Objective function에 대체시킨다.
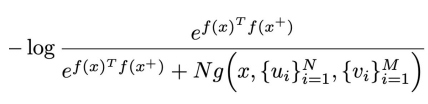
4. Hard Negative Mining
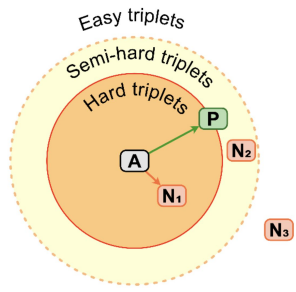
- A : Anchor
- P : Positive
- N1 : Hard Negative
- N2 : Semi-Hard Negative
- N3 : Easy Negative
Contrastive Learning with Hard Negative Samples (Robinson et al., 2021) 논문에서 제시하는 Hard negative mining by Importance Sampling 방법으로는,
만약 negative sample이 anchor와 가깝다면, 그 샘플이 샘플링 될 확률을 높여준다.
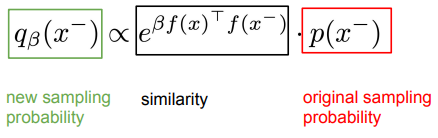
Adversarial Self-Supervised Contrastive Learning (Kim et al., 2020) 논문에서는
Hard negative 뿐만 아니라 Hard Positive example을 사용해 학습을 하는 것이 모델의 robustness를 높일 수 있다고 한다.
5. Large Batch Size
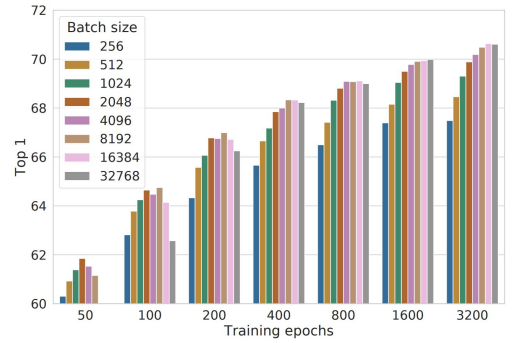
SimCLR 논문에서는 “We train with larger batch size (up to 32K) and longer (up to 3200 epochs).”라고 최대 32000까지 키워서 훈련해보았다고 한다. 또한 위 그래프를 보면 batch size가 클 수록 좋은 성능을 나타내고 있음을 알 수 있다.
CLIP 논문에서는 “We use a very large minibatch size of 32,768.”라고 32,768 크기의 미니배치를 사용했다고 한다.
그러나 이렇게 큰 Batch Size를 사용하려면 메모리 연산량이 많이 필요할 것이다.
이런 문제를 해결하기 위해 2가지 방법을 소개한다.
1. Memory Bank to Reduce Computation
representation을 사전에 미리 계산하고 저장해놓은 다음 batch 내에서 계산하는 것이 아니라 가져와서 사용하는 방법
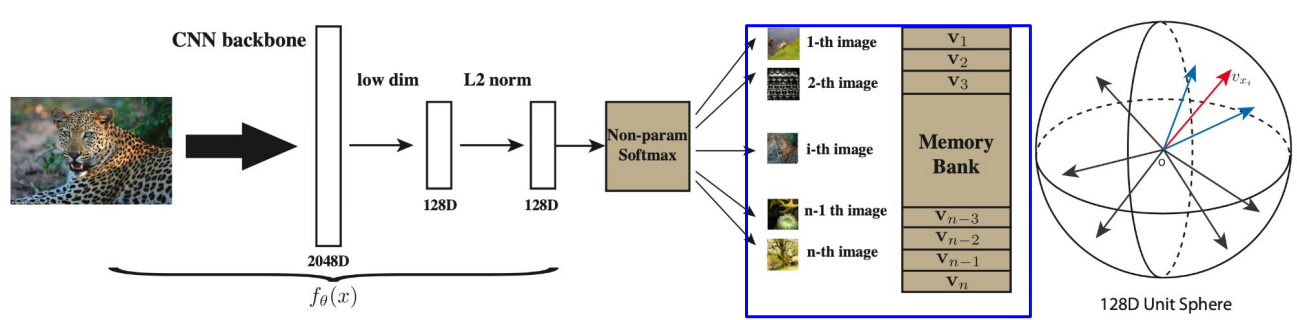
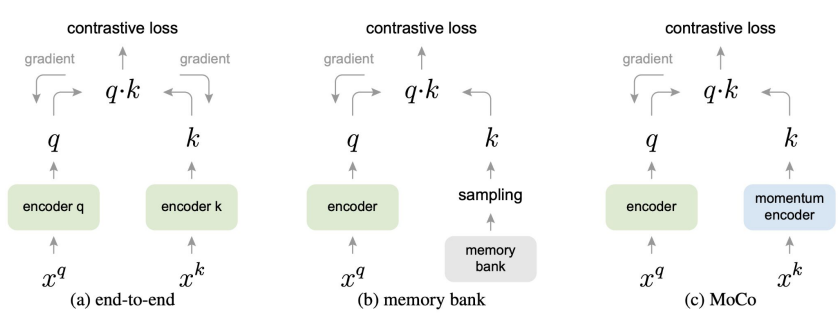
2. Momentum Contrast (MoCo) to Scale the Number of Negative Examples
(a) 기존의 Contrastive learning 방식은 query를 위한 encoder와 key를 위한 encoder 각각에 대해 backpropagation을 하는 구조이다. Contrastive loss를 최대한 활용하려면 많은 수의 negative sample가 필요한데 negative sample의 개수는 mini-batch size에 제한된다는 문제가 존재한다.
(b) memoty bank 방식은 많은 양의 negative sample을 활용할 수 있지만 encoder가 update 됨에 따라 encoded된 negetive sample은 갱신이 되지 않는다.
(c) MoCo의 경우 모멘텀을 사용하여 key encoder를 천천히 업데이트 하면서 dictionary의 일관성을 유지한다.
( 참고로 MoCo에서는 Contrastive loss를 사전을 찾아보는(dictionary loo-up) 것으로 비유하는데 여러 mini-batch들이 합쳐서 만들어진 거대한 dictionary 안에서 query와 같은 쌍인 positive key를 가장 유사도가 높게하는(사전에서 찾아내는) 것을 목적으로 하기 때문이다. )
이 때 여러 개의 mini-batch를 누적해서 dictionary를 만드는데 이 mini-batch를 무한정 쌓아두진 않고 queue 형태로 queue가 꽉 찼다는 가정 하에 가장 들어온지 오래된 mini-batch를 dequeue하고 새로운 mini-batch를 enqueue하는 방식으로 진행한다.
따라서 크고 지속적인 dictionary로 인해 안정적인 학습이 가능하다고 볼 수 있다.
6. From Self-Supervised to Supervised Contrastive Learning
6.1 Supervised Contrastive Learning
대부분의 Contrastive learning 프레임워크는 Self-Supervised이다.
그러나 Supervised 형태로 Contrastive learning도 가능하다.
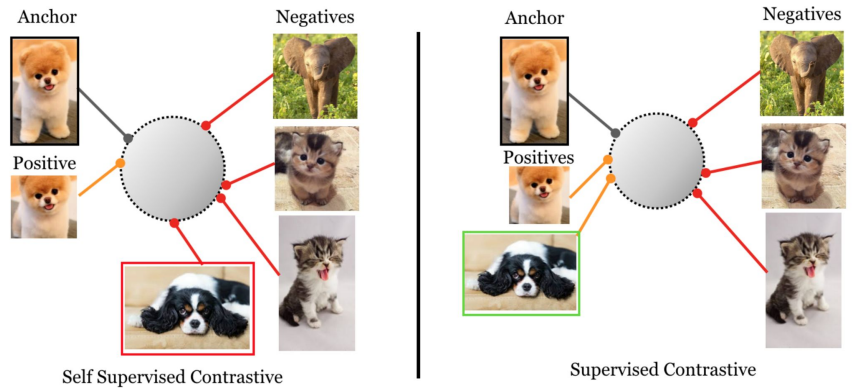
Supervised Contrastive Learning의 경우 Positive Pair는 같은 Class의 데이터로, Negative Pair는 다른 Class의 데이터를 사용한다.
장점으로는 "False Negative" 문제가 발생할 위험이 없으며 큰 Batch Size가 필요없다.
단점으로는 데이터가 라벨링되어있어야 한다.
예시로는 Sentence-BERT, SimCSE, DPR, CLIP이 있다.
6.2 SimCSE (Supervised Vision)
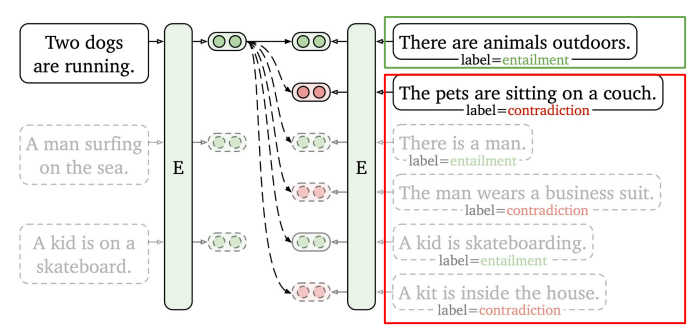
위에서도 설명했듯이 Supervised SimCSE의 경우, 서로 다른 문장을Positive Pair로 활용한다.
서로 다른 문장이라는 것을 정의하기 위해 NLI(Natural Language Inference) 데이터를 활용해 "entailment" label을 positive pair로 구성한다.
"contradiction" label은 Hard negative pair로 사용한다.
6.3 CLIP
기존의 이미지 사전 학습에서는 영상 분류 문제인 ImageNet 데이터셋을 주로 사용하였다. 이러한 영상 분류 문제에는 두 가지 한계점이 있다.
첫번째 한계점은 물체에 대한 labeling이 필요하다는 것이다. 비교적 간단한 label이기는 하지만 이미지 수가 백만, 천만개가 넘는 대용량 데이터셋을 구축할 경우 물체의 분류를 정의하고 labeling 하는 것은 시간과 노력이 필요한 일이다.
두 번째 한계점은 label이 지니는 정보의 양이 너무 적다는 것이다. 이미지에 포함된 다양한 정보들 중 물체의 ‘종류’라는 단일 정보만을 표현하기 때문에 이미지가 가진 다양한 특징을 활용하는데에는 한계가 있다.
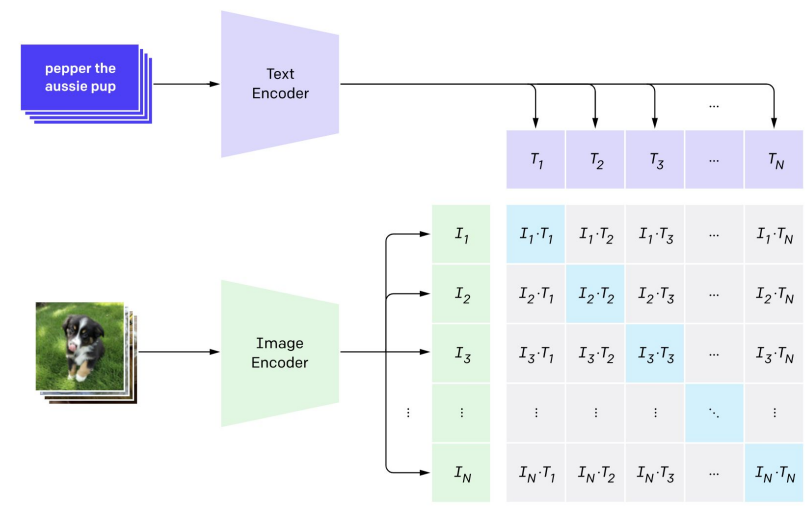
따라서 (이미지-분류 라벨) 대신 (이미지-텍스트) 데이터 셋을 구축하고 정해진 class label이 없기 때문에 분류 문제로 학습할 수는 없기 때문에 주어진 N개의 이미지들과 N개의 텍스트들 사이의 올바른 연결 관계를 찾는 문제로 네트워크를 학습한다.
즉, N개의 쌍을 아래 그림처럼 비교하면 N개의 positive pair과 N2−N개의 negative pair를 얻을 수 있다.
그러고서는 Positive pair의 유사도는 최대로, Negative Pair의 유사도는 최소화하도록 CE loss를 사용해 학습한다.
7. Summary of Contrastive Data Strategies
Reference
728x90
Contents