딥러닝/이미지 처리
Prototypcial Networks for Few-shot Learning
- -
Few-shot Learning
Few-shot Learning은 매우 적은 양의 dataset으로 이루어진 support set을 기반으로 query를 분류 및 예측하는 것이다.

Few-shot Learning은 n-way k-shot learning이라고도 부른다. (n은 Support set의 class의 개수, k는 support set의 각 class 당 갖고 있는 데이터 개수)
Support set은 Query를 분류할 때 사용되는 데이터셋으로, 모델이 test 시에 사용되는 데이터셋이다.
위 그림은 3-way-2-shots classification task이다.
"3-way"는 3 classes를 의미하고 "2-shots"는 2 example per class를 의미한다.
대부분의 few-shot classification 방법은 metric-based이다.
- CNN을 사용해 support와 query 이미지를 feature space에 투영한다.
- query 이미지를 support 이미지와 비교하여 분류한다. 만약 feature space에서 한 이미지가 다른 개들에 비해 퍼그에 더 가깝다면 퍼그라고 분류한다.
few-shot classifcation을 하기 위해서는 좋은 feature space를 찾아야 한다.
CNN은 이미지를 입력으로 받아 주어진 feature space에 representation(embedding)을 출력한다.
여기서 문제는 CNN이 학습되지 않은 이미지라더라도 같은 라벨이라면 가까운 곳에 representation이 되어야 한다는 점이다.
Few-shot Image Classification algorithms은 아래처럼 여러가지가 있는데 그 중에 Prototypical Network에 대해 정리하였다.
- Model-Agnostic Meta-Learning
- Prototypical Networks
- Matching Networks
- Relation Network
Few-shot classification
- training set에서는 본 적 없는 새로운 class에 대해서도 새로운 class들의 few-shot example만을 가지고 잘 일반화된 classification가 되도록 한다.
Prototypical Network에서 Prototypical은 무엇을 의미하는가?
- 논문에서 저자가 제안하는 방법은 각 클래스 별로 prototype을 가지고 distance를 계산하는 방법이기 때문
Introduction
이전까지의 few-shot learning 연구는 overfitting의 문제점이 존재한다.
- matching networks
- meta-LSTM
본 논문이 제안하는 방법인 prototypical networks는 모든 class 별로, 각각을 대표하는 single prototype representation이 있다는 아이디어로부터 시작된 방법이다.

- neural network를 사용하여 input을 embedding space에 non-linear mapping
- class 별 prototype을 embedding space에 있는 support set의 평균으로 설정
- 임베딩된 query와 가까운 class prototype으로 classification
Prototypical Networks
Notation
- label : $N$
- Support Set : $S = \{(x_1,y_1), ..., (x_N,y_N)\}$
- class k의 라벨링 된 example : $S_k$
Model
각 클래스의 prototype인 $c_k$는 임베딩된 support point들의 mean 벡터이다.
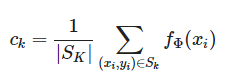
* $c_k$는 $M$ dimension의 representation이다. $c_k \in \mathbb{R}^M$
* embedding function $f_{\phi}:\mathbb{R}^D \rightarrow \mathbb{R}^M$
distiance funcion $d$로 query point x에 대한 class distribution에 기반한 softmax를 계산한다.

* $d$ : distance function
Loss function으로는 negative log-probability를 minimizing한다.


Omniglot Dataset을 가지고 few-shot Classification
import torch
from torch import nn, optim
from torch.utils.data import DataLoader
from torchvision import transforms
from torchvision.datasets import Omniglot
from torchvision.models import resnet18
from tqdm import tqdm
from easyfsl.samplers import TaskSampler
from easyfsl.utils import plot_images, sliding_average
Load Dataset
image_size = 28
train_set = Omniglot(
root="./data",
background=True,
transform=transforms.Compose(
[
transforms.Grayscale(num_output_channels=3),
transforms.RandomResizedCrop(image_size),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
]
),
download=True,
)
test_set = Omniglot(
root="./data",
background=False,
transform=transforms.Compose(
[
# Omniglot images have 1 channel, but our model will expect 3-channel images
transforms.Grayscale(num_output_channels=3),
transforms.Resize([int(image_size * 1.15), int(image_size * 1.15)]),
transforms.CenterCrop(image_size),
transforms.ToTensor(),
]
),
download=True,
)
Load Model
class PrototypicalNetworks(nn.Module):
def __init__(self, backbone:nn.Module):
super(PrototypicalNetworks, self).__init__()
self.backbone = backbone
def forward(
self,
support_images: torch.Tensor,
support_labels: torch.Tensor,
query_images: torch.Tensor,
) -> torch.Tensor:
# support / query set의 feature 추출
z_support = self.backbone.forward(support_images)
z_query = self.backbone.forward(query_images)
# support set을 통해 n-way의 n 값을 얻음
n_way = len(torch.unique(support_labels))
# Prototype i 는 label 값이 i 인 instance들의 feature의 평균
z_proto = torch.cat(
[
z_support[torch.nonzero(support_labels == label)].mean(0) for label in range(n_way)
]
)
# 프로토타입으로부터 query의 유클리디언 거리 계산
dists = torch.cdist(z_query, z_proto)
# distance를 classification score로
scores = -dists
return scoresconvolutional_network = resnet18(pretrained=True)
convolutional_network.fc = nn.Flatten()
print(convolutional_network)
model = PrototypicalNetworks(convolutional_network).cuda()
Dataloader
Pytorch dataloader는 support set인지 query set인지 고려하지 않고 batch 단위의 이미지를 반환할 것이다.
따라서 우리는 아래 2가지를 고려하여야 한다.
- 주어진 classes 수에 고르게 분포된 이미지가 필요
- support set과 query set으로 분리해야 함
1번을 만족시키기 위해 custom sampler를 구현한다.
- 데이터셋으로부터 n_way classes를 샘플링한다.
- 그 다음 각 class 별로 n_shot + n_query 이미지를 샘플링한다.
- (각 batch에 n_way * (n_shot + n_query) 이미지)
2번을 만족시키기 위해 custom collate function을 사용한다. 이 collate_fn으로 각 batch에 아래 5가지를 넣는다.
- support images
- support labels between 0 and n_way
- query images
- query labels between 0 and n_way
- a mapping of each label in range(n_way) to its ture class id (모델에 사용하지는 않고 그냥 파악용)
N_WAY = 5 # Number of classes in a task
N_SHOT = 5 # Number of images per class in the support set
N_QUERY = 10 # Number of images per class in the query set
N_EVALUATION_TASKS = 100
test_set.get_labels = lambda: [instance[1] for instance in test_set._flat_character_images]
test_sampler = TaskSampler(
test_set, n_way=N_WAY, n_shot=N_SHOT, n_query=N_QUERY, n_tasks=N_EVALUATION_TASKS
)
test_loader = DataLoader(
test_set,
batch_sampler=test_sampler,
num_workers=12,
pin_memory=True,
collate_fn=test_sampler.episodic_collate_fn
)
loader에서 example을 뽑아 확인해보면 아래와 같다.
(
example_support_images,
example_support_labels,
example_query_images,
example_query_labels,
example_class_ids,
) = next(iter(test_loader))
plot_images(example_support_images, "support_images", images_per_row=N_SHOT)
plot_images(example_query_images, "query_images", images_per_row=N_QUERY)

위 그림처럼 5개의 class에 대해서 5개의 example들을 가지고도 아래처럼 성능을 낼 수 있다.
def evaluate_on_one_task(
support_images: torch.Tensor,
support_labels: torch.Tensor,
query_images: torch.Tensor,
query_labels: torch.Tensor,
) -> [int, int]:
return (
torch.max(
model(support_images.cuda(), support_labels.cuda(), query_images.cuda()).detach().data, 1
)[1] == query_labels.cuda()
).sum().item(), len(query_labels)
def evaluate(data_loader: DataLoader):
total_predictions = 0
correct_predictions = 0
model.eval()
with torch.no_grad():
for episode_index, (
support_images,
support_labels,
query_images,
query_labels,
class_ids,
) in tqdm(enumerate(data_loader), total=len(data_loader)):
correct, total = evaluate_on_one_task(
support_images, support_labels, query_images, query_labels
)
total_predictions += total
correct_predictions += correct
print(
f"Model tested on {len(data_loader)} tasks. Accuracy: {(100 * correct_predictions/total_predictions):.2f}%"
)
evaluate(test_loader)100%|██████████| 100/100 [00:06<00:00, 15.41it/s]
Model tested on 100 tasks. Accuracy: 86.38%
Omniglot 이미지를 가지고 하나도 훈련하지 않고 각 클래스 별 5개의 example을 가지고 few-shot learning을 했을 때 86%의 Accuracy를 달성하였다.
Train with a meta-learning algorithm
meta-learning 알고리즘을 이용해 학습시킨다면 성능은 더 높아진다.
N_TRAINING_EPISODES = 40000
N_VALIDATION_TASKS = 100
train_set.get_labels = lambda: [instance[1] for instance in train_set._flat_character_images]
train_sampler = TaskSampler(
train_set, n_way=N_WAY, n_shot=N_SHOT, n_query=N_QUERY, n_tasks=N_TRAINING_EPISODES
)
train_loader = DataLoader(
train_set,
batch_sampler=train_sampler,
num_workers=12,
pin_memory=True,
collate_fn=train_sampler.episodic_collate_fn
)criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
def fit(
support_images: torch.Tensor,
support_labels: torch.Tensor,
query_images: torch.Tensor,
query_labels: torch.Tensor,
) -> float:
optimizer.zero_grad()
classification_scores = model(
support_images.cuda(), support_labels.cuda(), query_images.cuda()
)
loss = criterion(classification_scores, query_labels.cuda())
loss.backward()
optimizer.step()
return loss.item()log_update_frequency = 10
all_loss = []
model.train()
with tqdm(enumerate(train_loader), total=len(train_loader)) as tqdm_train:
for episode_index, (
support_images,
support_labels,
query_images,
query_labels,
_
) in tqdm_train:
loss_value = fit(support_images, support_labels, query_images, query_labels)
all_loss.append(loss_value)
if episode_index % log_update_frequency == 0:
tqdm_train.set_postfix(loss=sliding_average(all_loss, log_update_frequecy))100%|██████████| 40000/40000 [49:08<00:00, 13.57it/s, loss=0.373]
evaluate(test_loader)100%|██████████| 100/100 [00:05<00:00, 18.27it/s]
Model tested on 100 tasks. Accuracy: 97.14%
97.14%의 Accuracy가 나왔음을 확인할 수 있다.
Reference
- https://arxiv.org/abs/1703.05175
- https://github.com/sicara/easy-few-shot-learning/blob/master/easyfsl/samplers/task_sampler.py
728x90
Contents