부스트캠프 AI Tech 4기
[DL Basic] 3. CNN
- -
기본적인 CNN은 convolution layer와 pooling layer, fully connected layer로 이루어져 있다.
- Convolution / pooling layer : feature extraction
- Fully connected layer : decision making (classification)
내가 학습하고자하는 모델의 파라미터의 숫자가 늘어나면 늘어날수록 학습이 어렵고 generalization performance가 떨어지는 편이다.
앞단의 Convolution layer을 깊게 쌓으면서 파라미터의 수를 줄이고자하기 때문에 뒷단의 Fully connected layer을 최소화하는 추세이다.
Dense Layer가 일반적으로 훨씬 더 많은 파라미터를 갖게 되는 이유는 Convolution operator인 kernel은 모든 위치에 대해서 동일하게 적용되기 때문이다. (Convolution operator는 일종의 shared parameter)
모델의 파라미터를 계산하는 방법

파라미터는 convolution 연산을 하는 kernel에 dependent하고 padding과 stride와는 연관이 없다.
1X1 Convolution 을 사용하는 이유
- Dimension(Channel) Reduction
- Convolution layer을 깊게 쌓으면서 동시에 파라미터 숫자를 줄일 수 있다. (bottleneck architecture)

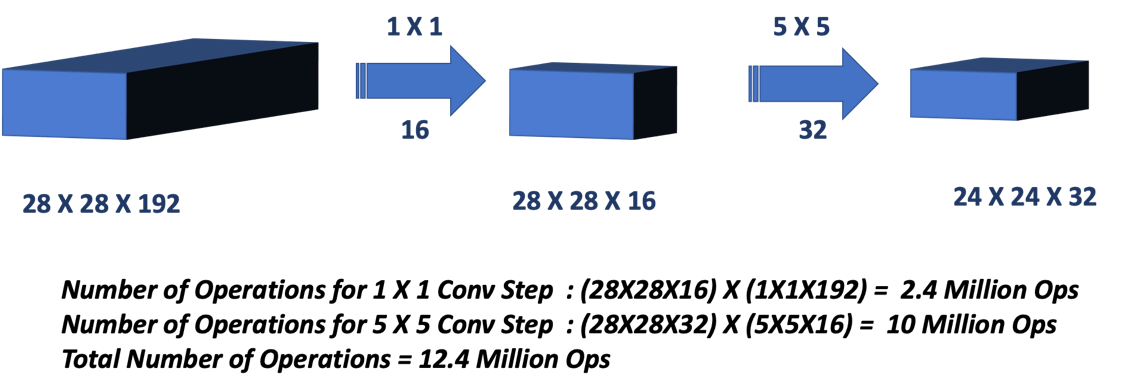
ILSVRC라는 Visual Recognition Challenge와 대회에서 수상을 했던
5개 Network 들의 주요 아이디어와 구조
▮ AlexNet

- 11X11X3 filters를 사용
→ 하나의 커널이 볼 수 있는 이미지 영역은 커지지만 상대적으로 더 많은 파라미터가 필요하는 문제 - activation function으로 ReLU activation을 사용
→ linear model의 좋은 성질인 activation 값이 커도 gradient를 그대로 갖는다.
→ gradient vanishing 문제 해결 - Data augmentation
- Dropout
▮ VGGNet

- 3x3 filter만을 사용하여 Receptive field는 유지하면서 더 적은 파라미터(weight)으로 더 깊은 네트워크를 구성

▮ GoogLeNet

- Inception blocks 을 제안
- 하나의 입력에 대해서 여러개의 receptive field를 갖는 filter를 거치고 여러개의 response들을 concat함을 통해 좀 더 다양한 종류의 특성이 도출된다.
- 각각의 path를 보게 되면 1x1 filter가 들어가 있다.
1x1 Convolution layer는 채널 방향으로 dimension reduction을 하는 효과가 있다.
→ 파라미터의 수를 줄이면서 네트워크 입력 출력의 receptive field와 channel은 같게 할 수 있다.
- 하나의 입력에 대해서 여러개의 receptive field를 갖는 filter를 거치고 여러개의 response들을 concat함을 통해 좀 더 다양한 종류의 특성이 도출된다.

앞선 3개의 네트워크를 비교해보면 네트워크는 점점 깊어지지만 파라미터의 수는 줄어들고 있다는 것을 확인할 수 있다.

▮ ResNet
앞서 네트워크가 깊을 수록 성능이 좋음을 알 수 있었다.
그러나 네트워크가 깊어질 수록 gradient vanishing 문제가 발생한다.
→ Residual connection(Skip connection)이라는 f(x) + x 구조를 제안
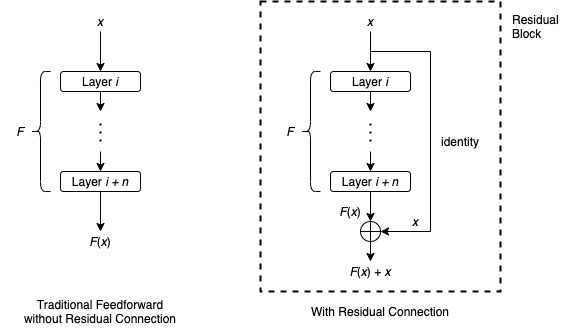
f(x) + x 의 구조를 부면 기존의 학습한 정보 x를 보존하면서 추가적으로 학습하는 정보 f(x)를 보내게 되는데
즉, 이전 레이어에서 학습했던 정보를 연결함으로써 해당 층에서는 추가적으로 학습해야할 정보만을 학습할 수 있게 된다.
따라서 전체를 학습하는 것보다 학습이 오히려 쉬워지고, Optimization을 더 잘 할 수 있게된다.
아래 그래프를 통해 Residual을 사용했을 때 더 많은 레이어를 쌓을수록 성능이 좋아짐을 확인할 수 있다.

- Bottleneck architecture
Googlenet의 Inception block과 동일하다.
3X3 filter 앞 뒤로 1x1 convolution filter을 통해 원하는 input channel의 차원을 맞추면서 파라미터는 줄일 수 있다.

▮ DenseNet

Resnet과 비슷한 아이디어지만 Addition이 아닌 Concatenation을 적용한 CNN이다.
문제는 concatenation을 하면 채널의 수가 기하급수적으로 커지게 된다.
채널이 커짐에 따라 파라미터의 수가 기하급수적으로 커지는 문제점이 발생한다.

Dense net은 Dense Block으로 feature map을 계속 키운다음에 Transition Block을 통해 BatchNorm→1X1 Conv을 통해 feature size를 줄이는 것을 반복한다.
부스트캠프 AI Tech 교육 자료를 참고하였습니다.
728x90
'부스트캠프 AI Tech 4기' 카테고리의 다른 글
| [DL Basic] 5. Transformer (2) | 2022.10.06 |
|---|---|
| [DL Basic] 4. Recurrent Neural Networks (0) | 2022.10.06 |
| [DL Basic] 2. Optimization (1) | 2022.10.04 |
| [DL Basic] 1. Neural Networks & Multi-Layer Perceptron (0) | 2022.10.03 |
| [WEEK02 마스터클래스] 최성철 마스터 (0) | 2022.09.30 |
Contents