딥러닝/자연어 처리
[Vector Similarity Search] FAISS
- -
FAISS = Facebook AI Similarity Search
유사한 벡터를 검색해서 가져오는 Facebook 라이브러리 이다.
벡터화된 데이터를 인덱싱하고 이를 효율적으로 검색할 수 있도록 도와주는 C++ 기반 라이브러리이다.
라이브러리를 사용해보기 위해 해당 링크에서 sentence embedding 파일을 다운받았다.
import os
import numpy as np
import faiss
import requests
from io import StringIO
import pandas as pd
# download sentence embedding files
os.mkdir("./data")
data_url = "https://raw.githubusercontent.com/jamescalam/data/main/sentence_embeddings_15K/"
for i in range(57):
res = requests.get(data_url + f"embeddings_{i}.npy")
with open(f"./data/embeddings_{i}.npy", "wb") as f:
for chunk in res:
f.write(chunk)
print(".", end="")# load sentence_embeddings
for i in range(57):
if i == 0:
with open(f"./data/embeddings_{i}.npy", "rb") as f:
sentence_embeddings = np.load(f)
else:
with open(f"./data/embeddings_{i}.npy", "rb") as f:
sentence_embeddings = np.append(sentence_embeddings, np.load(f), axis=0)sentence_embeddings.shape(14504, 768)
그리고 임베딩한 원 문장도 확인을 위해 로드한다.
# download sentence file
data_url = "https://raw.githubusercontent.com/jamescalam/data/main/sentence_embeddings_15K/sentences.txt"
res = requests.get(data_url)
with open(f"./data/sentence.txt", "wb") as f:
for chunk in res:
f.write(chunk)
with open("./data/sentence.txt", "r") as f:
lines = f.read().split("\n")
IndexFlatL2
Faiss 라이브러리에는 여러가지 index 종류들이 존재한다.
그 중 하나인 IndexFlatL2는 brute-force L2 Distance 검색을 하는 알고리즘을 사용하는 인덱싱 방법이다.
대부분의 index들은 index를 구성하는 벡터들의 분포를 분석해야하기 때문에 train 단계가 필요하지만 IndexFlatL2는 train 단계가 필요하지 않다.
1. IndexFlatL2 함수를 호출하고 벡터의 차원을 입력
d = sentence_embeddings.shape[1]
index = faiss.IndexFlatL2(d)
+ IndexFlatL2는 훈련할 필요가 없다.
index.is_trainedTrue
2. 정의한 faiss의 index 객체에 add 함수로 벡터의 값을 넣어준다.
index.add(sentence_embeddings)index.ntotal14504
3. 유사한 문장을 search 해본다.
# 유사 문장 벡터화
x_q = model.encode(["someone sprints with a football"])# 유사한 문장 찾기
%%time
D, I = index.search(x_q, 5)
print(I)[[ 4586 10252 12465 190 399]]
CPU times: user 11.6 ms, sys: 555 µs, total: 12.1 ms
Wall time: 28 ms
# 찾은 index의 문장 확인
[f'{i} : {lines[i]}' for i in I[0]]['4586 : A group of football players is running in the field',
'10252 : A group of people playing football is running in the field',
'12465 : Two groups of people are playing football',
'190 : A person playing football is running past an official carrying a football',
'399 : A football player kicks the ball.']
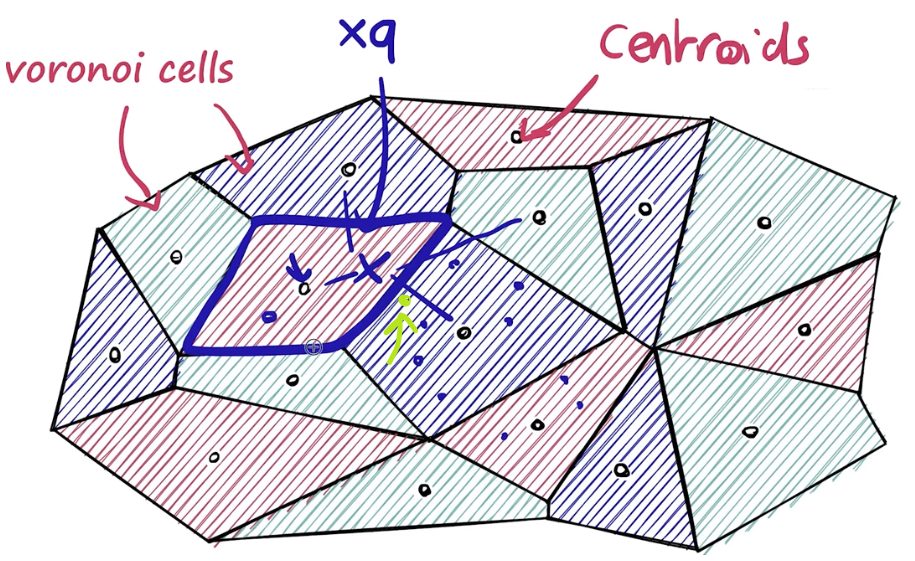
Voronoi cells
Faiss는 Search Efficiency를 위해 index를 Voronoi cells로 분할하여 접근할 수 있다.
d 차원 공간에서 Voronoi cells를 정의하고 각 cell 마다 벡터들을 저장한다.

query 벡터 $x_q$에 가까운 centroid를 찾고
탐색 범위를 $x_q$에 가까운 centroid를 갖는 Voronoi cell 영역으로 제한한다.

연두색 부분의 Sentence가 실제로는 아래 그림에서 제한한 Voronoi cell 안에 있는 Sentence보다 query와 유사할 수도 있지만, 위 영역으로 제한했기 때문에 연두색 Sentence는 탐색 대상에서 제외한다.
그렇기 때문에 Approximate Search라고 한다.
IndexIVFFlat
위에서 설명한 Voronoi cell을 활용하려면 IndexIVFFlat을 사용하면 된다.
IndexIVFFlat 은 벡터들을 Voronoi cell에 할당하기 위해 다른 index를 필요로 한다. (quantizer)
아래 코드에서는 처음에 사용해보았던 IndexFlatL2를 quantizer로 사용하였다.
nlist = 50 # partition 개수 지정
quantizer = faiss.IndexFlatL2(d)
index = faiss.IndexIVFFlat(quantizer, d, nlist)
IndexIVFFlat은 train이 필요한 index type이다.
index.is_trainedFalse
따라서 임베딩을 집어넣어 train 한다.
index.train(sentence_embeddings)index.is_trainedTrue
그 다음 sentence embedding을 add한다.
index.add(sentence_embeddings)
문장 $x_q$와 유사한 문장의 index를 search 한다.
%%time
D, I = index.search(x_q, 5)
print(I)[[ 4586 10252 12465 190 399]]
CPU times: user 496 µs, sys: 567 µs, total: 1.06 ms
Wall time: 2.37 ms
아까 brute force로 search 했을 때는 28ms였는데 Voronoi Cell 방식을 사용하니 2.37ms가 소요되었음을 확인할 수 있다.
[f'{i} : {lines[i]}' for i in I[0]]['4586 : A group of football players is running in the field',
'10252 : A group of people playing football is running in the field',
'12465 : Two groups of people are playing football',
'190 : A person playing football is running past an official carrying a football',
'399 : A football player kicks the ball.']
nprobe args의 값을 증가시키면 탐색하는 cell의 수를 증가시킬 수 있다.
nprobe = 4로 설정한다면 아래와 같이 4개의 cell을 탐색한다.
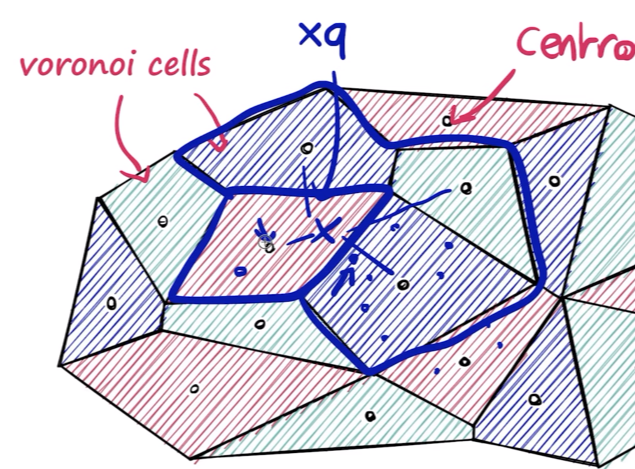
cell 수를 늘리면 당연히 시간이 더 걸림을 확인할 수 있다.
index.nprobe = 10
%%time
D, I = index.search(x_q, 5)
print(I)[[ 4586 10252 12465 190 399]]
CPU times: user 4.45 ms, sys: 148 µs, total: 4.6 ms
Wall time: 16.1 ms
Product Quantization

위 그림처럼 원본 데이터를 균등하게 subvector로 분할한다. (위 그림에서는 8개로 분할)
분할한 subvector들을 k-menas 알고리즘을 이용해 클러스터링하고 각 서브 샘플들을 클러스터의 centroid index로 매핑한다.
그러면 하나의 샘플은 정수형 index를 갖는 8차원 정수 벡터가 생성된다.
1024차원 float 형 벡터가 최종적으로 8차원 정수형 벡터로 변환되어 메모리 사용량을 줄일 수 있고 approximation을 통해 연산 속도가 향상된다.
축소된 데이터는 hemming distance를 통해 유사성을 판별한다.
일반적으로는 euclidean distance나 cosine similarity 등을 이용하지만 PQ의 축소된 값은 centroid의 index로 이루어져있기 때문에 edit distance의 한 종류인 hemming distance를 사용한다.
위 그림에서 모든 샘플들은 8차원의 정수 벡터로 표현되는데, 두 샘플 간의 유사도는 8개의 정수 중 몇 개가 틀리느냐를 계산한 값이다. 따라서 8개 값이 모두 다르다면 distance 값은 8이고 모두 같으면 0이 된다.
m = 8 # vector compressed할 centroid 수
bits = 8 # 각 centroid의 bit 수
quantizer = faiss.IndexFlatL2(d)
index = faiss.IndexIVFPQ(quantizer, d, nlist, m, bits)
IndexIVFPQ도 train이 필요한 index type이다.
index.is_trainedFalse
index.train(sentence_embeddings)
index.is_trainedTrue
index.add(sentence_embeddings)
%%time
D, I = index.search(x_q, 5)
print(I)[[ 190 399 8328 12465 10562]]
CPU times: user 281 µs, sys: 1.08 ms, total: 1.36 ms
Wall time: 993 µs
Reference
- https://www.youtube.com/watch?v=sKyvsdEv6rk&list=PLIUOU7oqGTLhlWpTz4NnuT3FekouIVlqc&index=3
- https://github.com/facebookresearch/faiss/wiki/Faster-search
- https://brunch.co.kr/@jejugrapher/271
728x90
'딥러닝 > 자연어 처리' 카테고리의 다른 글
Contents