부스트캠프 AI Tech 4기
[DL Basic] 4. Recurrent Neural Networks
- -
Sequential data는 길이가 정해져있지 않기 때문에 받아들여야할 차원을 알 수 없다.
Fully Connected Layer나 Convolution layer를 사용하기 어렵다.
Naive Sequential Model
- language model (이전 단어들을 가지고 다음 단어를 예측)
- 뒤로 갈수록 고려해야할 conditioning data가 많아지게된다.

$$p(x_{t}|x_{t-1},x_{t-2},...)$$
Autoregressive model
timespan을 fix하여 과거 데이터를 r개만 본다.
(과거 데이터를 1개만 볼 경우 AR1모델이라고 한다.)

$$p(x_{t}|x_{t-1}, ... , x_{t-r})$$
Markov model (first-order autogregressive model)
나의 현재는 나의 바로 전 과거에만 dependent하다고 가정한다.
joint distribution을 표현하기 쉽다는 장점이 있지만, 현실적으로는 말이 잘 안되는 모델이다.

$$p(x_{1}, ..., x_{r}) = p(x_{T}|x_{T-1})p(x_{T-1}|x_{T-2}) \ldots p(x_{2}|x_{1})p(x_{1}) = \prod_{t=1}^T p(x_{t}|x_{t-1}) $$
Latent autogregressive model
AR1 model이나 Markov model은 과거의 많은 정보를 고려해야할 상황에서도 그럴 수가 없다.
Latent autoregressive model은 중간에 hidden state가 들어가 있는데
이 hidden state가 과거의 정보를 요약하고 있다.
그리고 다음번 time-step은 이 hidden state 하나에만 dependent하게 된다.

$$ \hat{x} = p(x_{t}|h_{t}) $$
$$ h_{t} = g(h_{t-1}, x_{t-1}) $$
Recurrent Neural Network


RNN의 문제점 : Long-trem dependencies
RNN 자체는 과거의 먼 정보가 미래 time-step까지 살아남기가 어렵다.

아래 식과 같이 $h_{0}$에서부터 $h_{4}$까지 가는 동안 똑같은 weight와 activation function($ \phi $)을 거치게 된다.
activation function이 sigmoid/tanh라고 가정해보면 0~1사이의 값으로 줄어들고(정보를 줄이는 것) 이를 계속 반복해서 거치면 vanishing gradient가 발생하게 된다.
activation function이 ReLU이고 h값이 양수라면 계속 W값이 곱해지면서 exploding gradient 문제가 발생한다.

LSTM (Long Short Term Memory)

들어오는 입력도 3개, 나가는 것도 3개, 그러나 실제로 출력되는 것은 $h_{t}$ 하나이다.

Previous cell state : 내부에서만 흘러가고 time-step t까지의 정보를 다 취합해서 summarize해주는 역할
Core Idea

Cell state에서 다음 time-step으로 넘겨줄 때
어떤 정보가 유용하고 어떤 정보가 유용하지 않은지를 잘 조작하여 정보를 취합해서 summarize하는 과정을 거치게 된다.
이런 조작들을 gate에서 수행하게 된다.
Forget Gate

어떤 정보를 버릴지 판단한다.
현재 입력 $x_{t}$와 이전의 output $h_{t-1}$이 Sigmoid에 들어가서 $f_{t}$ 는 항상 0~1사이의 값을 갖게된다.
$f_{t}$는 이전의 cell state에서 나오는 정보 중에 어떤 것을 버리고 어떤것을 버릴지 선택하게 된다.
Input Gate
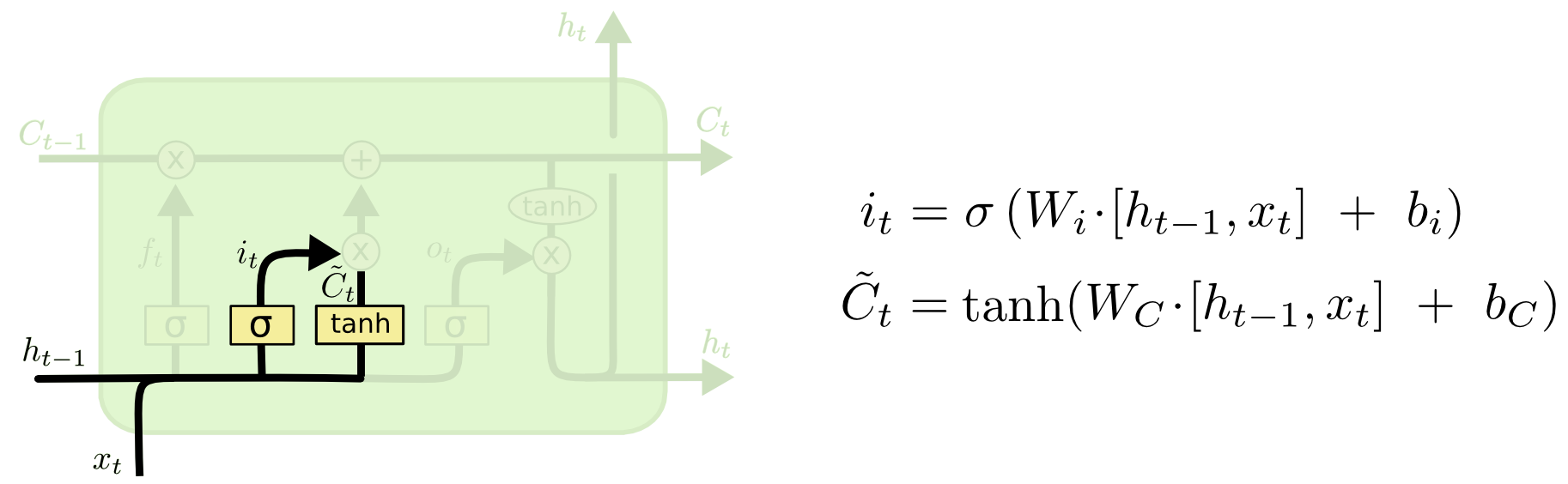
현재 입력이 들어왔을 때 이 정보중에 어떤 정보를 올릴지 말지를 정한다.
$i_{t}$는 이전의 prev hidden state와 현재 입력 $x_{t}$를 가지고 만들어지는데, 어떤 정보를 cell state에 추가할지 말지에 대한 정보를 갖고 있다.
$ \tilde{C}_{t} $ 도 이전의 prev hidden state와 현재 입력 $x_{t}$이 들어와서 따로 학습되는 neural network를 통해서 tanh를 통과해서 나오는 모든 값이 -1~1로 정규화 되어 있는 예비 Cell State이라고 볼 수 있다.
이전의 Cell State와 현재 정보와 이전 output으로 만들어진 $ \tilde{C}_{t} $을 잘 섞어서 Cell State를 update해주면 된다.

$i_{t}$와 forget gate에서 나온 것을 곱해서 버릴것은 버리고
$ \tilde{C}_{t} $에 $i_{t}$를 곱해서 올릴 값은 올리고
이 둘을 합쳐서 새로운 Cell State를 Update하게 된다.
Output Gate

어떤 값을 밖으로 내보낼지를 정하는 역할이다.
Gated Recurrent Unit

- 2개의 gate만 있다.
Reset gate, Update gate - Cell State가 없고 Hidden State만 있다.
- LSTM에 비슷하며 단순해진 모델
네트워크 파라미터가 적은데 적은 파라미터로 좋은 output을 내면 generalization 성능이 좋기 때문에
여러 Task에서 LSTM보다 GRU를 사용할 때 성능이 높아지는 경우를 종종 본다. - 하지만 최근엔 이 모든 것들이 Transformer로 대체되었다.
728x90
'부스트캠프 AI Tech 4기' 카테고리의 다른 글
| [DL Basic] 6. Genrative Model (0) | 2022.10.06 |
|---|---|
| [DL Basic] 5. Transformer (2) | 2022.10.06 |
| [DL Basic] 3. CNN (1) | 2022.10.05 |
| [DL Basic] 2. Optimization (1) | 2022.10.04 |
| [DL Basic] 1. Neural Networks & Multi-Layer Perceptron (0) | 2022.10.03 |
Contents