Interview
Sigmoid 보다 ReLU를 많이 사용하는데 그 이유는?
- -

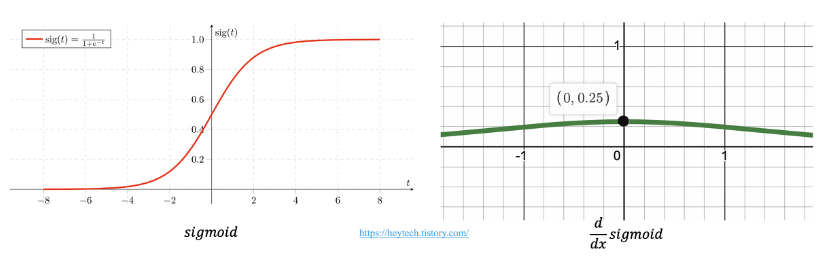
Sigmoid보다 ReLU를 많이 사용하는 이유는 기울기 소실 문제(Gradient Vanishing Problem) 때문입니다.
Gradient는 Chain Rule에 의해 미분값을 연쇄적으로 곱해주는데, Sigmoid의 경우 기울기가 항상 0과 1사이 값이므로 계속 곱해주게 되면 0으로 수렴할 수 밖에 없습니다.

ReLU는 음수일 때는 기울기가 0이고 양수일 때는 1이므로 backpropagation 과정에서 기울기가 소실되는 문제를 막을 수 있습니다.
(음수일 때는 기울기가 0이여서 Dying ReLU 문제가 존재 → Leaky ReLU)
또한 ReLU 함수는 Sigmoid처럼 특별한 연산이 필요하지 않기 때문에 연산 속도가 빠르다는 장점을 갖고 있습니다.
728x90
'Interview' 카테고리의 다른 글
| 앙상블 방법에는 어떤 것들이 있나요? (0) | 2022.11.26 |
|---|---|
| ReLU로 어떻게 곡선 함수를 근사하나요? ❓ (0) | 2022.11.25 |
| K-means의 대표적 의미론적 단점은 무엇인가요? (계산량 많다는것 제외) (0) | 2022.11.22 |
| 좋은 모델의 정의는 무엇일까요? (0) | 2022.11.22 |
| ROC 커브에 대해 설명해주세요 (0) | 2022.11.21 |
Contents